建模数据的预处理的过程中,变量分箱(即变量离散化)往往是较为核心一环。变量分箱的优劣往往会影响模型评分效果.
1.对异常数据有比较好的鲁棒性.
2.在逻辑回归模型中,单个变量分箱之后每个箱有自己独立的权重,相当于给模型加入了非线性的能力,能够提升模型的表达能力,极大拟合.
3.缺失值也可以作为一类特殊的变量进行模型.
4.分箱之后相对于简单的one_hot编码而言能够降低模型的复杂度,提升模型运算速度,对后期生产上线较为友好.
举个例子,在实际模型建立当中,有个 job 职业的特征,取值为(“国家机关人员”,“专业技术人员”,“商业服务人员”),对于这一类变量,如果我们将其依次赋值为(国家机关人员=1;专业技术人员=2;商业服务人员=3),就很容易产生一个问题,不同种类的职业在数据层面上就有了大小顺序之分,国家机关人员和商业服务人员的差距是2,专业技术人员和商业服务人员的之间的差距是1,而我们原来的中文分类中是不存在这种先后顺序关系的。所以这么简单的赋值是会使变量失去原来的衡量效果。
怎么处理这个问题呢,“一位有效编码” (one-hot Encoding)可以解决这个问题,通常叫做虚变量或者哑变量(dummpy variable):比如职业特征有3个不同变量,那么将其生成个2哑变量,分别是“是否国家党政职业人员”,“是否专业技术人员” ,每个虚变量取值(1,0)。
有序多分类变量是很常见的变量形式,通常在变量中有多个可能会出现的取值,各取值之间还存在等级关系。比如高血压分级(0=正常,1=正常高值,2=1级高血压,3=2级高血压,4=3级高血压)这类变量处理起来简直不要太省心,使用 pandas 中的 map()替换相应变量就行。
import pandas as pd df= pd.DataFrame([‘正常‘,‘3级高血压‘,‘正常‘,‘2级高血压‘,‘正常‘,‘正常高值‘,‘1级高血压‘],columns=[‘blood_pressure‘]) dic_blood = {‘正常‘:0,‘正常高值‘:1,‘1级高血压‘:2,‘2级高血压‘:3,‘3级高血压‘:4} df[‘blood_pressure_enc‘] = df[‘blood_pressure‘].map(dic_blood) print(df)
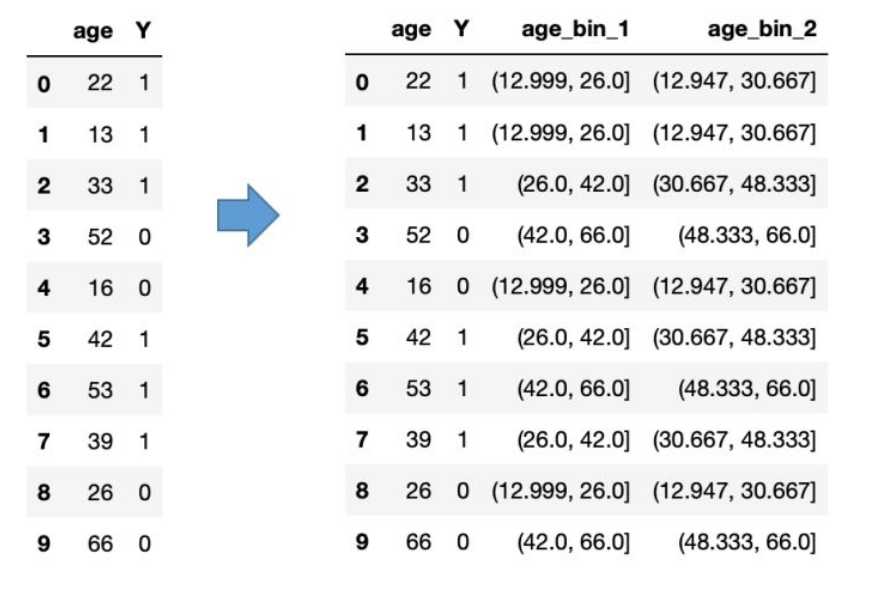
连续变量的分箱可以划分2种:无监督分组,有监督分组
等宽划分:按照相同宽度将数据分成几等份。缺点是受到异常值的影响比较大。 pandas.cut方法可以进行等宽划分。
等频划分:将数据分成几等份,每等份数据里面的个数是一样的。pandas.qcut方法可以进行等频划分。
import pandas as pd df = pd.DataFrame([[22,1],[13,1],[33,1],[52,0],[16,0],[42,1],[53,1],[39,1],[26,0],[66,0]],columns=[‘age‘,‘Y‘]) #print(df) df[‘age_bin_1‘] = pd.qcut(df[‘age‘],3) #新增一列存储等频划分的分箱特征 df[‘age_bin_2‘] = pd.cut(df[‘age‘],3) #新增一列存储等距划分的分箱特征 print(df)
3.3.2有监督学习方法:
卡方分箱(em...这个我看是风空模型里面的,具体的可能后续要补一补)
原文:https://www.cnblogs.com/z1141000271/p/11995616.html