数据集介绍
关于交通标识的数据集
一共有43个类别


1从数字的每一个类别中随机抽取一张图片观察

可以看到图片中存在一些因素可能会对我们模型的准确度造成影响。
1图片有亮有暗,这可能是时间早晚 或者天气的影响
2凸显有大有小,这应该是由于摄像头距离标示牌的远近不同
3角度视角不同 有的图片是是倾斜的
4有些图片很模糊不清晰
5可能会有遮挡
2查看每个类别的数据量分布
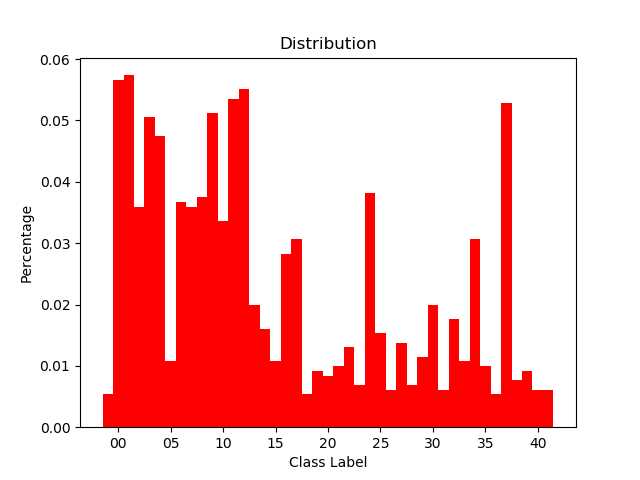
有的数据的量占比较少,我们可以考虑扩充数据量的方式来增加数据量
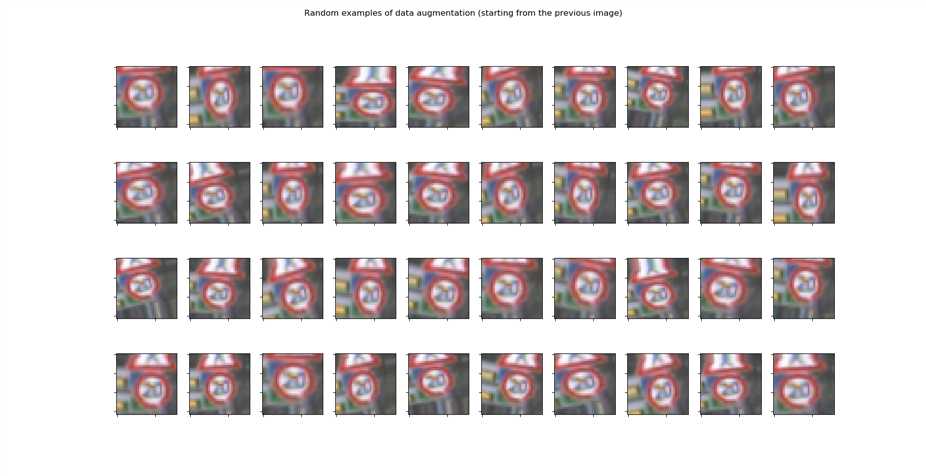
3我们对数据进行数据增强
image_datagen = ImageDataGenerator(rotation_range=15., zoom_range=0.2, width_shift_range=0.1, height_shift_range=0.1)
这里对每一张图像 以15度 来进行旋转 0.2的随机缩放 0.1的水平或垂直平移。
查看一下 数据增强的结果。
原图:

