
Kafka是一个分布式的、基于发布订阅的消息系统,主要解决应用解耦、异步消息、流量削峰等问题。
消息生产者将消息发布到Topic中,同时有多个消息消费者订阅该消息,消费者消费数据之后,并不会清除消息。属于一对多的模式,如图:
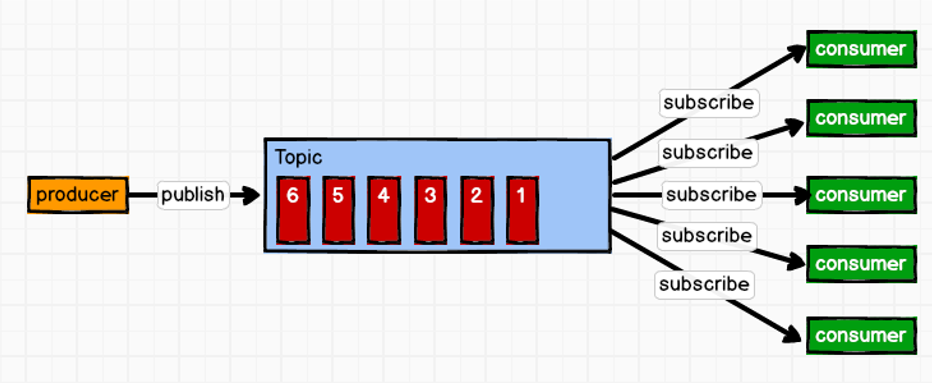
网上找了个不错的架构图:
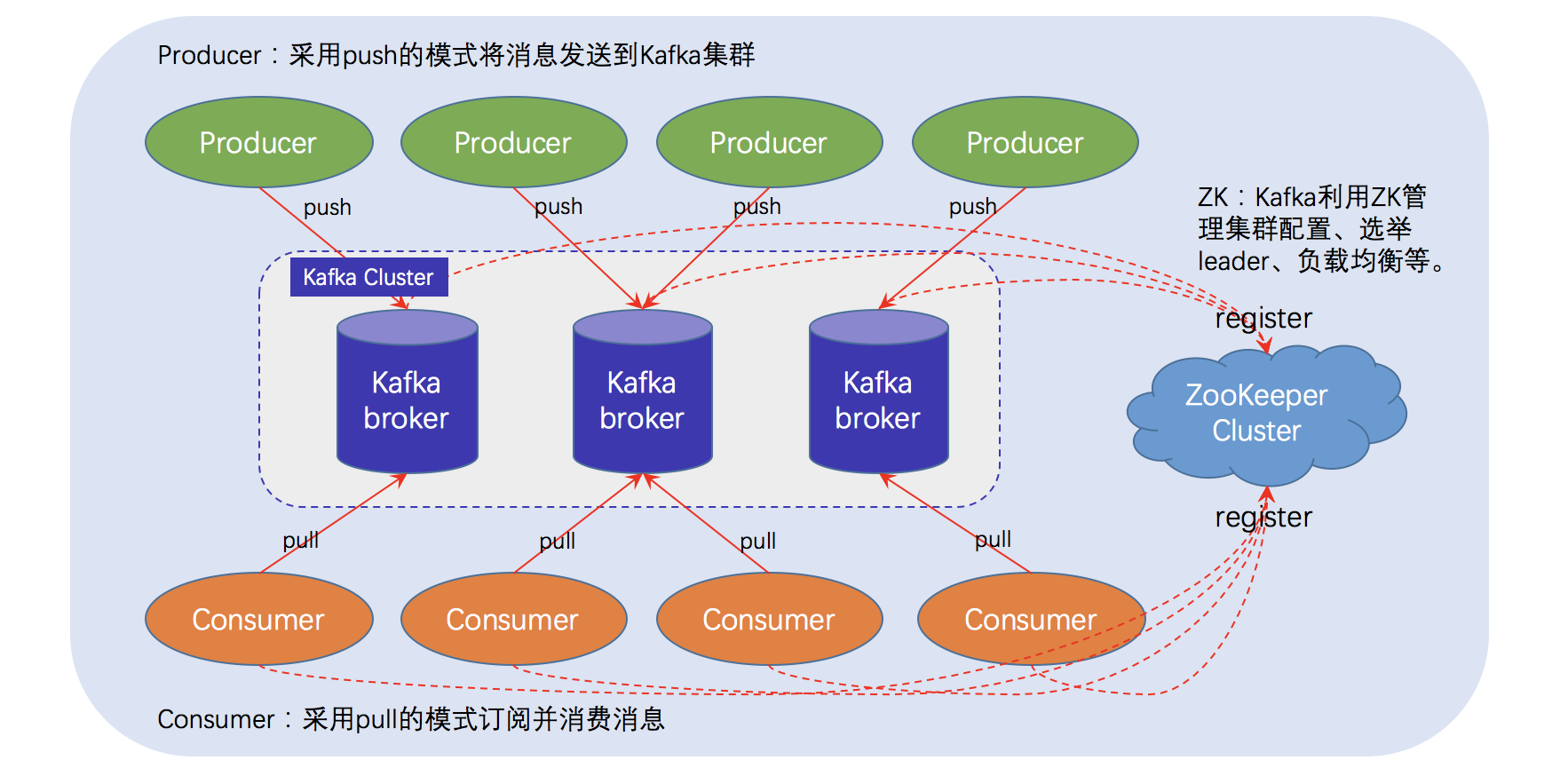
上图中标识了一个kafka体系架构包括若干Producer、Broker、Consumer和一个zookeeper集群。
再贴两张带有Topic和Partition的架构图:
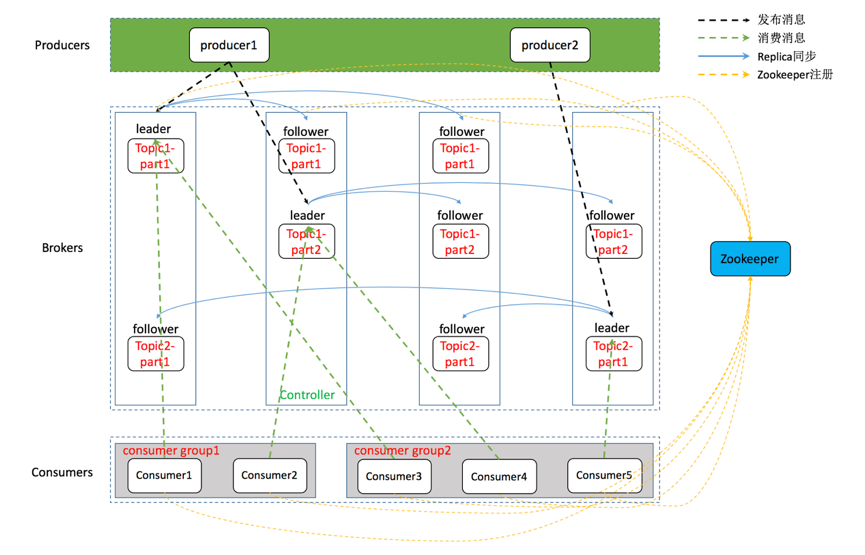
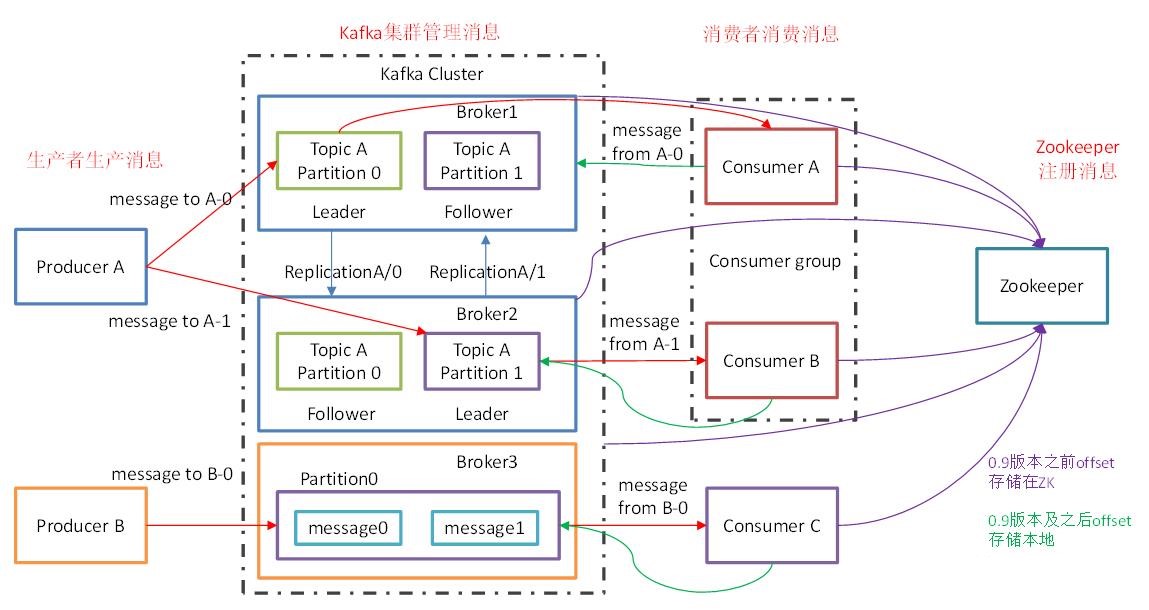
下面介绍一下各个角色:
消息生产者,将消息push到Kafka集群中的Broker。
消息消费者,从Kafka集群中pull消息,消费消息。
