拜读了 胖哥的(el7+jewel)完整部署 受益匪浅,目前 CEPH 已经更新到 M 版本,配置方面或多或少都有了变动,本博文就做一个 ceph luminous 版本完整的配置安装。
提示:本文使用了大量的 ansible 命令,需有基础的 ansible 相关知识。
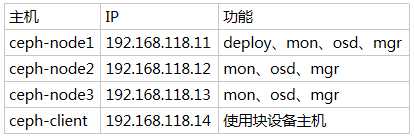
主机配置
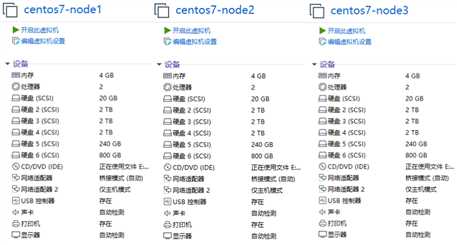
3 台装有 CentOS 7 的主机,每台主机有 5 块磁盘(虚拟机磁盘要大于30G),本次使用的是 Vmware Wrokstation ,创建虚拟机及安装操作系统不再描述。
每台主机配备 3 个 2T 硬盘,1 个 240G 硬盘 及 一个 800G 硬盘,其中 240G 硬盘假装是一个SSD,用来存储 RocksDB 的 block.wal 和 block.db 而 800G 的硬盘用作 OSD 的 SSD 。
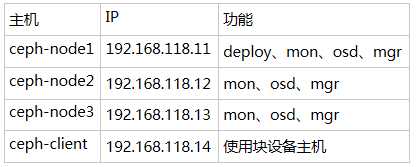
每台主机配备两张网卡,网卡1 - 连接公网, 网卡2 - 集群网络,禁止访问外网。
网卡1网络:192.168.118.0/24 网卡2网络:192.168.61.0/24
集群介绍
分为以下几个步骤:
(1)修改主机名并设置 ssh 互信访问;
(2)升级系统内核、关闭 Selinux 和 firewalld、修改系统文件句柄;
(3)配置 ntp 服务
修改主机名及设置ssh互信
修改主机名:
#hostnamectl set-hostname ceph-node1
#hostnamectl set-hostname ceph-node2
#hostnamectl set-hostname ceph-node3
#hostnamectl set-hostname ceph-client
#cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# 将如下内容添加到 /etc/hosts, 每台主机都需要添加
192.168.118.11 ceph-node1
192.168.118.12 ceph-node2
192.168.118.13 ceph-node3
192.168.118.14 ceph-client
在 ceph-deploy主机上设置互信访问:
[root@ceph-node1 ~]# ssh-keygen -t rsa -P ‘‘ # 一路回车
[root@ceph-node1 ~]# ssh-copy-id ceph-node1
[root@ceph-node1 ~]# ssh-copy-id ceph-node2
[root@ceph-node1 ~]# ssh-copy-id ceph-node3
配置 yum 并安装 ansible
#mkdir /tmp/bak ; mv /etc/yum.repos.d/* /tmp/bak -- 此命令在每台主机上执行,避免产生多余的yum配置文件
下载 163 镜像yum
#wget -O /etc/yum.repos.d/CentOS7-Base-163.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo
安装 ansible
#yum install ansible -y
将ceph 主机添加到ansible群组ceph里
[root@ceph-node1 ~]# cat /etc/ansible/hosts
[ceph]
ceph-node1 ansible_ssh_user=root
ceph-node2 ansible_ssh_user=root
ceph-node3 ansible_ssh_user=root
测试:
[root@ceph-node1 ~]# ansible ceph -m ping
ceph-node1 | SUCCESS => {
"changed": false,
"ping": "pong"
}
ceph-node3 | SUCCESS => {
"changed": false,
"ping": "pong"
}
ceph-node2 | SUCCESS => {
"changed": false,
"ping": "pong"
}
拷贝 hosts 文件到每台主机
[root@ceph-node1 ~]# ansible ceph -m copy -a ‘src=/etc/hosts dest=/etc/‘
注意:每台主机要修改对应的主机名
192.168.118.11 ceph-node1 192.168.118.12 ceph-node2 192.168.118.13 ceph-node3
升级系统内核、关闭 Selinux 和 firewalld、修改系统文件句柄
修改yum配置文件: [root@ceph-node1 ~]# ansible ceph -m get_url -a ‘url=http://mirrors.163.com/.help/CentOS7-Base-163.repo dest=/etc/yum.repos.d/‘ 升级系统程序包: [root@ceph-node1 ~]# ansible ceph -m yum -a ‘name=* state=latest‘ 升级内核: ansible ceph -m shell -a ‘rpm -ivhU http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm‘ 安装 kernel-lt(长期维护版本) [root@ceph-node1 ~]# ansible ceph -m