What:朴素贝叶斯是一个常用的分类算法,监督学习。
朴素:假设各个特征之间相互独立。
贝叶斯:基于贝叶斯原理:
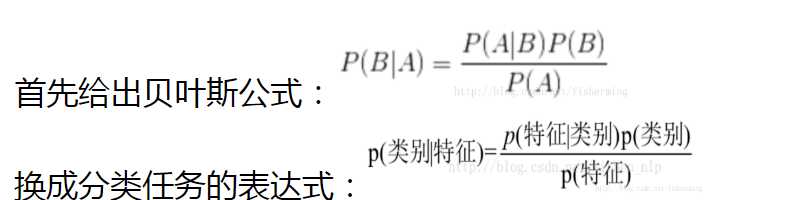
![]() 为条件概率,属于某个类别的样本具有某个特征的概率。
为条件概率,属于某个类别的样本具有某个特征的概率。
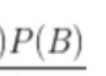 为先验概率,某个样本属于某个类别的概率。
为先验概率,某个样本属于某个类别的概率。
![]() 为后验概率,即是具有某些特征的的样本属于某个类别的概率。
为后验概率,即是具有某些特征的的样本属于某个类别的概率。
举例应用为:


最后得出嫁与不嫁的概率,选择概率大的即为女生嫁不嫁的预测决定。
Why:
此方法实际上多用于文本分类当中,文本分类就是寻找文本的特征。
垃圾短信的分类问题。
输入:待判断的短信
输出:是否是垃圾短信
算法主要分为两个部分:数据处理和算法的实现。
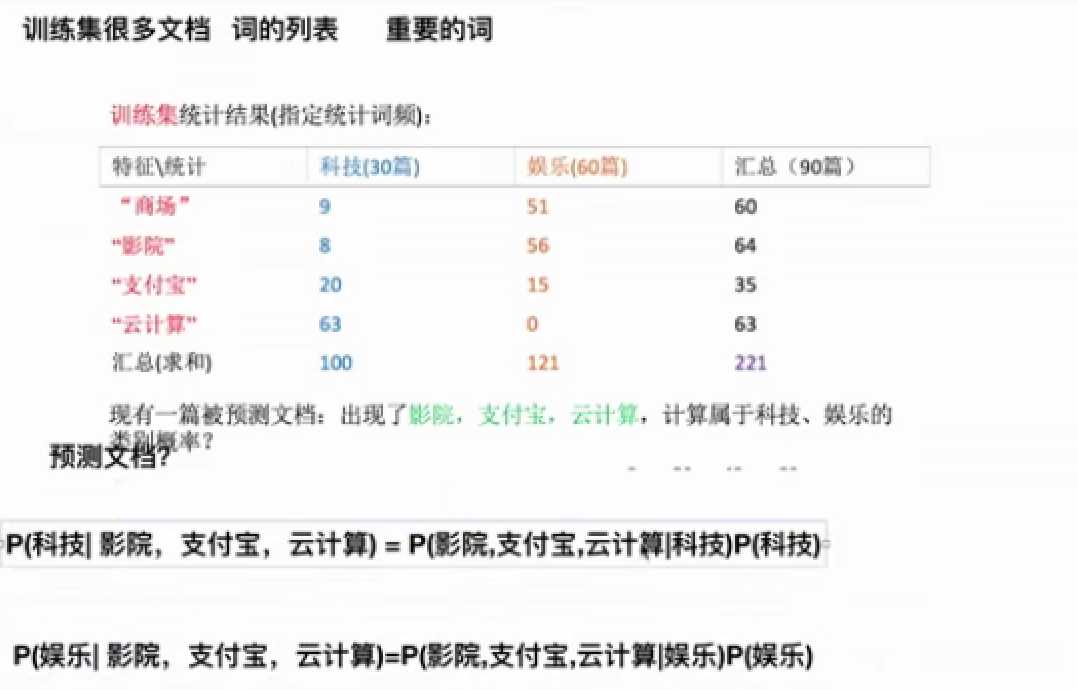
每一个单词代表一种特征,即是求在所求短信下的短信类别。
寻找一个分类器,这个分类器能够:当丢给它一篇新文档d,它就输出d (最有可能)属于哪个类别c。

朴素贝叶斯分类器

为了防止某一个特征值为零而导致整个概率为零,我们引入了拉普拉斯平滑。

算法的实现:
数据的读取------数据的清洗(去除不含有意义上的单词)------数据的切分(类别+单词列表)-----划分数据集和测试集-------构建朴素贝叶斯分类器(得到分类器的参数)-------测试分类器
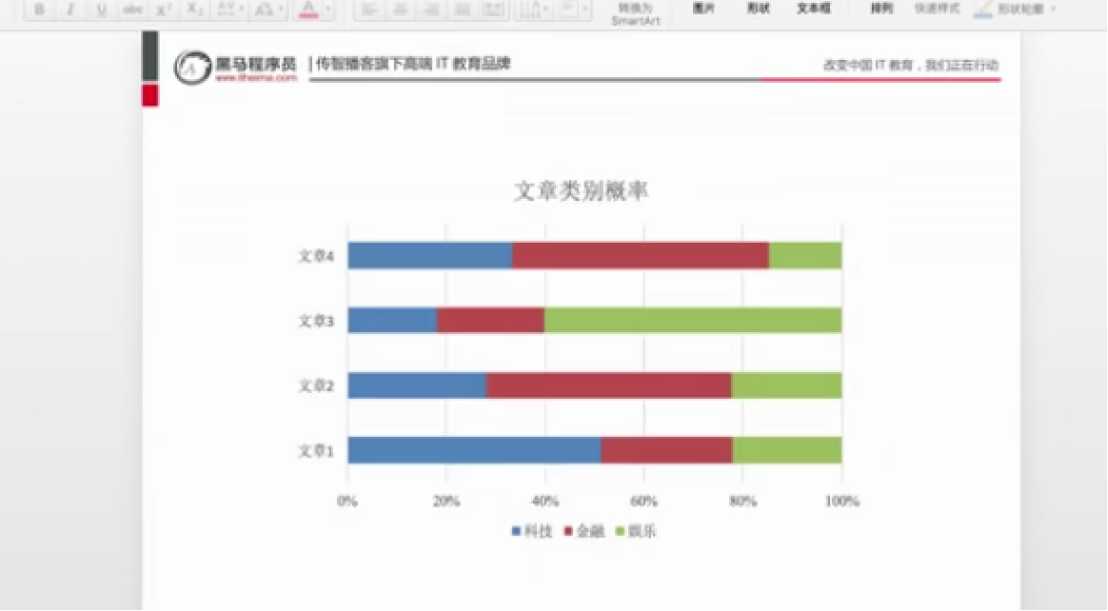
朴素贝叶斯是求出每一个概率的大小,通过比较每一类概率的大小来判断预测出测试数据属于哪一类别。
朴素贝叶斯算法:






















原文:https://www.cnblogs.com/lyy66/p/11994146.html