消费者组,由一到多个Consumer组成,每个Consumer都属于一个Consumer Group。消费者组在逻辑上是一个订阅者。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。
即每条消息只能被Consumer Group中的一个Consumer消费;但是可以被多个Consumer Group组消费。这样就实现了单播和多播。
一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,每个Broker可以容纳多个Topic.
消息的类别或者主题,逻辑上可以理解为队列。Producer只关注push消息到哪个Topic,Consumer只关注订阅了哪个Topic。
负载均衡与扩展性考虑,一个Topic可以分为多个Partition,物理存储在Kafka集群中的多个Broker上。可靠性上考虑,每个Partition都会有备份Replica。
Partition的副本,为了保证集群中的某个节点发生故障时,该节点上的Partition数据不会丢失,且Kafka仍能继续工作,所以Kafka提供了副本机制,一个Topic的每个Partition都有若干个副本,一个Leader和若干个Follower。
Replica的主角色,Producer与Consumer只跟Leader交互。
Replica的从角色,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会变成新的Leader。
Kafka集群中的其中一台服务器,用来进行Leader election以及各种Failover(故障转移)。
Kafka通过Zookeeper存储集群的meta等信息。
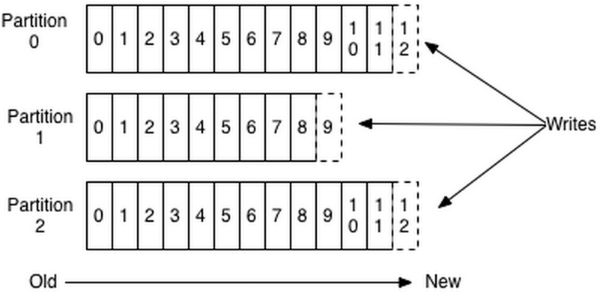
一个Topic可以认为是一类信息,逻辑上的队列,每条消息都要指定Topic。为了使得Kafka的吞吐量可以线性提高,物理上将Topic分成一个或多个Partition。每个Partition在存储层面时append log文件,消息push进来后,会被追加到log文件的尾部,每条消息在文件中的位置成为offset(偏移量),offset是一个long型数字,唯一的标识一条信息。因为每条消息都追加到Partition的尾部,所以属于磁盘的顺序写,效率很高。如图:
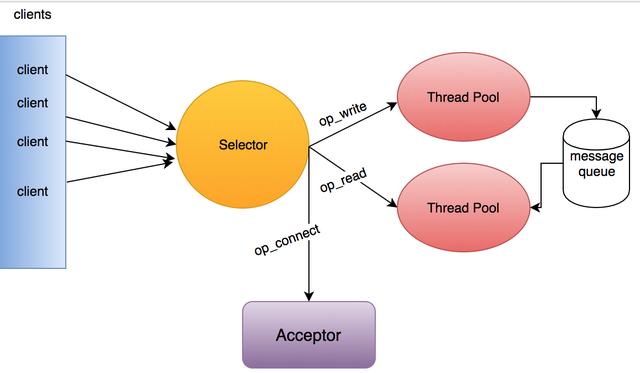
