参考文章:https://blog.csdn.net/weixin_42749767/article/details/82770563
先介绍xml.dom.minidom包,有一个读写的例子
read_write_xml.py

from xml.dom.minidom import parse import xml.dom.minidom import os def is_xml_exist(xml_path): xml_exist = os.path.exists(xml_path) if not xml_exist: return False return True """ movie.xml <collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>War, Thriller</type> <format>DVD</format> <year>2003</year> <rating>PG</rating> <stars>10</stars> <description>Talk about a US-Japan war</description> </movie> <movie title="Transformers"> <type>Anime, Science Fiction</type> <format>DVD</format> <year>1989</year> <rating>R</rating> <stars>8</stars> <description>A schientific fiction</description> </movie> <movie title="Trigun"> <type>Anime, Action</type> <format>DVD</format> <episodes>4</episodes> <rating>PG</rating> <stars>10</stars> <description>Vash the Stampede!</description> </movie> <movie title="Ishtar"> <type>Comedy</type> <format>VHS</format> <rating>PG</rating> <stars>2</stars> <description>Viewable boredom</description> </movie> </collection> """ def read_movie_xml(): path = "movie.xml" if not is_xml_exist(path): print("%s is not exist" % path) else: # 使用minidom解析器打开XML文档 open_xml = parse(path) root_node = open_xml.documentElement shelf_attrib = "shelf" if root_node.hasAttribute(shelf_attrib): print("Lable: %s\tAttrib: %s\t\tValue: %s" % ( root_node.nodeName, shelf_attrib, root_node.getAttribute(shelf_attrib))) print("") # 在集合中获取所有电影 movie_node = "movie" movies = root_node.getElementsByTagName(movie_node) # 打印每部电影的详细信息 for movie in movies: print("**** Movie ****") if movie.hasAttribute("title"): print("Title: %s" % movie.getAttribute("title")) type_movie = movie.getElementsByTagName(‘type‘)[0] print("Type: %s" % type_movie.childNodes[0].data) format_movie = movie.getElementsByTagName(‘format‘)[0] print("Format: %s" % format_movie.childNodes[0].data) rating_movie = movie.getElementsByTagName(‘rating‘)[0] print("Rating: %s" % rating_movie.childNodes[0].data) descrip_movie = movie.getElementsByTagName(‘description‘)[0] print("Rating: %s" % descrip_movie.childNodes[0].data) print("") if __name__ == "__main__": read_movie_xml()
运行结果:
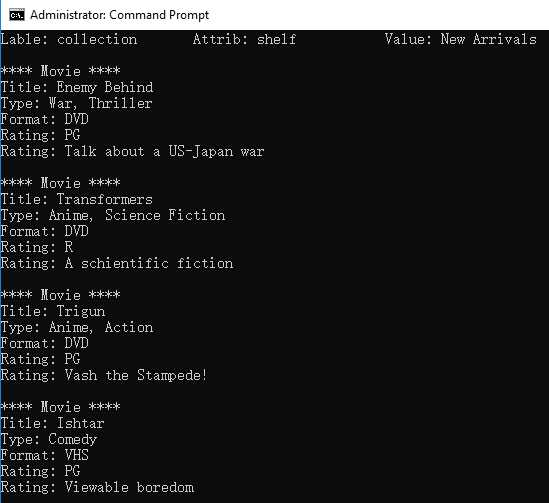
用到的知识点:
1. 导入xml包:
from xml.dom.minidom import parse
2. 打开xml文件:
open_xml = parse(path)
root_node = open_xml.documentElement
3. 获取节点名称:
root_node.nodeName
4. 判断节点属性是否存在:
root_node.hasAttribute(shelf_attrib)
5. 获取节点属性:
root_node.getAttribute(shelf_attrib)
6. 获取子节点对象:
root_node.getElementsByTagName(movie_node)
7. 获取文本节点的文本信息:
type_movie.childNodes[0].data
以上语句务必正确使用,运行第二步,xml必须已经存在,运行第六步,子节点的标签必须存在,运行第七步,此节点必须是文本节点,否则都会出现异常。
原文:https://www.cnblogs.com/smart-zihan/p/12015192.html
