OPTICS是基于DBSCAN算法的缺陷提出来的一个算法。
核心思想:为每个数据对象计算出一个顺序值(ordering)。这些值代表了数据对象的基于密度的族结构,位于同一个族的数据对象具有相近的顺序值。根据这些顺序值将全体数据对象用一个图示的方式排列出来,根据排列的结果就可以得到不同层次的族。
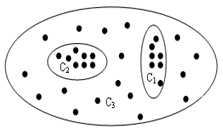
考察DBSCAN,可以发现,对一个恒定的MinPts值来说,?取值较小时得到的聚类结果完全包含在根据较大的?取值所获得的聚类结果中。
如图,当?取值较小时,得到的聚类结果是C1和C2,当?取值较大时,得到的聚类结果是C3。
可以看到,C1和C2是包含在C3中的。换句话说,C1、C2、C3间具有层次关系,C3可以看作是C1和C2的父亲,而C1和C2可以看作是C3的孩子。
因此,在生成族的时候,最好能够将位于不同层次上的族同时构建出来,而不是根据某个特定的?值仅仅构建其中的一层。
为了同时构建不同层次上的族,数据对象应当以特定的顺序来处理。这个顺序称为族序(cluster-ordering),它决定了对象扩展时的次序。
为了使较低层次上的族(这些族的数据密度较大)能够首先构建完成,在进行对象扩展时,应该优先选择那些根据最小的?取值而密度可达的对象。
基于这个思想,每个数据对象需要存储两个值,一个是核心距离(core-distance),另一个是可达距离(reach-distance)。
核心距离:给定一个数据对象集合D,两个参数?和MinPts,一个对象O,如果O是一个核心对象,则O的核心距离(core-dist)是使得O能成为核心对象的最小半径值(该值小于等于?)。如果O不是核心对象,则O的核心距离没有定义。
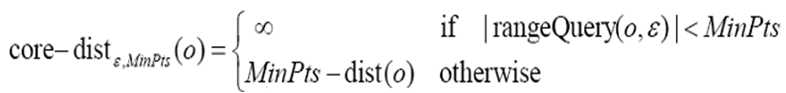
其中|rangeQuery(O, ?)|<MinPts表示在O的?-邻域的数据对象的个数小于MinPts个,说明在这种情况下O不是一个核心对象。
反之,当O是一个核心对象时,MinPts-dist(O)表示的就是使得O的?-邻域能够包含MinPts个数据对象的最小半径值。
例如,给定MinPts=5, 则??表示的半径就是对象O的核心距离
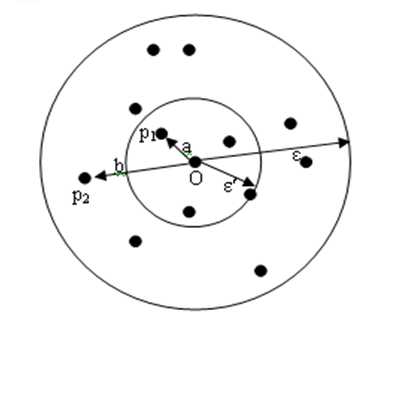
可达距离:给定一个数据对象集合D,两个参数?和MinPts,一个对象O,如果O是一个核心对象,则O与另一个对象p间的可达距离(reachbility-distance)是O的核心距离和O与p的欧几里得距离之间的较大值。如果O不是一个核心对象,O与p之间的可达距离没有定义。
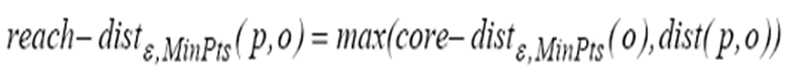
由于p1和O之间的距离a小于对象O的核心距离,即dist(p1, O) < core-dist(O),所以p1和O之间的可达距离就是对象O的核心距离。即reach-dist(p1, O) = core-dist(O)= ??。
由于p2和O之间的欧几里得距离b大于对象O的核心距离,即dist(p2, O) > core-dist(O),所以p2和O之间的可达距离就是p2和O之间的欧几里得距离。即reach-dist(p2, O) = dist(p2, O)。
OPTICS算法的工作过程
原文:https://www.cnblogs.com/hupc/p/11972659.html