单机 -> 可复制集 -> 分片集群
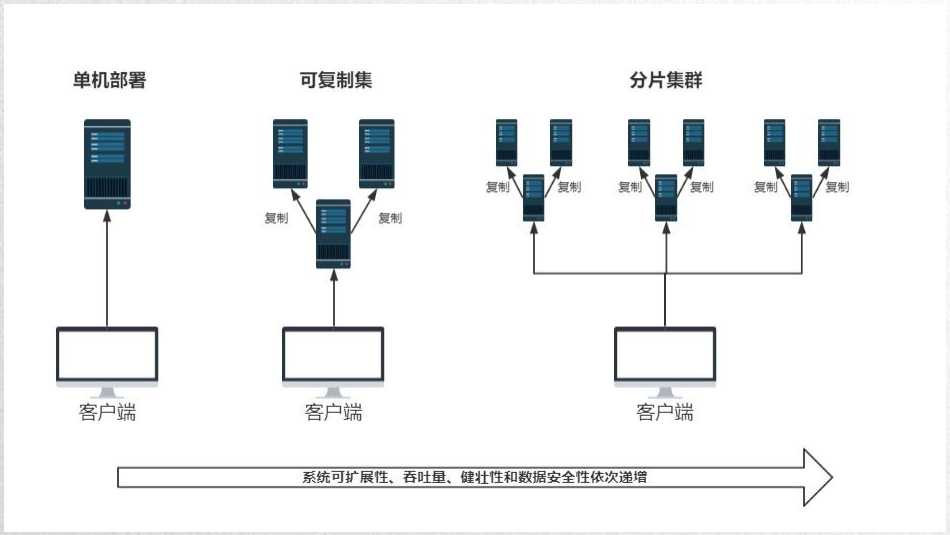
可复制集是多台MongoDB节点之间分布和维护数据的方法;它可以将数据从一个节点复制到其它节点,并在修改时进行数据同步。
在3.0之前的版本这叫做主从复制,3.0+推荐使用这个可复制集。
1、为什么要使用复制集,有什么好处?
2、可复制集的搭建:
a、安装3个及以上的MongoDB
b、配置mongodb.conf
replication: // 集群名称 replSetName: name // oplog大小 oplogSizeMB: 50
c、在primary节点上运行可复制集的初始命令
// 复制集初始化 rs.initiate({ ‘_id‘:‘name‘, ‘version‘:1, ‘members‘:[{‘_id‘:0, host:‘ip:port‘}] }) // 添加子节点 rs.add(‘ip:port‘) rs.add(‘ip2:port‘)
d、运行rs.status()或rs.isMaster()命令查看复制集状态。
3、可复制集架构及原理:
a、oplog:保存操作记录及时间戳。
b、数据同步:主从保持长轮询
c、心跳机制:每2秒进行一次心跳检测,发现故障后会进行选举和故障转移。
d、选举制度:当主节点故障后,其余节点根据优先级和bully算法选举出新的主节点,在此之间集群服务是只读的。
对于MongoDB来说,主节点一般用于写数据,从节点用于读数据,且主节点也并不是固定的(当主节点宕机后会选举出一个新的主节点),所以在生产环境时客户端不能直连主节点。
所以我们需要配置集群节点:
<mongo:mongo-client replica-set="ip1:port1,ip2:port2,ip3:port3"> <mongo:client-options read-preference="SECONDARY_PREFERRED"/> </mongo:mongo-client>
通过read-preference参数控制读写分离方式,其类型有以下几种:
为何要使用分片架构:
分片架构的三个主要角色:
1、分片:分片架构中唯一存储数据的角色,它可以是单台服务器也可以是一个可复制集(生成环境推荐使用可复制集),每个分区上只存储部分数据。
2、路由:由于分片只存储部分数据,所以需要一个工具(工具为mongos)来讲请求处理到对应的分片中,而路由就充当这一角色。
3、配置服务器:存储集群的元数据(数据库、集合、分片的位置范围等日志信息),配置服务器最低3台。
分片架构的搭建:
1、分片服务器的配置(分片的三台服务器都需要执行)
./mongod --port 27010 --dbpath /usr/local/mongodb/data/db/27010 --logpath /usr/local/mongodb/logs/mongodb0.log --fork -- shardsvr
2、config服务器集群配置
./mongod --port 27011 /usr/local/mongodb/data/db/27011 --logpath /usr/local/mongodb/logs/mongodb1.log --fork --logappend --configsvr --replSet=cfrs1 rs.initiate({ ‘_id‘:‘cfrs1‘, ‘version‘:1, ‘members‘:[{ ‘_id‘:0 ‘host‘:‘主节点ip:主节点port‘ }] }) rs.add("从节点1ip:从节点1port") rs.add("从节点2ip:从节点2port")
3、启动mongos路由
./mongos --configdb cfrs1/host1,host2,host3 --port 27016 --logpath /usr/local/mongodb/logs/mongodb6.log --fork --logappend
4、配置sharding
连接mongos,增加sharding
use admin sh.addShard("host1") sh.addShard("host2") sh.addShard("host3") // 设置db启动分片 sh.enableSharding(‘dbName‘) // 配置collection分片键 sh.shardCollection( ‘dbName.collectionName‘, {‘分片键字段名‘:1} )
分片键选择的一些建议:
1、不推荐点:
2、推荐点:
1、尽量选取稳定新版本64位的MongoDB。
2、数据模式设计;提倡单文档设计,将关联关系作为内嵌文档或者内嵌数组;当关联数据量较大时,考虑通过表关联实现,dbref或者自定义实现关联。
3、避免使用skip跳过大量数据
4、避免单独使用不适用索引的查询符($ne、$nin、$where等)。
5、根据业务场景选择合适的写入策略,在数据安全和性能之间找到平衡点。
6、建立索引很重要。
7、生产环境中建议打开profile,便于优化系统性能。
8、生产环境中建议打开auth模式,保障系统安全。
9、不要将MongoDB和其他服务部署在同一台机器上(虽然MongoDB 占用的最大内存是可以配置的)。
10、单机一定要开启journal日志,数据量不太大的业务场景中,推荐多机器使用副本集,并开启读写分离。
11、分片键的注意事项。
原文:https://www.cnblogs.com/bzfsdr/p/12000811.html