他们之间是存在数学关系的,举个例子,假如一共有2000个样本,我设置batch_size为100,那么将所有样本训练完成1次的话,iteration就是2000/100=20个,这样就很清晰了。
通常情况下,batch_size和epoch作为超参,需要自己设定。但要明确,只有在数据很庞大的时候(在机器学习和神经网络中,数据一般情况下都会很大),我们才需要使用epoch,batch size,iteration这些术语,在这种情况下,一次性将数据输入计算机是不可能的。因此,为了解决这个问题,我们需要把数据分成小块,一块一块的传递给计算机,在每一步的末端更新神经网络的权重,拟合给定的数据。那么问题就来了:
设置batch_size是会影响到我们模型的优化速度和程度的,它是在寻找一种内存效率和内存容量之间的平衡,是很重要的。那么batch_size设置为多少比较合适呢,准确的说,没有一个标准答案,需要根据自己的数据量大小来定。
适当的增加batch_size有以下的优势:
1.通过并行化提高内存利用率。
2.单次epoch的迭代次数减少,提高运行速度。
3.适当的增加Batch_Size,梯度下降方向准确度增加,训练震动的幅度减小。
但也要清楚地认识到:相对于正常数据集,如果batch_size过小,训练数据就会非常难收敛,从而导致underfitting。增大batch_size,相对处理速度加快。增大batch_size, 所需内存容量增加(epoch的次数需要增加以达到最好的结果)
所以发现没有,上面两个是互相矛盾的问题,因为当epoch增加以后同样也会导致耗时增加从而速度下降。因此我们需要寻找最适合的batch_size。
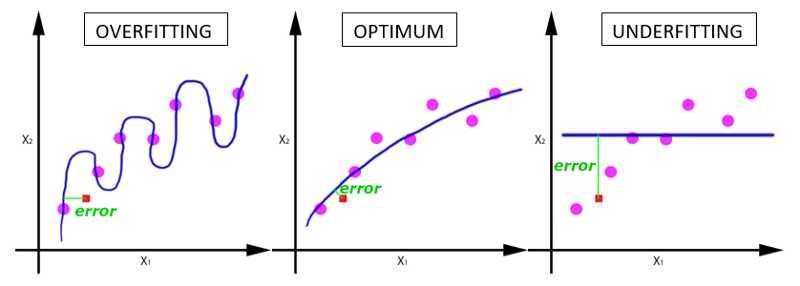
我们跑完所有的样本确实只需要1个epoch,但是这样训练的得到的模型,它的参数却不够好,我们需要把完整的数据样本在同样的网络中跑多次(每一次的参数是不一样的哦),以使得我们的参数最优化,从而损失函数最小。随着epoch数量增加,神经网络中的权重的更新次数也在增加,曲线也从欠拟合变得过拟合,所以合适的epoch次数也是一个重要的参数。
神经网络中的epoch、batch_size和iteration
原文:https://www.cnblogs.com/wsjgdxx/p/11962643.html