Python 代码优化常见技巧
代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构、优化、扩展以及文档相关的事情通常需要消耗 80% 的工作量。优化通常包含两方面的内容:减小代码的体积,提高代码的运行效率。
改进算法,选择合适的数据结构
一个良好的算法能够对性能起到关键作用,因此性能改进的首要点是对算法的改进。在算法的时间复杂度排序上依次是:
O(1) -> O(lg n) -> O(n lg n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
算法的时间复杂度对程序的执行效率影响最大,在 Python 中可以通过选择合适的数据结构来优化时间复杂度,如 list 和 set 查找某一个元素的时间复杂度分别是 O(n)和 O(1)。不同的场景有不同的优化方式,总得来说,一般有分治,分支界限,贪心,动态规划等思想。
每种编程语言都会强调需要优化循环。对循环的优化所遵循的原则是尽量减少循环过程中的计算量,有多重循环的尽量将内层的计算提到上一层。当使用 Python 的时候,你可以依靠大量的技巧使得循环运行得更快。然而,开发者经常漏掉的一个方法是:
避免在一个循环中使用点操作。每一次你调用方法 str.upper,Python 都会求该方法的值。然而, 如果你用一个变量代替求得的值,值就变成了已知的,Python 就可以更快地执行任务。优化循环的关键,是要减少 Python 在循环内部执行的工作量,因为 Python 原生的解释器在那种情况下,真的会减缓执行的速度。(注意:优化循环的方法有很多,这只是其中的一个。例如,许多程序员都会说,列表推导是在循环中提高执行速度的最好方式。这里的关键是,优化循环是程序取得更高的执行速度的更好方式之一。)
为进行循环优化前
from time import time
t = time()
lista = [1,2,3,4,5,6,7,8,9,10]
listb =[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.01]
for i in range (1000000):
for a in range(len(lista)):
for b in range(len(listb)):
x=lista[a]+listb[b]
print("total run time:")
print(time()-t)
#现在进行如下优化,将长度计算提到循环外,range 用 xrange 代替,同时将第三层的计算 lista[a] 提到循环的第二层。
# 循环优化后
from time import time
t = time()
lista = [1,2,3,4,5,6,7,8,9,10]
listb =[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.01]
len1=len(lista)
len2=len(listb)
for i in xrange (1000000):
for a in xrange(len1):
temp=lista[a]
for b in xrange(len2):
x=temp+listb[b]
print("total run time:")
print(time()-t)
#上述优化后的程序其运行时间缩短为 102.171999931。在清单 4 中 lista[a] 被计算的次数为 1000000*10*10,而在优化后的代码中被计算的次数为 1000000*10,计算次数大幅度缩短,因此性能有所提升。
#充分利用 Lazy if-evaluation 的特性
#python 中条件表达式是 lazy evaluation 的,也就是说如果存在条件表达式 if x and y,在 x 为 false 的情况下 y 表达式的值将不再计算。因此可以利用该特性在一定程度上提高程序效率。
#利用 Lazy if-evaluation 的特性
from time import time
t = time()
abbreviations = [‘cf.‘, ‘e.g.‘, ‘ex.‘, ‘etc.‘, ‘fig.‘, ‘i.e.‘, ‘Mr.‘, ‘vs.‘]
for i in range (1000000):
for w in (‘Mr.‘, ‘Hat‘, ‘is‘, ‘chasing‘, ‘the‘, ‘black‘, ‘cat‘, ‘.‘):
if w in abbreviations:
#if w[-1] == ‘.‘ and w in abbreviations:
pass
print("total run time:")
print(time()-t)
因为 GIL 的存在,Python 很难充分利用多核 CPU 的优势。但是,可以通过内置的模块
multiprocessing 实现下面几种并行模式:
多进程:对于 CPU 密集型的程序,可以使用 multiprocessing 的 Process,Pool 等封装好的类, 通过多进程的方式实现并行计算。但是因为进程中的通信成本比较大,对于进程之间需要大量数据交互的程序效率未必有大的提高。