yum -a ‘name=kernel-lt enablerepo="elrepo-kernel"‘ 查看当前系统内核包: [root@ceph-node1 ~]# ansible ceph -m shell -a ‘rpm -qa | egrep kernel‘ [WARNING]: Consider using yum, dnf or zypper module rather than running rpm ceph-node3 | SUCCESS | rc=0 >> kernel-3.10.0-1062.el7.x86_64 kernel-3.10.0-1062.4.3.el7.x86_64 kernel-tools-3.10.0-1062.4.3.el7.x86_64 kernel-lt-4.4.204-1.el7.elrepo.x86_64 kernel-tools-libs-3.10.0-1062.4.3.el7.x86_64 kernel-headers-3.10.0-1062.4.3.el7.x86_64 ceph-node2 | SUCCESS | rc=0 >> kernel-3.10.0-1062.el7.x86_64 kernel-3.10.0-1062.4.3.el7.x86_64 kernel-tools-3.10.0-1062.4.3.el7.x86_64 kernel-lt-4.4.204-1.el7.elrepo.x86_64 kernel-tools-libs-3.10.0-1062.4.3.el7.x86_64 kernel-headers-3.10.0-1062.4.3.el7.x86_64 ceph-node1 | SUCCESS | rc=0 >> kernel-3.10.0-1062.el7.x86_64 kernel-tools-3.10.0-1062.4.3.el7.x86_64 kernel-lt-4.4.204-1.el7.elrepo.x86_64 kernel-tools-libs-3.10.0-1062.4.3.el7.x86_64 kernel-3.10.0-1062.4.3.el7.x86_64 kernel-headers-3.10.0-1062.4.3.el7.x86_64
内核包安装成功,安装的包就是:kernel-lt-4.4.204-1.el7.elrepo.x86_64
修改grub 启动为最新的内核
[root@ceph-node1 ~]# ansible ceph -m replace -a ‘path=/etc/default/grub regexp="saved" replace=0‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘grub2-mkconfig -o /boot/grub2/grub.cfg‘
在重启之前记得修改 selinux 和 firewalld
[root@ceph-node1 ~]# ansible ceph -m selinux -a ‘conf=/etc/selinux/config state=disabled‘ [root@ceph-node1 ~]# ansible ceph -m systemd -a ‘name=firewalld enabled=no‘ 设置最大文件句柄: [root@ceph-node1 ~]# ansible ceph -m lineinfile -a ‘dest=/etc/security/limits.conf line="* soft nproc 65535\n* hard nproc 65535\n* soft nofile 65535\n* hard nofile 65535"‘ 设置开启执行: [root@ceph-node1 ~]# ansible ceph -m lineinfile -a ‘dest=/etc/rc.local line="ulimit -SHn 65535"‘ [root@ceph-node1 ~]# ansible ceph -m file -a ‘path=/etc/rc.d/rc.local mode=0744‘ 重启主机: [root@ceph-node1 ~]# ansible ceph -m shell -a ‘reboot -f‘
最后,配置 NTP服务
[root@ceph-node1 ~]# ansible ceph -m yum -a ‘name=ntp state=latest‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘sed -i "/^server/d" /etc/ntp.conf‘ [root@ceph-node1 ~]# ansible ceph -m lineinfile -a ‘dest=/etc/ntp.conf line="server tiger.sina.com.cn\nserver ntp1.aliyun.com"‘ [root@ceph-node1 ~]# ansible ceph -m systemd -a ‘name=ntpd state=started‘ 查看是否配置成功 [root@ceph-node1 ~]# ansible ceph -m shell -a ‘ntpq -p‘
OK,初始化工作总算是完成了,上面应用了大量的 ansible 来实现,避免重复的操作。接下来还会用到 ansible
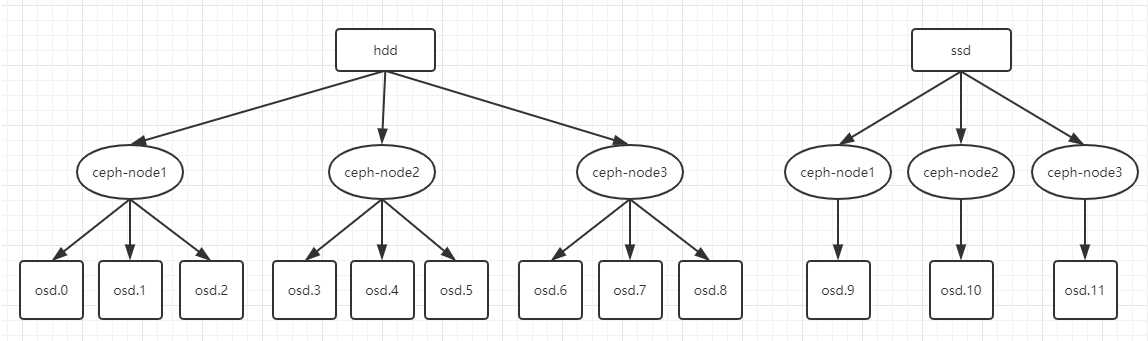
再次强调下 ceph 的架构:
240G SSD:用于3个2T SATA 和 800G SSD 的 block.wal 和 block.db 800G SSD:用作OSD,三台机器共 3个构成 ssd-pool 2T SATA:用作 OSD,三台机器共9个构成 sata-pool
磁盘分区
将 240 G 的盘分为 8 个分区,分别作为 block.wal 和 block.data 如果是在生成环境,这里建议使用 RAID 1 组一个冗余,然后在分区。假如 240G 已经是使用 RAID 1 组成的逻辑磁盘。
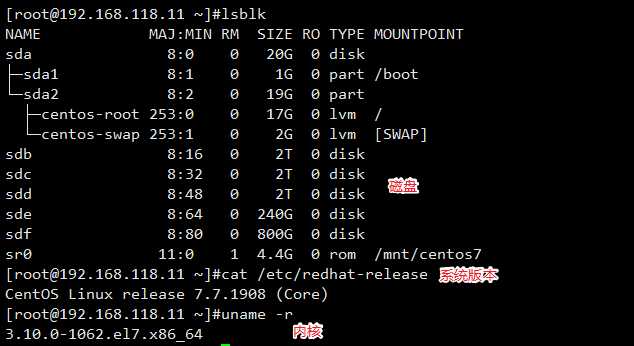
[root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mklabel gpt‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 2048s 12%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 12% 24%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 24% 36%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 36% 48%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 48% 60%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 60% 72%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 72% 84%‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘parted /dev/sde mkpart primary 84% 100%‘ [root@ceph-node1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─centos-root 253:0 0 17G 0 lvm / └─centos-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 2T 0 disk sdc 8:32 0 2T 0 disk sdd 8:48 0 2T 0 disk sde 8:64 0 240G 0 disk ├─sde1 8:65 0 28.8G 0 part ├─sde2 8:66 0 28.8G 0 part ├─sde3 8:67 0 28.8G 0 part ├─sde4 8:68 0 28.8G 0 part ├─sde5 8:69 0 28.8G 0 part ├─sde6 8:70 0 28.8G 0 part ├─sde7 8:71 0 28.8G 0 part └─sde8 8:72 0 38.4G 0 part sdf 8:80 0 800G 0 disk sr0 11:0 1 4.4G 0 rom /mnt/centos7
分区成功。
在 luminous 版本中,是用 ceph-volume 管理 OSD ,官方也推荐使用 lvm 管理磁盘。设置 LVM
设置 OSD 的 LVM
VGS [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate datavg1 /dev/sdb‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate datavg2 /dev/sdc‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate datavg3 /dev/sdd‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate datavg4 /dev/sdf‘ LVS ansible ceph -m shell -a ‘lvcreate -n datalv1 -l 100%Free datavg1‘ ansible ceph -m shell -a ‘lvcreate -n datalv2 -l 100%Free datavg2‘ ansible ceph -m shell -a ‘lvcreate -n datalv3 -l 100%Free datavg3‘ ansible ceph -m shell -a ‘lvcreate -n datalv4 -l 100%Free datavg4‘
设置 wal/db 的 LVM
VGS - wal [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_wal_vg1 /dev/sde1‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_wal_vg2 /dev/sde2‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_wal_vg3 /dev/sde3‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_wal_vg4 /dev/sde4‘ VGS - db [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_db_vg1 /dev/sde5‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_db_vg2 /dev/sde6‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_db_vg3 /dev/sde7‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘vgcreate block_db_vg4 /dev/sde8‘ LVS - wal [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n wallv1 -l 100%Free block_wal_vg1‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n wallv2 -l 100%Free block_wal_vg2‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n wallv3 -l 100%Free block_wal_vg3‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n wallv4 -l 100%Free block_wal_vg4‘ LVS - db [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n dblv1 -l 100%Free block_db_vg1‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n dblv2 -l 100%Free block_db_vg2‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n dblv3 -l 100%Free block_db_vg3‘ [root@ceph-node1 ~]# ansible ceph -m shell -a ‘lvcreate -n dblv4 -l 100%Free block_db_vg4‘ [root@ceph-node1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─centos-root 253:0 0 17G 0 lvm / └─centos-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 2T 0 disk └─datavg1-datalv1 253:2 0 2T 0 lvm sdc 8:32 0 2T 0 disk └─datavg2-datalv2 253:3 0 2T 0 lvm sdd 8:48 0 2T 0 disk └─datavg3-datalv3 253:4 0 2T 0 lvm sde 8:64 0 240G 0 disk ├─sde1 8:65 0 28.8G 0 part │ └─block_wal_vg1-wallv1 253:6 0 28.8G 0 lvm ├─sde2 8:66 0 28.8G 0 part │ └─block_wal_vg2-wallv2 253:7 0 28.8G 0 lvm ├─sde3 8:67 0 28.8G 0 part │ └─block_wal_vg3-wallv3 253:8 0 28.8G 0 lvm ├─sde4 8:68 0 28.8G 0 part │ └─block_wal_vg4-wallv4 253:9 0 28.8G 0 lvm ├─sde5 8:69 0 28.8G 0 part │ └─block_db_vg1-dblv1 253:10 0 28.8G 0 lvm ├─sde6 8:70 0 28.8G 0 part │ └─block_db_vg2-dblv2 253:11 0 28.8G 0 lvm ├─sde7 8:71 0 28.8G 0 part │ └─block_db_vg3-dblv3 253:12 0 28.8G 0 lvm └─sde8 8:72 0 38.4G 0 part └─block_db_vg4-dblv4 253:13 0 38.4G 0 lvm sdf 8:80 0 800G 0 disk └─datavg4-datalv4 253:5 0 800G 0 lvm sr0 11:0 1 4.4G 0 rom /mnt/centos7
LVM 设置完成。
首先要配置 yum 源,使用国内的yum 源会快很快,地址:http://mirrors.163.com/ceph/rpm-luminous/
[root@ceph-node1 ~]# cat /etc/yum.repos.d/ceph.repo [ceph] name = ceph gpgcheck = 0 baseurl = http://mirrors.163.com/ceph/rpm-luminous/el7/x86_64/ [ceph-deploy] name = ceph-deploy gpgcheck = 0 baseurl = https://download.ceph.com/rpm-luminous/el7/noarch/ [root@ceph-node1 ~]# yum repolist 将 ceph.repo 拷贝到另外两个节点 [root@ceph-node1 ~]# ansible ceph -m copy -a ‘src=/etc/yum.repos.d/ceph.repo dest=/etc/yum.repos.d/‘ -l ceph-node2,ceph-node3 每个节点都需要安装 ceph [root@ceph-node1 ~]# ansible ceph -m yum -a ‘name=ceph,ceph-radosgw state=latest‘
