本文首发于个人博客https://kezunlin.me/post/88fbc049/,欢迎阅读最新内容!
keras efficientnet introduction
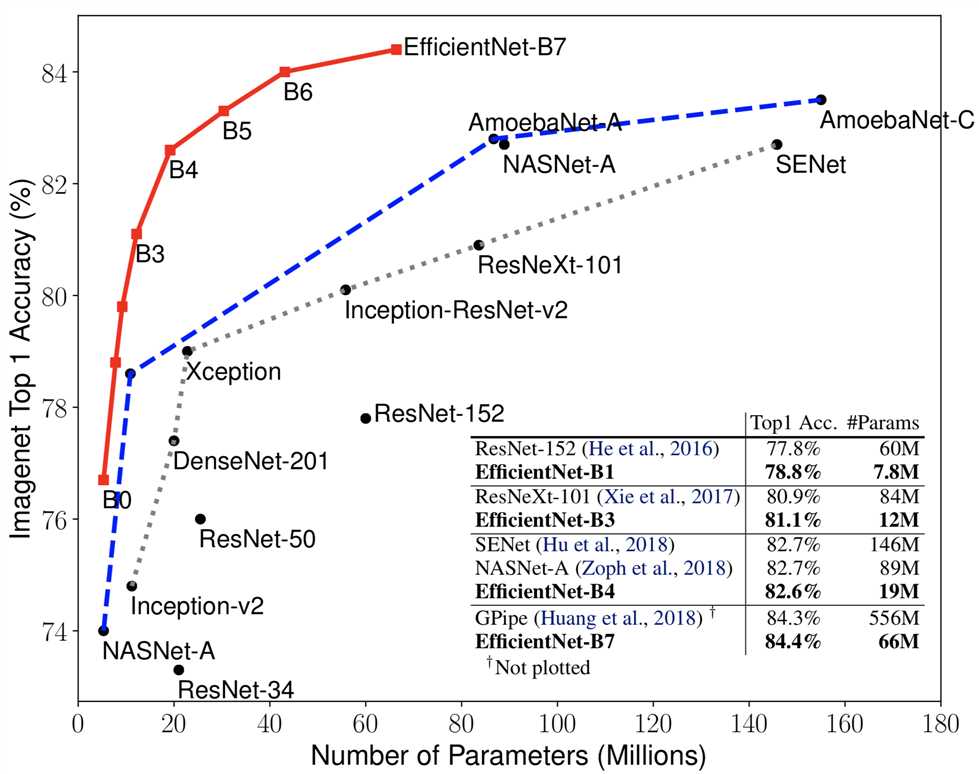
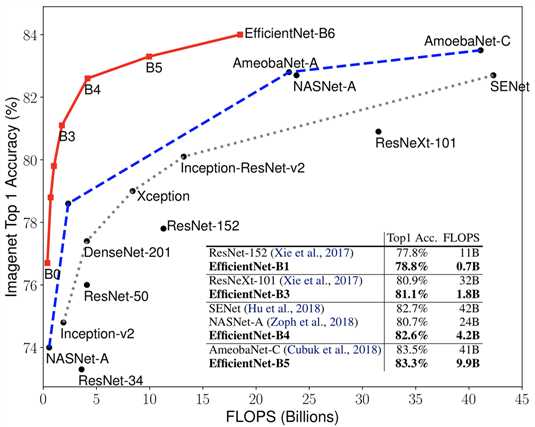
compared with resnet50, EfficientNet-B4 improves the top-1 accuracy from 76.3% of ResNet-50 to 82.6% (+6.3%), under similar FLOPS constraint.
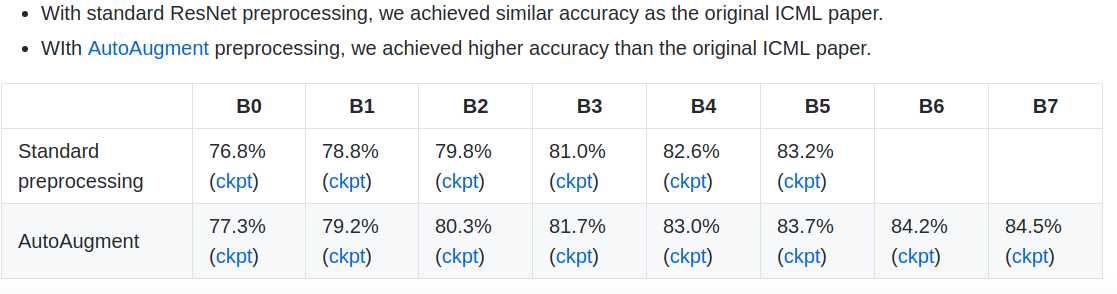
The input size used was 224x224 for all models except NASNetLarge (331x331), InceptionV3 (299x299), InceptionResNetV2 (299x299), Xception (299x299),
EfficientNet-B0 (224x224), EfficientNet-B1 (240x240), EfficientNet-B2 (260x260), EfficientNet-B3 (300x300), EfficientNet-B4 (380x380), EfficientNet-B5 (456x456), EfficientNet-B6 (528x528), and EfficientNet-B7 (600x600).
