由于java是强类型语言,所以要进行有些运算的时候,需要用到类型转换。
低-----------------------------高
byte,short,char-->int-->long-->float-->double强制类型转换 (类型)变量名 高--->低
自动转换 低--->高
注意点:
System.out.println((int)23.7); //23
System.out.println((int)-45.89f); //-45char c = 'a';
int d = c+1;
System.out.println(d); //98操作比较大的数的时候,注意溢出问题
JDK7新特性,数字之间可以用下划线分割
int money = 10_0000-0000;变量就是可以变化的量叫变量。
变量的作用域
public class Variable{
static int a = 0; //类变量
String str = "Hello World"; //实例变量
public void method(){
int i = 0; //局部变量
}
}常量(Constant):初始化(initialize)后不能再改变值!不会变动的值。(它的值被设定后,在程序运行过程中不允许被改变)
final 常量名 = 值;
final double PI = 3.14;常量名一般使用大写得字符。

&& (与)、||(或)、!(非,取反)
&&:左右两边都为真,结果才为true;(有短路效应,第一个为false就不向下进行判断)
||:两个结果有一个为真,结果便为true;(有短路效应,第一个为true就不向下进行判断)
!( ):如果是真,则变为假;如果是假,则变为真。
位运算
A = 0011 1100
B = 0000 1101
A&B = 0000 1100 //(按位比较相同返回值,不同返回0)
A|B = 0011 1101 //(都是0则为0,都是1则为1,如果有一个1,直接为1)
A^B = 0011 0001 //(如果相同就位0,否则就位1)
~B = 1111 0010 //(取反)左移 << *2 ;
右移 >> /2。
JavaDoc命令
通过cmd窗口javadoc 参数 Java文件 生成自己的API文档
接收键盘输入
Scanner scanner = new Scanner(System.in);
//凡是属于IO流的类必须关闭资源,如果不关闭会一直占用资源。通过Scanner类的next()与nextLine()方法获取输入的字符串,在读取前我们一般需要使用hasNext()与hasNextLine()判断是否还有输入的数据。

循环语句打印三角形

实参、形参
public static void main(String [] args){
int sum = add(1,2); //实际参数:实际调用传递给他的参数
}
//方法(小括号内的是形式参数,用来定义作用的)
public static int add(int a,int b){
return a+b;
}
可变参数

数组
数组的四个基本特点
二维数组
二维数组内的元素是数组
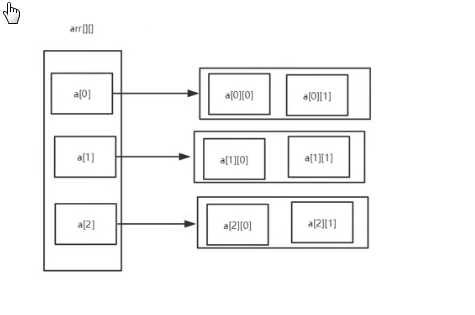
冒泡排序
冒泡排序,两层循环,外层冒泡轮数,里层一次比较
比较数组中,两个相邻的元素,如果第一个数比第二个数大,我们就交换他们的位置,每一次比较都会产生一个最大的,或者最小的数字,下一轮则可以少一次排序,依次循环,知道结束。
int temp = 0;
for(int i = 0;i<array.length-1;i++){
for(int j=0;j<array.length-1-i;j++){
if(array[j]>array[j+1]){
temp = array[j+1];
array[j+1]= array[j];
array[j] = temp;
}
}
}
面向对象编程的本质就是:以类的方式组织代码,以对象的组织(封装)数据。
面向对象的三大特性:
super 和 this:
this:
代表的对象不同:
? this:本身调用者这个对象
? super:代表父类对象的应用
前提:
? this:没有继承也可以使用
? super:只能在继承条件下才可以使用
构造方法
? this( ):本类的构造方法
? spuer( ):父类中的构造方法
重写:需要有继承关系,子类重写父类的方法!(都相同)
动态编译、类型、可扩展性
同一方法可以根据发送对象的不同而采用多种不同的行为方式(同一个接口,使用不同的实例而执行不同的操作)。
多态存在的条件:
多态是方法的多态,属性没有多态
注意:
static 修饰的方法不能被重写,static 修饰的方法属于类
final 修饰的方不能被重写
private 修饰的方法不能被重写
static 修饰:属性、方法、代码块
static 方法:归属于类,可以 (类名.方法 )调用
static 代码块:在构造方法前执行而且只执行一次。
静态的只能访问静态的,不能访问非静态的(如果静态的访问非静态的需要先创建对象);
非静态的可以访问静态的;
静态方法和非静态方法的区别:
? 静态方法:方法的调用只和左边定义的数据类型有关
//父类的引用指向子类
B b = new A();
b.test();// B的方法(父类的方法)
? 非静态方法:子类重写父类的方法后执行子类,如果子类没有重写则还是执行父类的方法。
abstract 可以修饰类,方法;
abstract 关键字修饰的类为抽象类:
abstract 修饰的方法为抽象方法:
? 只有方法的名字,没有方法的实现,不用写大括号,直接分号结尾即可。
接口 用 interface 关键字定义
接口的作用:


