RNN,中文’循环神经网络‘,解决的是时间序列问题。什么是时间序列问题呢,就是我们的样本数据之间在时间维度上存在关联的,跟一般的神经网络不一样,也就是说我们前一个输入和后一个输入有某种说不清道不明的关系,需要RNN这种特定结构的神经网络去寻找内部联系。
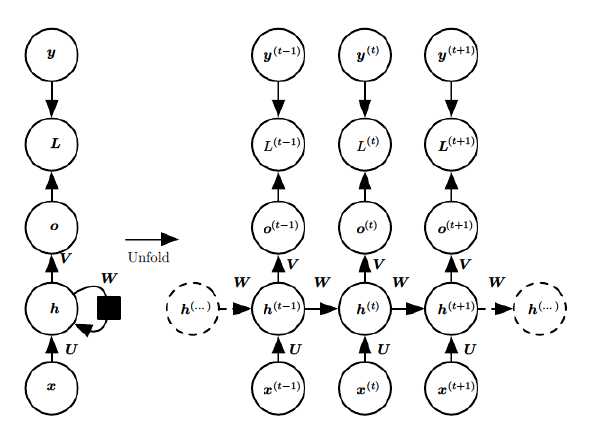
下面是RNN的一个基本结构和一个官网结构,第一个图里左边是未展开的形式,右边是展开的形式 ,将每一个时刻T=t的过程统统列举出来,它们共享参数W、U、V,最终的损失是每一个时刻的损失累加
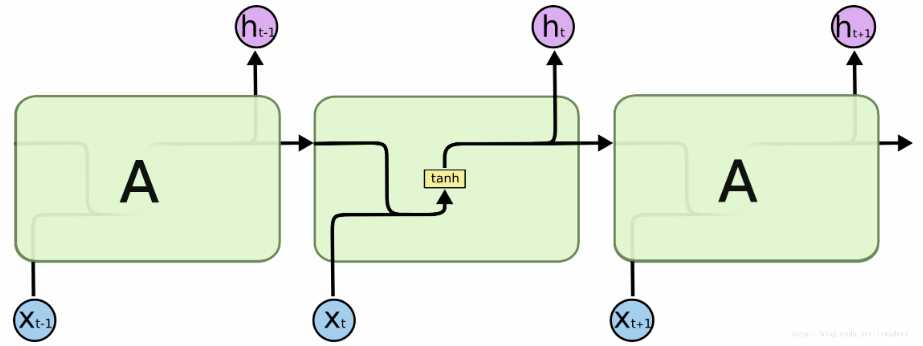
对于时刻t,存在:
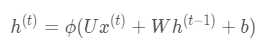 ,
,
其中?为激活函数,一般来说会选择tanh函数,b为偏置,而t时刻的输出O为:
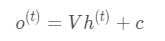
输出的预测值y_hat为:
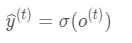
σ为激活函数,通常RNN用于分类,一般用softmax函数。
针对每个时刻经过这样的计算,我们就能得到每个时刻的y_hat和h_t,以及各自的损失,再通过累加每个时刻的损失值得到最终的损失,这样就算是一次前向传播结束了。
我们说模型的训练其实就是:将数据喂到模型里,找到一批参数使得损失函数最小的过程。那么最重要的就是这批参数的更新过程了,我们用的是梯度下降的过程来更新参数,本质就这一个公式,敲黑板啦!!W_new = W_old - a(dL/dw),其中W是我们的参数,a是学习率,L是损失函数。然而W和L是没有直接的关系的,但它们之间有间接的关系,L--->y_hat--->O_t--->h_t--->W,这样就有关系了,所以我们需要用到链式法则来求导。
一共有这个几个参数,W、U、V、b、c,那我们就以W为例手推一下反向传播的过程,假设我们一共有4个时刻,T=1、2、3、4。详细的看下面的图片

从上面的推导过程看,梯度消失和梯度爆炸主要是由长距离的累乘导致的,那么摆在我们面前的有两种解决方案:
理论上RNN是可以处理长期依赖问题的,但实际中并不是这样的。标准的RNN结构中只有一个神经元,一个tanh层进行重复的学习,这样会存在一些弊端。例如,我是陕西人,我在哪哪哪上的大学,那儿的天气很舒服,但我更喜欢xxx的肉夹馍,这个xxx明显是陕西,但它两距离太远了,可能学不到这些信息。