Kafka的网络模型基于Reactor模型,即响应模型。Kafka网络模型分为两部分:Kafka客户端即Consumer和Producer都是单线程的Reactor模型,Kafka服务端是多线程的Reactor模型。
如图:
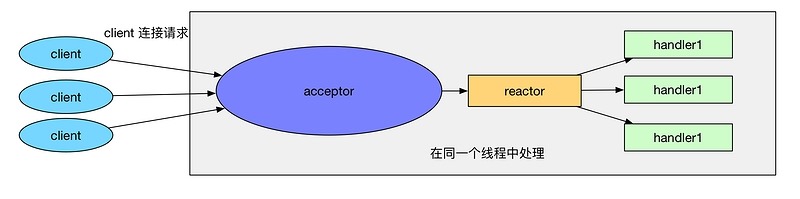
Reactor线程负责多路分离套接字,Accept新连接,并分派请求到Handler处理器。
以下来自;消息中间件—简谈Kafka中的NIO网络通信模型
如图:
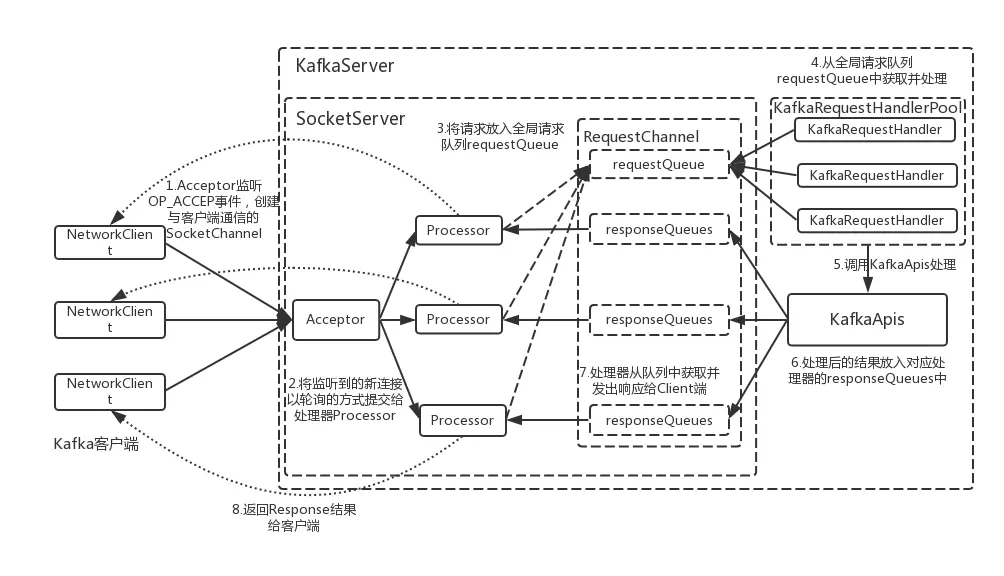
深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
kafka架构原理
阿里大牛实战归纳——Kafka架构原理
Kafka架构图
Kafka 设计解析(一):Kafka 背景及架构介绍
消息中间件—简谈Kafka中的NIO网络通信模型
Reactor模式

原文:https://www.cnblogs.com/clawhub/p/11973407.html