注意:如果是虚拟机做测试,建议此处创建 快照。
回顾下部署结构:
ceph-deploy 需要部署到 ceph-node1 节点就好。
[root@ceph-node1 ~]# yum install ceph-deploy -y [root@ceph-node1 ~]# ceph-deploy --version 2.0.1 [root@ceph-node1 ~]# ceph -v ceph version 12.2.12 (1436006594665279fe734b4c15d7e08c13ebd777) luminous (stable)
准备工作完全完成,接下来就开始创建集群。
新建 mycluster目录,所有操作的在此目录中执行,这样生成的文件都在此目录中
[root@ceph-node1 ~]# mkdir mycluster [root@ceph-node1 ~]# cd mycluster/ [root@ceph-node1 mycluster]# ceph-deploy new ceph-node1 ceph-node2 ceph-node3 --public-network=192.168.118.0/24 --cluster-network=192.168.61.0/24 [root@ceph-node1 mycluster]# ceph-deploy new ceph-node1 ceph-node2 ceph-node3 --public-network=192.168.118.0/24 --cluster-network=192.168.61.0/24 执行完上面的命令后,mycluster 目录中会生成三个文件: [root@ceph-node1 mycluster]# ls ceph.conf ceph.log ceph.mon.keyring 开始部署 Monitor [root@ceph-node1 mycluster]# ceph-deploy mon create-initial 将配置文件及密钥拷贝到其他 monitor 节点 [root@ceph-node1 mycluster]# ceph-deploy admin ceph-node1 ceph-node2 ceph-node3 执行完毕以后,可通过 ceph -s 查看集群状态: [root@ceph-node1 mycluster]# ceph -s cluster: id: 6770a64a-b474-409c-bdf1-85a47397ad6e health: HEALTH_OK services: mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 mgr: no daemons active osd: 0 osds: 0 up, 0 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0B usage: 0B used, 0B / 0B avail pgs:
出现如上信息,表明集群配置成功。
部署OSD ,block.wal 和 block.db 对应关系
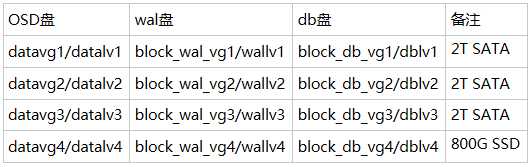
需要部署两组 OSD 一组为 SATA 另一组为 SSD,首先创建 SATA组:
#sata ceph-deploy osd create ceph-node1 --bluestore --block-wal block_wal_vg1/wallv1 --block-db block_db_vg1/dblv1 --data datavg1/datalv1 ceph-deploy osd create ceph-node1 --bluestore --block-wal block_wal_vg2/wallv2 --block-db block_db_vg2/dblv2 --data datavg2/datalv2 ceph-deploy osd create ceph-node1 --bluestore --block-wal block_wal_vg3/wallv3 --block-db block_db_vg3/dblv3 --data datavg3/datalv3 ceph-deploy osd create ceph-node2 --bluestore --block-wal block_wal_vg1/wallv1 --block-db block_db_vg1/dblv1 --data datavg1/datalv1 ceph-deploy osd create ceph-node2 --bluestore --block-wal block_wal_vg2/wallv2 --block-db block_db_vg2/dblv2 --data datavg2/datalv2 ceph-deploy osd create ceph-node2 --bluestore --block-wal block_wal_vg3/wallv3 --block-db block_db_vg3/dblv3 --data datavg3/datalv3 ceph-deploy osd create ceph-node3 --bluestore --block-wal block_wal_vg1/wallv1 --block-db block_db_vg1/dblv1 --data datavg1/datalv1 ceph-deploy osd create ceph-node3 --bluestore --block-wal block_wal_vg2/wallv2 --block-db block_db_vg2/dblv2 --data datavg2/datalv2 ceph-deploy osd create ceph-node3 --bluestore --block-wal block_wal_vg3/wallv3 --block-db block_db_vg3/dblv3 --data datavg3/datalv3 #ssd ceph-deploy osd create ceph-node1 --bluestore --block-wal block_wal_vg4/wallv4 --block-db block_db_vg4/dblv4 --data datavg4/datalv4 ceph-deploy osd create ceph-node2 --bluestore --block-wal block_wal_vg4/wallv4 --block-db block_db_vg4/dblv4 --data datavg4/datalv4 ceph-deploy osd create ceph-node3 --bluestore --block-wal block_wal_vg4/wallv4 --block-db block_db_vg4/dblv4 --data datavg4/datalv4
提醒:建议一条一条执行,如果有问题能及时发现解决。
执行完毕,查看:
[root@ceph-node1 mycluster]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 20.34357 root default -3 6.78119 host ceph-node1 0 hdd 2.00000 osd.0 up 1.00000 1.00000 1 hdd 2.00000 osd.1 up 1.00000 1.00000 2 hdd 2.00000 osd.2 up 1.00000 1.00000 9 hdd 0.78119 osd.9 up 1.00000 1.00000 -5 6.78119 host ceph-node2 3 hdd 2.00000 osd.3 up 1.00000 1.00000 4 hdd 2.00000 osd.4 up 1.00000 1.00000 5 hdd 2.00000 osd.5 up 1.00000 1.00000 10 hdd 0.78119 osd.10 up 1.00000 1.00000 -7 6.78119 host ceph-node3 6 hdd 2.00000 osd.6 up 1.00000 1.00000 7 hdd 2.00000 osd.7 up 1.00000 1.00000 8 hdd 2.00000 osd.8 up 1.00000 1.00000 11 hdd 0.78119 osd.11 up 1.00000 1.00000
所有 OSD 都添加成功。检测下 ceph 集群的健康状态
[root@ceph-node1 ~]# ceph -s cluster: id: fe899ca1-b3c0-46f6-aa4a-42591760860f health: HEALTH_WARN no active mgr clock skew detected on mon.ceph-node2, mon.ceph-node3 services: mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 mgr: no daemons active osd: 12 osds: 12 up, 12 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0B usage: 0B used, 0B / 0B avail pgs:
提示:no active mgr 这个 manager 是在 J 版本以后加入的,此时需要开启这个功能模块:
[root@ceph-node1 ~]# cd mycluster/ [root@ceph-node1 mycluster]# ceph-deploy mgr create ceph-node1 ceph-node2 ceph-node3
注意:只要是牵扯到要执行 ceph-deploy 都需要进入到 mycluster 否则会报错。
再次查看集群健康
[root@ceph-node1 mycluster]# ceph -s cluster: id: fe899ca1-b3c0-46f6-aa4a-42591760860f health: HEALTH_WARN clock skew detected on mon.ceph-node3 services: mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 mgr: ceph-node1(active), standbys: ceph-node3, ceph-node2 osd: 12 osds: 12 up, 12 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0B usage: 12.1GiB used, 20.3TiB / 20.3TiB avail pgs:
clock skew detected 时钟偏移问题可以通过修改配置文件实现,也就是加大群集节点的时间偏移量,避免告警信息:
[root@ceph-node1 ~]# cd mycluster/
[root@ceph-node1 mycluster]# vim ceph.conf
# 最后两行追加内容
...