假如要捕获多个异常:从小到大捕获!
throw 主动抛出异常,一般在方法中使用
public void test(int a,int b){
if(b==0){
throw new ArithmeticException();//主动抛出异常
}
System.out.println(a/b);
}
throws 假设在方法中,处理不了这个异常,在方法上抛出
public void test(int a,int b) throws ArithmeticException{
if(b==0){
}
System.out.println(a/b);
}
Throw 和 Throws 的区别:
? 共同点:两者在抛出异常时,抛出异常的方法并不负责处理,顾名思义,只管抛出,由调用者负责处理。
? 区别:
为什么要使用集合而不是数组
集合和数组的相似点:
数组的缺点:
集合框架
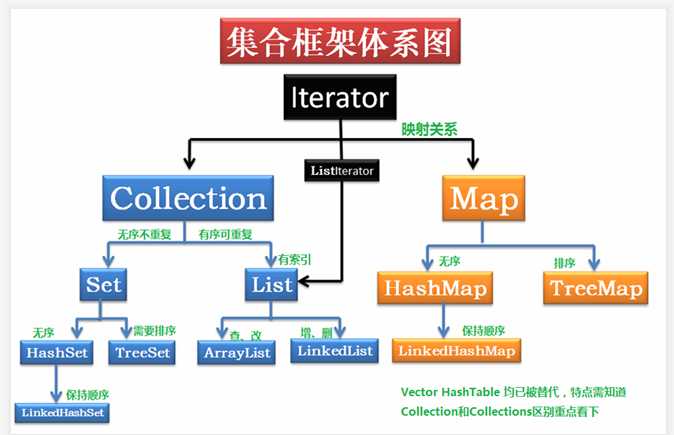
list
ArrayList 线性表中的顺序表:
注意:ArrayList 按照**索引**查询元素快,如果按照需求查则慢;
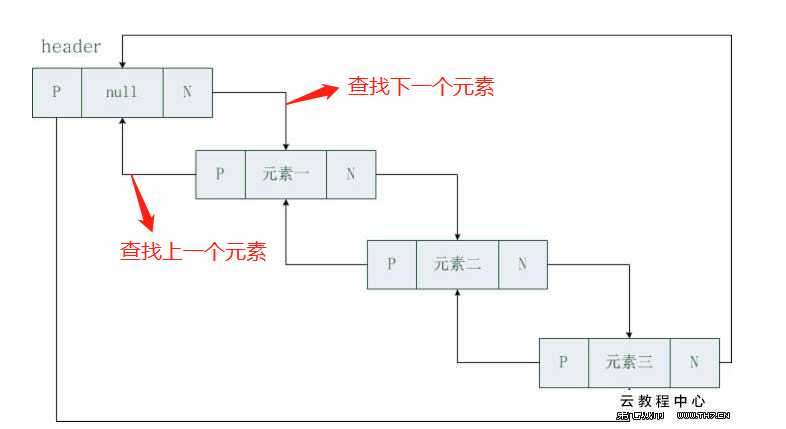
LinkedList 线性表中双向链表:
双向链表储存结构图第一个hander为头指针,不保存数据,每保存一个元素的同时保存了该元素的下一个元素地址和前一个元素的地址;
总结分析:
/**
* 功能: 存储多个分数
* 技能:ArrayList的使用
*
* 分析:
* 多个分数: 集合
* 分数不唯一(可以相同),有顺序(先后顺序):List
*
遍历Arraylist集合的三种方法:
1.for
2.foreach
3.iterator迭代器
* 注意:
* 1.集合中只能放对象,不能放基本数据类型;(基本数据类型可以使用包装类放入,自动装箱)
* 数组中即可以放对象,也能放基本数据类型;
* 2.ArrayList:不唯一、有序(索引的顺序)
* 3.ArrayList:常用的方法
* list.add(19); //add方法将元素添加到集合的末尾;
* list.add(3, 88); //将元素添加到指定位置,底层发生了大量的元素向后移动,效率低
* list.addAll(list2); //将多个数据添加到集合的最后
* list.addAll(0,list2); //根据索引将多个元素添加到最前面
*
* list.size(); //元素的个数;
* list.get(i); //获取第i个元素
* list.iterator(); //将数据交给迭代器遍历
* list.set(1,78); //根据索引修改
* list.remove(3); //根据索引删除数据