lstm是一种特殊的RNN,也可以说是一种优化后的RNN,一般在实际中,没有人会选择最原始的RNN,而是选择一些他的变种比如lstm和gru。lstm在每一个重复的模块中有四个特殊的结构,以一种特殊的方式进行交互。接下来我们逐一说明:
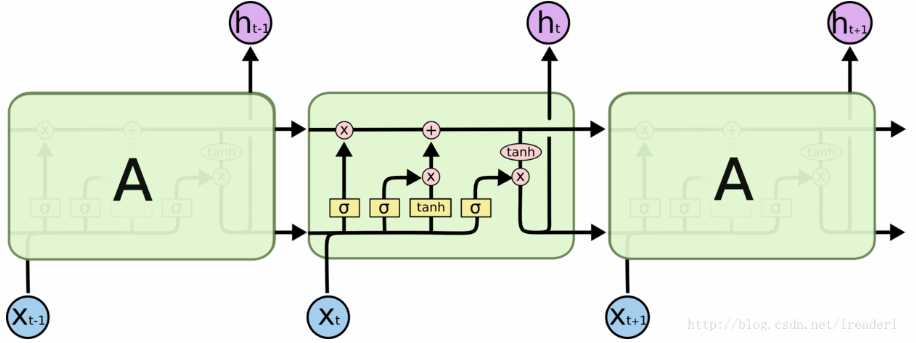
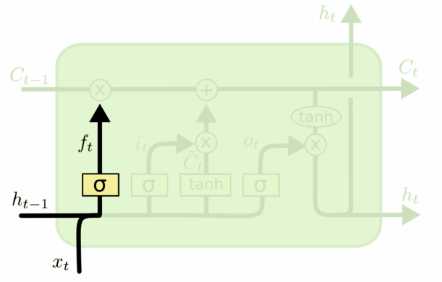
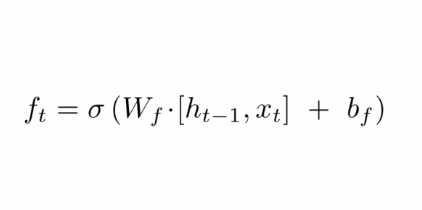
忘记门用来决定我们需要丢弃什么信息,需要使用到当前的输入x_t以及上一时刻的隐状态h_t-1,使用激活函数sigmoid来决定信息的输入,0代表完全丢弃,1代表完全通过。
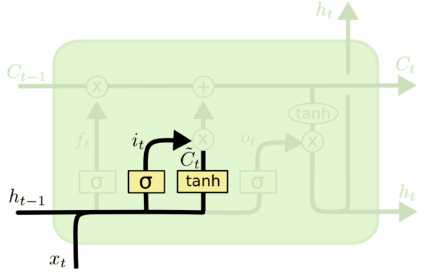
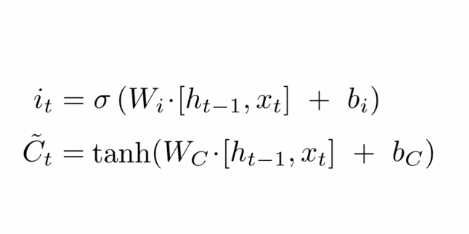
输入门就是简单的将当前时刻x_t和上一时刻的隐状态h_t-1拼接后,经过一个sigmoid激活函数;候选值是当前时刻x_t和上一时刻的隐状态h_t-1拼接后,经过一个tanh激活函数
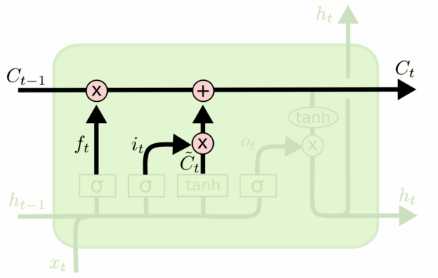
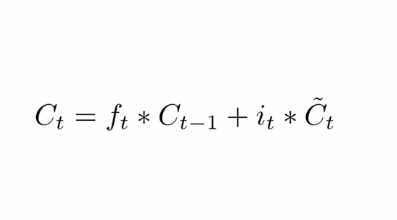
更新C_t的值,由C_t-1变为C_t
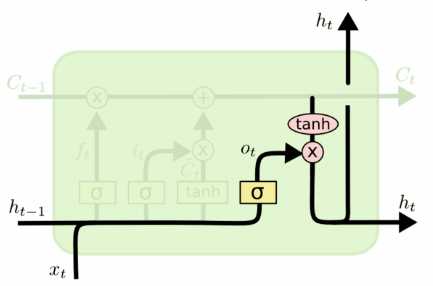
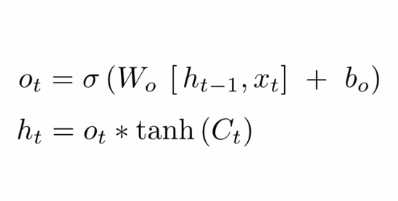
我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,经过一个tanh输出我们的h_t,最终的h_t和C_t会输入下一个神经元中。
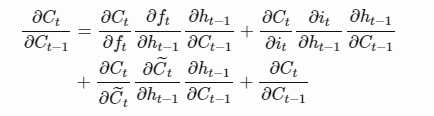
lstm反向传播过程中,上式这个是主要的连乘部分,和 RNN 最大的区别在于,每一步的结果是由加法得来的,那么就避免的深度的累乘了,也就不再有梯度爆炸和梯度消失了。
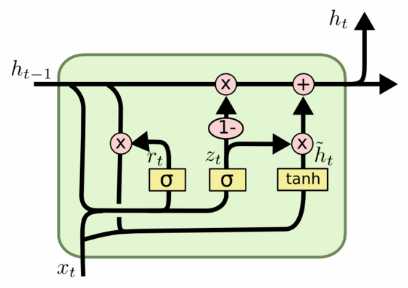
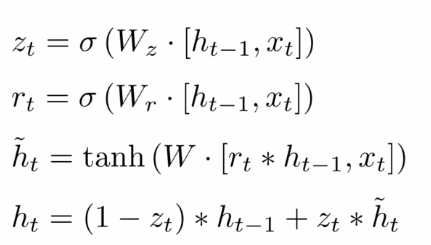
gru在lstm的基础上做了简化,将忘记门和输入门合成了一个单一的更新门,所以gru就只剩两个门更新门和充值门,同时gru还混合了细胞状态和隐藏状态。
原文:https://www.cnblogs.com/wsjgdxx/p/11967454.html