mon clock drift allowed = 2
mon clock drift warn backoff = 30
# 将配置文件推送到集群的各个节点
[root@ceph-node1 mycluster]# ceph-deploy --overwrite-conf config push ceph-node{1..3}
# 重启服务
[root@ceph-node1 mycluster]# ansible ceph -m systemd -a ‘name=ceph-mon.target state=restarted‘
# 告警消除
[root@ceph-node1 mycluster]# ceph -s
cluster:
id: fe899ca1-b3c0-46f6-aa4a-42591760860f
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3
mgr: ceph-node1(active), standbys: ceph-node3, ceph-node2
osd: 12 osds: 12 up, 12 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 12.1GiB used, 20.3TiB / 20.3TiB avail
pgs:
接下来就需要对 OSD 进行分组,在分组之前,需要介绍一个新功能。
Ceph 从 L 版本开始新增了一个功能叫 crush class,又被称为 磁盘智能分组。因为这个功能就是根据磁盘类型自动进行属性关联,然后进行分类减少了很多人为的操作。在这个功能之前,如果需要对ssd和hdd进行分组的时候,需要大量的修改 crushmap,然后绑定不同的存储池到不同的 crush树上面,而这个功能简化了这种逻辑。
配置 crush class
默认情况下,所有 osd 都会 class 的类型是 hdd:
[root@ceph-node1 mycluster]# ceph osd crush class ls [ "hdd" ]
查看当前OSD
[root@ceph-node1 mycluster]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 20.34357 root default -3 6.78119 host ceph-node1 0 hdd 2.00000 osd.0 up 1.00000 1.00000 1 hdd 2.00000 osd.1 up 1.00000 1.00000 2 hdd 2.00000 osd.2 up 1.00000 1.00000 9 hdd 0.78119 osd.9 up 1.00000 1.00000 -5 6.78119 host ceph-node2 3 hdd 2.00000 osd.3 up 1.00000 1.00000 4 hdd 2.00000 osd.4 up 1.00000 1.00000 5 hdd 2.00000 osd.5 up 1.00000 1.00000 10 hdd 0.78119 osd.10 up 1.00000 1.00000 -7 6.78119 host ceph-node3 6 hdd 2.00000 osd.6 up 1.00000 1.00000 7 hdd 2.00000 osd.7 up 1.00000 1.00000 8 hdd 2.00000 osd.8 up 1.00000 1.00000 11 hdd 0.78119 osd.11 up 1.00000 1.00000
可以看到,当前有3个节点,每个节点上有4个OSD,根据之前的分组,一组为 SATA 另一组为 SSD ,而且根据上面创建 OSD 的顺序,可以做以下总结:

既然默认都为 hdd组,那SATA就不用在创建了,osd9-11 创建为 ssd 组即可。首先,需要将 osd9-11 从 hdd 组中去除掉:
[root@ceph-node1 mycluster]# for i in {9..11};do ceph osd crush rm-device-class osd.$i;done
done removing class of osd(s): 9
done removing class of osd(s): 10
done removing class of osd(s): 11
查看 osd
[root@ceph-node1 mycluster]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 20.34357 root default -3 6.78119 host ceph-node1 9 0.78119 osd.9 up 1.00000 1.00000 0 hdd 2.00000 osd.0 up 1.00000 1.00000 1 hdd 2.00000 osd.1 up 1.00000 1.00000 2 hdd 2.00000 osd.2 up 1.00000 1.00000 -5 6.78119 host ceph-node2 10 0.78119 osd.10 up 1.00000 1.00000 3 hdd 2.00000 osd.3 up 1.00000 1.00000 4 hdd 2.00000 osd.4 up 1.00000 1.00000 5 hdd 2.00000 osd.5 up 1.00000 1.00000 -7 6.78119 host ceph-node3 11 0.78119 osd.11 up 1.00000 1.00000 6 hdd 2.00000 osd.6 up 1.00000 1.00000 7 hdd 2.00000 osd.7 up 1.00000 1.00000 8 hdd 2.00000 osd.8 up 1.00000 1.00000
可以看到 osd9-11 class 列已经没有 hdd 标识了。此时就可以通过命令将osd9-11添加到 ssd 组了,如下:
# 将 osd9-11添加到 ssd 组
[root@ceph-node1 mycluster]# for i in {9..11}; do ceph osd crush set-device-class ssd osd.$i;done
set osd(s) 9 to class ‘ssd‘
set osd(s) 10 to class ‘ssd‘
set osd(s) 11 to class ‘ssd‘
# 查看 osd
[root@ceph-node1 mycluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 20.34357 root default
-3 6.78119 host ceph-node1
0 hdd 2.00000 osd.0 up 1.00000 1.00000
1 hdd 2.00000 osd.1 up 1.00000 1.00000
2 hdd 2.00000 osd.2 up 1.00000 1.00000
9 ssd 0.78119 osd.9 up 1.00000 1.00000
-5 6.78119 host ceph-node2
3 hdd 2.00000 osd.3 up 1.00000 1.00000
4 hdd 2.00000 osd.4 up 1.00000 1.00000