list.remove(new Integer(78)); //根据内容删除
list.toArray(); //集合转数组
* 缺点:
* 1.繁琐:遍历取出元素时需要强制转换,否则是Object类型
* int object = (int)list.get(i)
* 2.不安全:添加元素的时候可以加入不同的数据类型
* list.add("abc");
* 解决:使用泛型
* 泛型的好处
* 1.简单
* 2.安全
* @author Administrator
*
*/
* 功能: 存储多个分数
* 技能:LinkedList的使用
*
* 不变的是什么
* 1.运行结果不变
* 2.代码相同
*
* 变化的是什么
* 1.底层结构不同
* ArrayList:连续的空间 数组
* LinkedList:不连续的空间 双向链表
*
* 2.操作的过程不同
* list.add(3, 88);
* ArrayList:大量的后移元素,效率低下
* LinkedList:创建新的节点储存88,并修改前后两个节点的指针,加入到第三个位置 效率比较高
*
* 到底该使用ArrayList还是LinkedList
* 1.随机访问频率高,建议使用ArrayList
* 2.添加、删除操作比较多,建议使用LinkedList
*
* LinkedList 增加了对首尾节点的操作
*
特点:无序、唯一(不重复)
HashSet
LinkedHashSet
TreeSet
采用二叉树(红黑树)的储存结构;
优点:有序、查询速度比List快(按照内容查询);
缺点:查询速度没有HashSet快;
按照内容查询速度的快慢:
哈希表-->树--->线性表 (由快到慢)
二叉树:
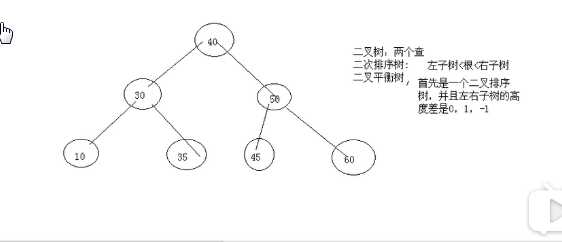
哈希表的主结构:
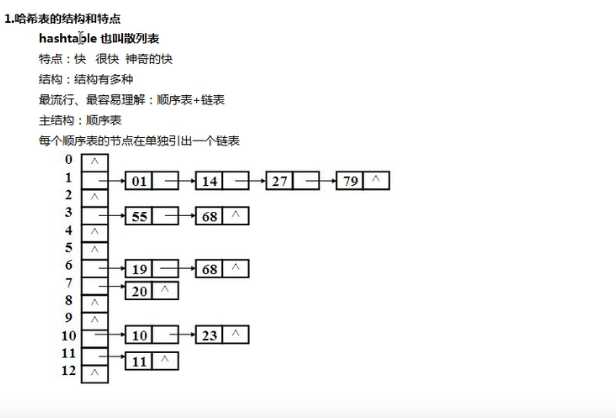
不是基于内容比较的,而是基于计算的,可以直接计算到存储的地址并访问;
例:
* 使用Set来存储过程
*
* HashSet 底层结构是哈希表 速度快 无序 唯一
* LinkedHashSet 底层结构是哈希表+链表 有序的(存储顺序)唯一
* TreeSet 底层结构是红黑树(二叉树、二叉排序树、二叉平衡树)速度比较快,介于线性表和哈希表之间
* 有序(自然顺序 大小顺序) 唯一
*
* set的遍历
* 1.for-each
* 2.Iterator
* 3.不能使用for循环,因为没有get(i)
*
* set相比Collection并没有增加方法
* 但是List相比Collection增加了一些和索引相关的的方法
* add(i,elem);
* remove(i);
* set(i,elem);
* get(i);