数据增强结果:
4数据预处理
1模型对交通牌的识别 主要是根据 交通牌的形状经识别的。 我们 这里不考虑色彩。我们在YUV色彩空间上进行图片的识别训练。这里只考虑亮度。
2对图像进行直方图均值化处理
3均值化归一化
def get_mean_std_img(X): X = np.array([np.expand_dims(cv2.cvtColor(rgb_img, cv2.COLOR_RGB2YUV)[:, :, 0], 2) for rgb_img in X]) X = np.array([np.expand_dims(cv2.equalizeHist((np.uint8(img))),2)for img in X]) X = np.float32(X) mean_img = np.mean(X, axis=0) std_img = (np.std(X, axis=0)) #+ np.finfo(‘floar32‘).eps #32wei fudianshu zuixiaozhi return mean_img, std_img def preprocess_features(X, mean_img, std_img): # convert from RGB to YUV #YUV 亮度 色度 浓度 X = np.array([np.expand_dims(cv2.cvtColor(rgb_img, cv2.COLOR_RGB2YUV)[:, :, 0], 2) for rgb_img in X]) #zhifangtujunyunhua X = np.array([np.expand_dims(cv2.equalizeHist((np.uint8(img))),2)for img in X]) X = np.float32(X) #standardize features X -= mean_img X /= std_img return X
5网络模型
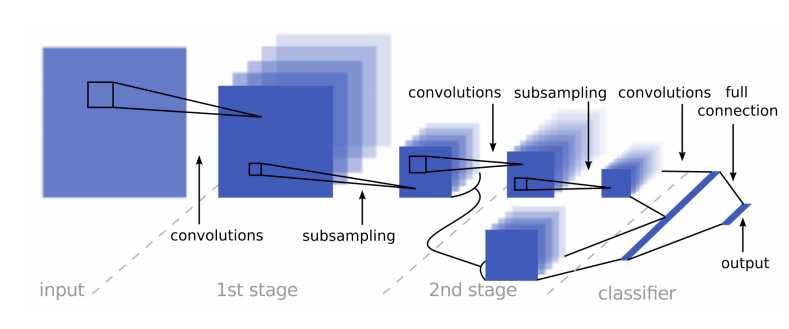
http://yann.lecun.com/exdb/publis/pdf/sermanet-ijcnn-11.pdf
这个网络结构中有2个分支,其中一个分支比另一分支多进行一次卷积操作,之后把两个特征图合并。论文中指出这样做的好处是网络可以在两个不同尺度的特征上进行学习。
这样更利于模型提高准确度。
实现:
def get_model(dropout_rate = 0.0): input_shape = (32, 32, 1) input = Input(shape=input_shape) cv2d_1 = Conv2D(64, (3, 3), padding=‘same‘, activation=‘relu‘)(input) pool_1 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(cv2d_1) dropout_1 = Dropout(dropout_rate)(pool_1) flatten_1 = Flatten()(dropout_1) cv2d_2 = Conv2D(64, (3,3), padding=‘same‘, activation=‘relu‘)(dropout_1) pool_2 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(cv2d_2) cv2d_3 = Conv2D(64, (3,3), padding=‘same‘, activation=‘relu‘)(pool_2) dropout_2 = Dropout(dropout_rate)(cv2d_3) flatten_2 = Flatten()(dropout_2) concat_1 = concatenate([flatten_1, flatten_2]) dense_1 = Dense(64, activation=‘relu‘)(concat_1) output = Dense(43, activation=‘softmax‘)(dense_1) model = Model(inputs=input, outputs=output) # compile model model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘]) # summarize model model.summary() return model
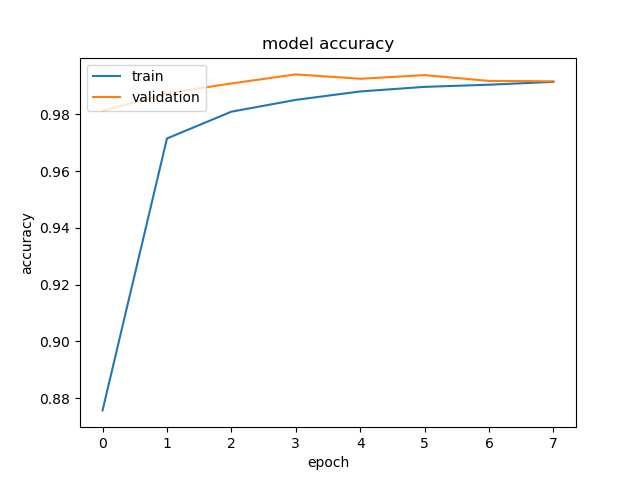
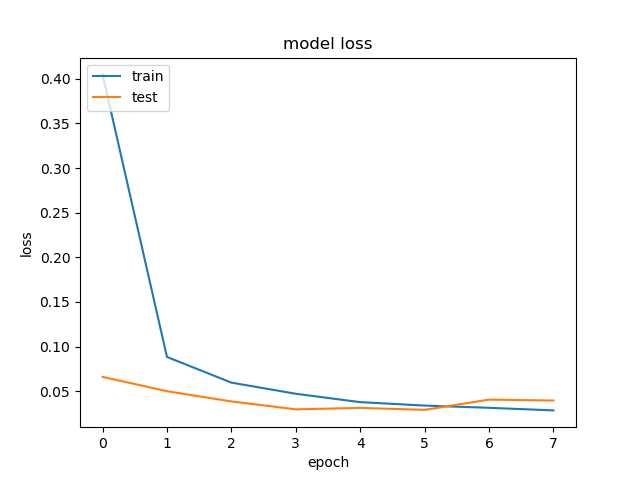
6训练和结果
history = model.fit_generator(image_datagen.flow(x_train, y_train, batch_size=128), steps_per_epoch=5000, validation_data=(x_validation, y_validation), epochs=8, callbacks=callbacks_list, verbose=1)
原文:https://www.cnblogs.com/IAMzhuxiaofeng/p/12011428.html