5 hdd 2.00000 osd.5 up 1.00000 1.00000
10 ssd 0.78119 osd.10 up 1.00000 1.00000
-7 6.78119 host ceph-node3
6 hdd 2.00000 osd.6 up 1.00000 1.00000
7 hdd 2.00000 osd.7 up 1.00000 1.00000
8 hdd 2.00000 osd.8 up 1.00000 1.00000
11 ssd 0.78119 osd.11 up 1.00000 1.00000
# 查看 class
[root@ceph-node1 mycluster]# ceph osd crush class ls
[
"hdd",
"ssd"
]
可以发现 osd9-11 的 class 列都变为 ssd,查看 crush class 也多出一个 ssd 的组,接下来就需要创建ssd 的规则
创建基于 ssd 的 class rule
创建一个 class rule,取名为 root-ssd,使用 ssd的osd:
[root@ceph-node1 mycluster]# ceph osd crush rule create-replicated root_ssd default host ssd # 查看创建的 rule [root@ceph-node1 mycluster]# ceph osd crush rule ls replicated_rule root_ssd
通过以下操作可以查看详细的 crushmap信息:
[root@ceph-node1 mycluster]# ceph osd getcrushmap -o /tmp/crushmap
32
[root@ceph-node1 mycluster]# crushtool -d /tmp/crushmap -o /tmp/crushmap.txt
[root@ceph-node1 mycluster]# cat /tmp/crushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
device 9 osd.9 class ssd
device 10 osd.10 class ssd
device 11 osd.11 class ssd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
# buckets
host ceph-node1 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
id -9 class ssd # do not change unnecessarily
# weight 6.781
alg straw2
hash 0 # rjenkins1
item osd.0 weight 2.000
item osd.1 weight 2.000
item osd.2 weight 2.000
item osd.9 weight 0.781
}
host ceph-node2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
id -10 class ssd # do not change unnecessarily
# weight 6.781
alg straw2
hash 0 # rjenkins1
item osd.3 weight 2.000
item osd.4 weight 2.000
item osd.5 weight 2.000
item osd.10 weight 0.781
}
host ceph-node3 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
id -11 class ssd # do not change unnecessarily
# weight 6.781
alg straw2
hash 0 # rjenkins1
item osd.6 weight 2.000
item osd.7 weight 2.000
item osd.8 weight 2.000
item osd.11 weight 0.781
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
id -12 class ssd # do not change unnecessarily
# weight 20.344
alg straw2
hash 0 # rjenkins1
item ceph-node1 weight 6.781
item ceph-node2 weight 6.781
item ceph-node3 weight 6.781
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule root_ssd {
id 1
type replicated
min_size 1
max_size 10
step take default class ssd
step chooseleaf firstn 0 type host
step emit
}
# end crush map
到此为止,使用智能分组的功能,实现了 SATA 和 SSD 的分离。
测试 ssd分组
将 osd9-11 作为 ssd分组使用,来测试下是否真的将数据存入了 osd9-11
(1)创建一个基于root_ssd 规则的存储池
# 查看当前的 rule [root@ceph-node1 mycluster]# ceph osd crush rule ls replicated_rule root_ssd # 通过 root_ssd 创建 [root@ceph-node1 mycluster]# ceph osd pool create ssd_test 64 64 root_ssd pool ‘ssd_test‘ created
(2)测试基于ssd的池
# 创建测试文件 [root@ceph-node1 mycluster]# echo ‘test‘ > test.txt # 将测试文件以对象名test 写入到 ssd_test 池 [root@ceph-node1 mycluster]# rados -p ssd_test put test test.txt [root@ceph-node1 mycluster]# rados -p ssd_test ls test # 查看ssd_test 中对象名为 test 的文件分布在 OSD 的位置 [root@ceph-node1 mycluster]# ceph osd map ssd_test test osdmap e63 pool ‘ssd_test‘ (1) object ‘test‘ -> pg 1.40e8aab5 (1.35) -> up ([10,11,9], p10) acting ([10,11,9], p10)
可以看到,文件 test.txt 存储在 osd9-11 中,符合预期设定。
本文也算是把 CentOS 7 结合 Ceph L版本的配置完整的走了一边,可用于生产环境的部署。后续会记录一些运维中遇到的操作。
[ ceph ] CEPH 部署完整版(CentOS 7 + luminous)
原文:https://www.cnblogs.com/hukey/p/11975109.html