某个类,比如String、Student内部比较器只有一个,只能指定比较的规则,一般是使用频率最高的规则;
如果希望指定其他的更多比较规则,请使用外部比较器 外部比较器可以有多个
添加数据共三步:
如果指定位置已经存在元素,发生了冲突,(冲突不能完全避免,只能减少)
发生了冲突之后就要调用equals( ) ,判断元素内容是否相同,如果相同,不添加(唯一);
如果不相同,沿着链表继续比较,比较到最后也不相同,添加一个新的元素。
存入哈希表三种情况:

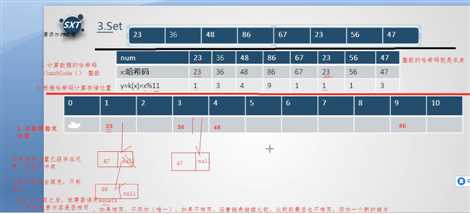
储存结构点睛之笔

哈希表的查询和删除速度也快
也是通过三步,基本上和存入差不多
map
HashMap
LinkedHashMap
TreeMap
有序 速度没有hash快
Map集合详解:
* 存储国家简称和国家名的映射
*
* Map:都是存储key-value键值对
*
* HaspMap:底层结构是哈希表 查询快、添加开、无序
* key: 无序、唯一、HashSet
* value: 无序、不唯一 Collection
*
*LinkedHashMap:底层结构是哈希表+链表 查询快、添加快、有序
* key:有序(添加顺序)唯一 LinkedHashSet
* value:无序、不唯一 Collection
*
*TreeMap: 底层结构是红黑树 速度介于哈希表和线性表之间,有序
* key:有序(自然顺序)唯一、TreeSet
* value:无序 不唯一 Collection
*
* 常用方法
* map.put("us", "America");
* map.get("us");
* map.size();
* map没有迭代器,无法使用迭代器直接遍历,需要先变成Set,再遍历Set
*
* Entry:Map接口中的内部接口
*
* map.keySet; 取key值,根据key取value值
* map.entrySet();取key-value;
*
* Set<Entry<String,String>> entrySet = map.entrySet();
Iterator<Entry<String, String>> it = entrySet.iterator();
旧的集合类

有总结不对的地方欢迎多多指教相互学习^_^
原文:https://www.cnblogs.com/liuwei0301/p/12003734.html