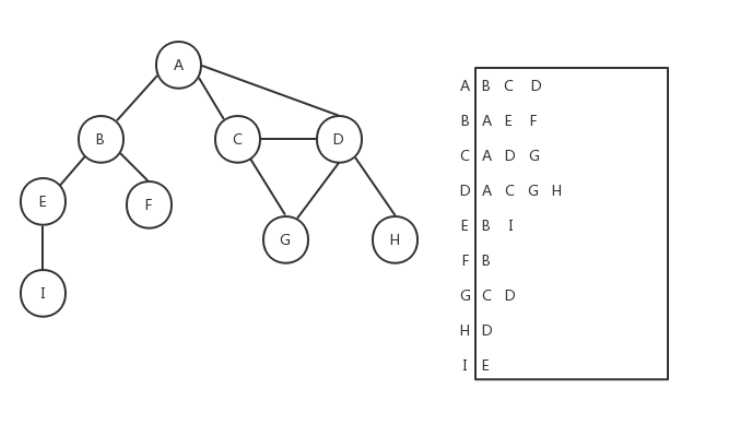
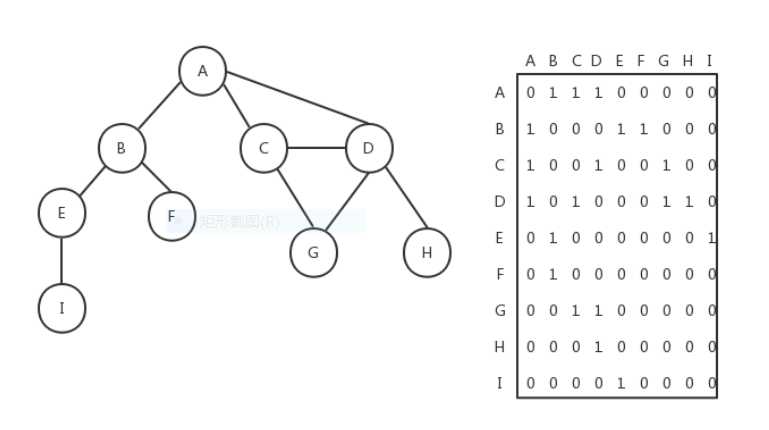
图的遍历:图的遍历较为复杂,分为广度优先遍历与深度优先遍历。
(1)广度优先遍历:广度优先遍历要用到队列知识存放结点和MashMap来确定是否访问过此结点,
将起始点存入队列中,将其标记为以访问存入MashMap中。在将结点从队里取出,搜索该结点所连接的结点,将他们存入队中,设为以访问。再将他们依此取出进行上述操作,直到队列里没有需要操作的数字。
图的连接性:图得连接性可通过遍历来体现,如果图是全部连接起来的,那无论通过哪个节点进行遍历,遍历结点的结果都是一样的。如果不连通,那必定有一个结点的遍历结果为1。
Kruscal算法:该算法将所有点先画出,再将权值最小的两个结点连接起来。注意避开回路
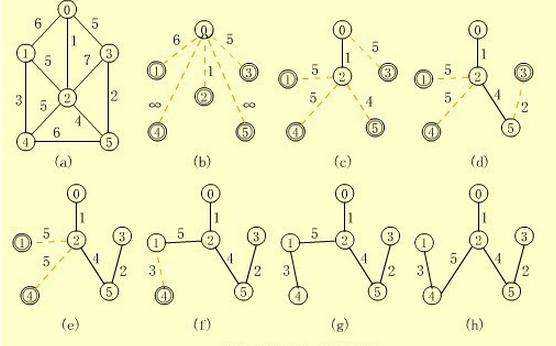
Prim算法:随机选一个顶点,将顶点周围权值最小的边连起来,将连好的作为一个整体,在余下部分找权值最小的边。连起来。
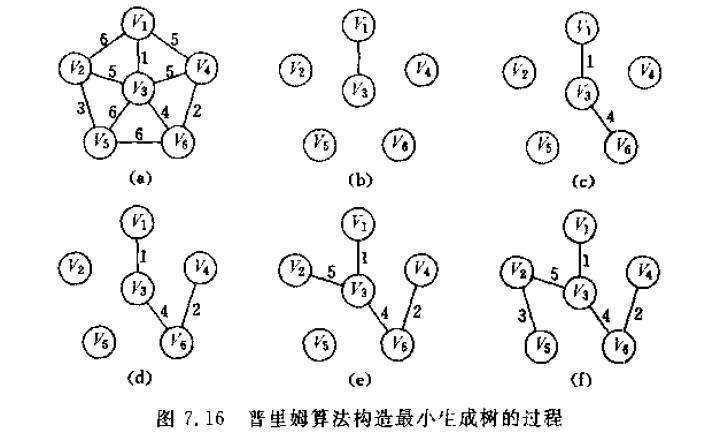
二者的区别就是先写边还是先写点,并且注意要将已经写好的放在一起比较。
public void enqueue(T element)
{
LinearNode<T> node = new LinearNode<T>(element);
if (isEmpty())
head = node;
else
tail = node;
count++;
}
tail.setNext(node);才可正常运行。
逻辑实现:首先是把源节点放到栈里和set里,并打印,然后弹出源节点,如果遍历源节点的所有next节点,如果当前next节点没有加入到set里,那么把源节点重新加入到栈里,这个 *next加入到栈里,并加入set集合中,打印该next,并跳出循环,把当前next变为当前节点(也就是栈顶元素),重复上面的操作,就会的得到一个深度优先遍历的序列 。

无
正确使用Markdown语法加1分:
模板中的要素齐全加1分
教材学习中的问题和解决过程, (加4分)
代码调试中的问题和解决过程, (加2分)
周五前发博客的加1分
进度条中记录学习时间与改进情况的加1分
错题学习深入的加1分
感想,体会不假大空的加1分
图的学习更加困难,主要是在遍历上,书上的代码繁多复杂,猛地看看不大懂,但如果实现理解其思路,带着自己的想法去看代码,就会事半功倍。
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 | |
| 第五周 | 500/1000 | 3/7 | 22/60 | |
| 第六周 | 700/1300 | 2/9 | 22/90 | |
| 第七周 | 1300/1000 | 3/7 | 30/60 | |
| 第八周 | 1200/1500 | 3/7 | 30/60 | |
| 第九周 | 1000/1500 | 3/7 | 30/60 | |
| 第十周 | 1000/1500 | 3/7 | 32/40 |
计划学习时间:40时
实际学习时间:32
原文:https://www.cnblogs.com/zjwbk/p/11964249.html