多线程:对于 IO 密集型的程序,multiprocessing.dummy 模块使用 multiprocessing 的接口封装 threading,使得多线程编程也变得非常轻松(比如可以使用 Pool 的 map 接口,简洁高效)。
分布式:multiprocessing 中的 Managers 类提供了可以在不同进程之共享数据的方式,可以在此基础上开发出分布式的程序。
不同的业务场景可以选择其中的一种或几种的组合实现程序性能的优化。
set 的 union,intersection,difference 操作要比 list 的迭代要快。因此如果涉及到求 list 交集,并集或者差的问题可以转换为 set 来操作。
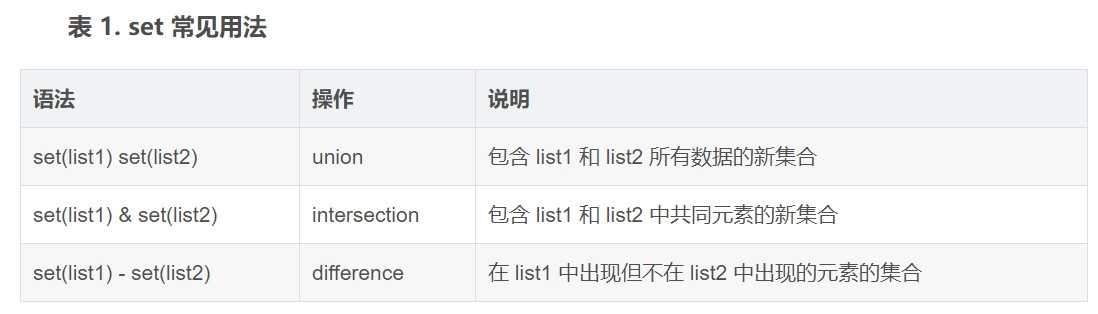
字符串的优化
python 中的字符串对象是不可改变的,因此对任何字符串的操作如拼接,修改等都将产生一个新的字符串对象,而不是基于原字符串,因此这种持续的 copy 会在一定程度上影响 python 的性能。对字符串的优化也是改善性能的一个重要的方面,特别是在处理文本较多的情况下。字符串的优化主要集中在以下几个方面:
列表解析要比在循环中重新构建一个新的 list 更为高效,因此我们可以利用这一特性来提高运行的效率。
小试牛刀一起来优化吧!
方案一:
方案二:
上面是使用python的内建函数itertools.permutations对于只有9个元素的全排列速度上是惊人的。
如果是我们自己来写全排列逻辑,可以是下面这样的:
def full_permutation(l):
if (len(l) <= 1):
return [l]
r = []
for i in range(len(l)):
s = l[:i] + l[i + 1:] # 将l的前三项以及l的第i+1后的字串赋给s
p = full_permutation(s)
for x in p:
r.append(l[i: i + 1] + x)
return r
所有在项目中还是建议使用Python内建的全排列函数,其中的第二个参数可以是1-9之间的任何一个整数,非常方便。2.
2、遍历文件夹下所有子文件夹和文件
在Python中可以很方便地对文件目录进行循环遍历,检查文件及目录,代码如下:
import os
import os.path
def cycle_visiting(root_dir=None):
for parent, folder_names, file_names in os.walk(root_dir):
for folder_name in folder_names:
print(‘folder: ‘ + folder_name)
for file_name in file_names:
print(‘file: ‘ + os.path.join(parent, file_name))
如果你有其他语言的编程功底,可能你已对进制转化十分熟悉。不过我这里要说的进制转化可不是简单从十进制转化为二进制或是转成十六进制。下面你可以试着来解决下面几个问题:
a.将a = ‘ff‘的十六进制数转成十进制的255
b.将a = 14的十进制数转成十六进制的0e
解决方法:
a.这里需要用一个参数指明原来的进制数
decstr = int(a, 16)
b.这里需要用一个切片操作用来去掉前缀‘0x‘
decstr = hex(a)[2:]
if len(decstr) % 2 == 1:
decstr = ‘0‘ + decstr
首先需要import两个模块:socket和struct
1.将ip1 = ‘172.123.156.241‘转化为ip2 = 2893782257L
ip2 = socket.ntohl(struct.unpack("I",socket.inet_aton(ip1))[0])
2.将ip2 = 2893782257L转化为ip1 = ‘172.123.156.241‘
ip1 = socket.inet_ntoa(struct.pack(‘I‘,socket.htonl(ip2)))
可以通过两种方式来解决这个问题,分别如下:
方法一:
方法二:
有时我们在对序列进行迭代的时候,不单单是只要知道序列中的值,还想要知道这个值在序列的什么位置。
如果要使用代码实现,的确不难。不过会显得多余,因为Python已经为我们做了这些工作。如下:
def test_enumerate():
array = [1, 2, 3, 4, 5, 6]
for index, data in enumerate(array):
print("%d: %d" % (index, data))
t = test_enumerate()
我们知道Python中是不支持自增操作的。所以,你是不是就会以为这里的++i会抛出一个语法错误呢?
很可惜,这里并不会抛出语法错误。对于i++的确是有这样的问题,不过对于++i则不会。例如在PyCharm编辑器中,我们可以看到如下现象:
我们可以看到PyCharm对a++抛出了一个错误提示,对于++a则是一个警告。
原因是在Python里,++a会被看成是+(+a),也就是说,“+”被理解成了一个正符号。所以,++a的结果还是a。同理,--a的结果也是a.
在Python中可以很方便地对文件目录进行循环遍历,检查文件及目录,代码如下:
原文:https://www.cnblogs.com/limingqi/p/12016734.html