代码
1 #!/usr/bin/env python3
2 # coding:utf-8
3 #lanxing
4
5 #判断代码,判断是否安装requests库
6 try:
7 import requests
8 except:
9 print(u"返回桌面,Shift+鼠标右键,在此处打开命令窗口(W),输入:pip install requests")
10 import zlib
11 import json
12
13 def whatweb(url):
14 response = requests.get(url,verify=False)
15 #上面的代码可以随意发挥,只要获取到response即可
16 #下面的代码您无需改变,直接使用即可
17 whatweb_dict = {"url":response.url,"text":response.text,"headers":dict(response.headers)}
18 whatweb_dict = json.dumps(whatweb_dict)
19 whatweb_dict = whatweb_dict.encode()
20 whatweb_dict = zlib.compress(whatweb_dict)
21 data = {"info":whatweb_dict}
22 return requests.post("http://whatweb.bugscaner.com/api.go",files=data)
23
24 if __name__ == ‘__main__‘:
25 request = whatweb(input(‘请输入你要识别的网站:‘)) #http://www.xxx.com
26 #request = whatweb("http://www.lol-xyzhs.com") #要识别的网站
27 print(u"今日识别剩余次数")
28 print(request.headers["X-RateLimit-Remaining"])
29 print(u"识别结果")
30 # print(request.headers["Server"])
31 print(request.json())
效果
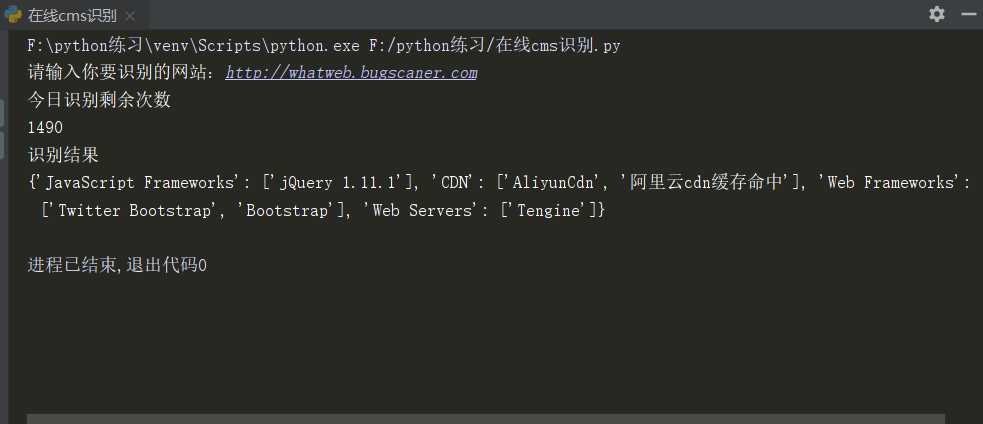
最后
这个是直接调用别人网站提供的api接口来识别的,识别库不是很强大,有空搞个cms识别库到本地玩玩
原文:https://www.cnblogs.com/lanyincao/p/12001586.html