------------恢复内容开始------------
集群分类:
1、 利用集群方案解决单点故障SPoF(Single Point of Failure) 。
2、提高系统可用性,降低MTTR。
A=MTBF平均故障间隔时间/(MTBF平均故障间隔时间+MTTR平均恢复时间)
高可用集群的标准有: 99%, 99.5%, ...., 99.999%,99.9999%;
3、利用集群方案解决硬件和软件故障:设计缺陷、wear out、自然灾害等。
手段:冗余方案(redundant)
集群主机分为:active/passive(一主多备),active/active(双主)
解决方案的开源软件有:keepalived 、heartbeat、corosyns
一般采用奇数主机方案3/5/7个
HA nginx service:概念可以理解为高可用的是“服务”,组成一个高可用服务的“组件”叫做资源;
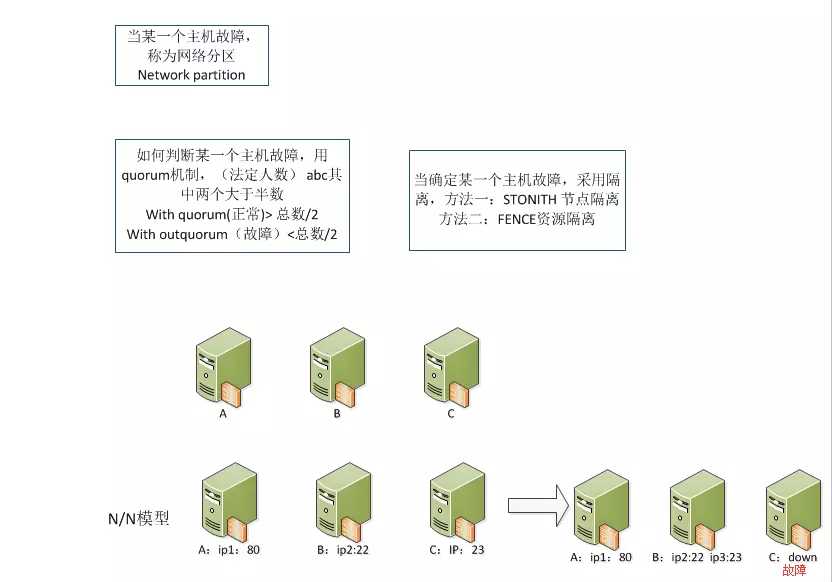
节点主机相互通信可以分为以下:
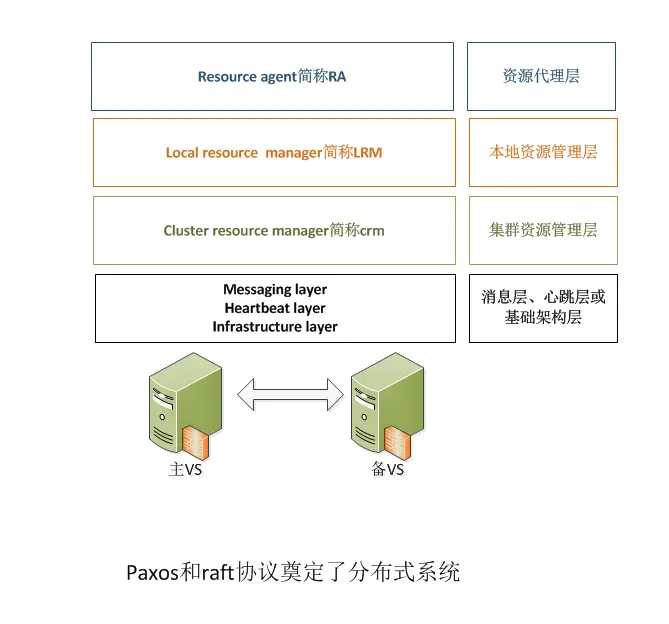
也叫资源管理器层,真正实现集群服务的层。包含CRM(集群资源管理器,cluster Resource Manager),CIB(集群信息基库,Cluster Infonation Base),PE(策略引擎,Policy Engine),TE(实施引擎,Transition Engine), LRM(Local Resource Manager,本地资源管理器)。
CRM组件:核心组件,实现资源的分配和管理。每个节点上的CRM都维护一个CIB用来定义资源特定的属性,哪些资源定义在同一个节点上。主节点上的CRM被选举为DC(Designated Coordinator指定协调员,主节点挂掉会选出新的DC),成为管理者,它的工作是决策和管理集群中的所有资源。
任何DC上会额外运行两个进程,一个叫PE,;一个叫TEPE :定义资源转移的一整套转移方式,但只做策略,并不亲自来参加资源转移的过程,而是让TE来执行自己的策略。
TE : 就是来执行PE做出的策略的并且只有DC上才运行PE和TE。
CIB组件:XML格式的配置文件,工作的时候常驻内存,只有DC才能对CIB进行修改,其他节点上的复制DC上的CIB而来。集群的所有信息都会反馈在CIB中。
LRM组件:是执行CRM传递过来的在本地执行某个资源的执行和停止的具体执行人。
资源(补充):
在集群中构成一个完整服务的每一部分都叫资源,都需要配置和管理。
以web应用为例:vip是资源,web服务器是资源,存储也是资源。不同的服务的资源也不尽相同,其中存储资源的选择、配置、管理是高可用集群中的难点问题。
集群资源代理,能够管理本节点上的属于集群资源的某一资源的启动,停止和状态信息的脚本,资源代理分为:LSB(/etc/init.d/*),OCF(比LSB更专业,更加通用)。
任何资源代理都要使用同一种风格,接收四个参数:{start|stop|restart|status},每个种资源的代理都要完成这四个参数据的输出。
Failover:故障切换,即某资源的主节点故障时,将资源转移至其它节点的操作;
Failback:故障移回,即某资源的主节点故障后重新修改上线后,将转移至其它节点的资源重新切回的过程
原文:https://www.cnblogs.com/ghl666/p/11981671.html