notice
include_top=Trueinclude_top=False| Top-1 | Top-5 | 10-5 | Size | Stem | References | |
|---|---|---|---|---|---|---|
| VGG16 | 28.732 | 9.950 | 8.834 | 138.4M | 14.7M | [paper] [tf-models] |
| VGG19 | 28.744 | 10.012 | 8.774 | 143.7M | 20.0M | [paper] [tf-models] |
| ResNet50 | 25.072 | 7.940 | 6.828 | 25.6M | 23.6M | [paper] [tf-models] [torch] [caffe] |
| ResNet101 | 23.580 | 7.214 | 6.092 | 44.7M | 42.7M | [paper] [tf-models] [torch] [caffe] |
| ResNet152 | 23.396 | 6.882 | 5.908 | 60.4M | 58.4M | [paper] [tf-models] [torch] [caffe] |
| ResNet50V2 | 24.040 | 6.966 | 5.896 | 25.6M | 23.6M | [paper] [tf-models] [torch] |
| ResNet101V2 | 22.766 | 6.184 | 5.158 | 44.7M | 42.6M | [paper] [tf-models] [torch] |
| ResNet152V2 | 21.968 | 5.838 | 4.900 | 60.4M | 58.3M | [paper] [tf-models] [torch] |
| ResNeXt50 | 22.260 | 6.190 | 5.410 | 25.1M | 23.0M | [paper] [torch] |
| ResNeXt101 | 21.270 | 5.706 | 4.842 | 44.3M | 42.3M | [paper] [torch] |
| InceptionV3 | 22.102 | 6.280 | 5.038 | 23.9M | 21.8M | [paper] [tf-models] |
| InceptionResNetV2 | 19.744 | 4.748 | 3.962 | 55.9M | 54.3M | [paper] [tf-models] |
| Xception | 20.994 | 5.548 | 4.738 | 22.9M | 20.9M | [paper] |
| MobileNet(alpha=0.25) | 48.418 | 24.208 | 21.196 | 0.5M | 0.2M | [paper] [tf-models] |
| MobileNet(alpha=0.50) | 35.708 | 14.376 | 12.180 | 1.3M | 0.8M | [paper] [tf-models] |
| MobileNet(alpha=0.75) | 31.588 | 11.758 | 9.878 | 2.6M | 1.8M | [paper] [tf-models] |
| MobileNet(alpha=1.0) | 29.576 | 10.496 | 8.774 | 4.3M | 3.2M | [paper] [tf-models] |
| MobileNetV2(alpha=0.35) | 39.914 | 17.568 | 15.422 | 1.7M | 0.4M | [paper] [tf-models] |
| MobileNetV2(alpha=0.50) | 34.806 | 13.938 | 11.976 | 2.0M | 0.7M | [paper] [tf-models] |
| MobileNetV2(alpha=0.75) | 30.468 | 10.824 | 9.188 | 2.7M | 1.4M | [paper] [tf-models] |
| MobileNetV2(alpha=1.0) | 28.664 | 9.858 | 8.322 | 3.5M | 2.3M | [paper] [tf-models] |
| MobileNetV2(alpha=1.3) | 25.320 | 7.878 | 6.728 | 5.4M | 3.8M | [paper] [tf-models] |
| MobileNetV2(alpha=1.4) | 24.770 | 7.578 | 6.518 | 6.2M | 4.4M | [paper] [tf-models] |
| DenseNet121 | 25.028 | 7.742 | 6.522 | 8.1M | 7.0M | [paper] [torch] |
| DenseNet169 | 23.824 | 6.824 | 5.860 | 14.3M | 12.6M | [paper] [torch] |
| DenseNet201 | 22.680 | 6.380 | 5.466 | 20.2M | 18.3M | [paper] [torch] |
| NASNetLarge | 17.502 | 3.996 | 3.412 | 93.5M | 84.9M | [paper] [tf-models] |
| NASNetMobile | 25.634 | 8.146 | 6.758 | 7.7M | 4.3M | [paper] [tf-models] |
| EfficientNet-B0 | 22.810 | 6.508 | 5.858 | 5.3M | 4.0M | [paper] [tf-tpu] |
| EfficientNet-B1 | 20.866 | 5.552 | 5.050 | 7.9M | 6.6M | [paper] [tf-tpu] |
| EfficientNet-B2 | 19.820 | 5.054 | 4.538 | 9.2M | 7.8M | [paper] [tf-tpu] |
| EfficientNet-B3 | 18.422 | 4.324 | 3.902 | 12.3M | 10.8M | [paper] [tf-tpu] |
| EfficientNet-B4 | 17.040 | 3.740 | 3.344 | 19.5M | 17.7M | [paper] [tf-tpu] |
| EfficientNet-B5 | 16.298 | 3.290 | 3.114 | 30.6M | 28.5M | [paper] [tf-tpu] |
| EfficientNet-B6 | 15.918 | 3.102 | 2.916 | 43.3M | 41.0M | [paper] [tf-tpu] |
| EfficientNet-B7 | 15.570 | 3.160 | 2.906 | 66.7M | 64.1M | [paper] [tf-tpu] |
keras EfficientNet介绍,在ImageNet任务上涨点明显 | keras efficientnet introduction
原文:https://www.cnblogs.com/kezunlin/p/11980638.html