目录
信息抽取(information extraction),即从自然语言文本中,抽取出特定的事件或事实信息,帮助我们将海量内容自动分类、提取和重构。这些信息通常包括实体(entity)、关系(relation)、事件(event)。例如从新闻中抽取时间、地点、关键人物,或者从技术文档中抽取产品名称、开发时间、性能指标等。
显然,信息抽取任务与命名实体识别任务类似,但相对来说更为复杂。有时,信息抽取也被称为事件抽取(event extraction)。
与自动摘要相比,信息抽取更有目的性,并能将找到的信息以一定的框架展示。自动摘要输出的则是完整的自然语言句子,需要考虑语言的连贯和语法,甚至是逻辑。有时信息抽取也被用来完成自动摘要。
由于能从自然语言中抽取出信息框架和用户感兴趣的事实信息,无论是在知识图谱、信息检索、问答系统还是在情感分析、文本挖掘中,信息抽取都有广泛应用。
信息抽取主要包括三个子任务:
由于工作上的原因,先对关系抽取进行总结,实体链指部分之后有时间再补上吧。
关系抽取通常再实体抽取与实体链指之后。在识别出句子中的关键实体后,还需要抽取两个实体或多个实体之间的语义关系。语义关系通常用于连接两个实体,并与实体一起表达文本的主要含义。常见的关系抽取结果可以用SPO结构的三元组来表示,即 (Subject, Predication, Object),如
中国的首都是北京 ==> (中国, 首都, 北京)
关系抽取的分类:
原文链接:https://www.aclweb.org/anthology/C14-1220/
在深度学习兴起之前,关系抽取的传统方法依赖于特征工程,而这些特征通常由预先准备的NLP系统得到,这容易在构造特征的过程中造成误差累积,阻碍系统性能。
该论文属于早期使用深度卷积网络模型解决关系抽取任务的经典论文。该论文将关系抽取问题定义为:给定一个句子 \(S\) 和名词对 \(e_1\) ?和 $e_2 $?,判断 \(e_1?\) 和 \(e_2\) ?在句子中的关系,即将关系抽取问题等效为一个关系分类问题。与传统的方法相比,该模型只需要将整个输入句子以及简单的词信息作为输入,而不需要认为构造特征,就能得到非常好的效果。模型的主要架构如下所示:
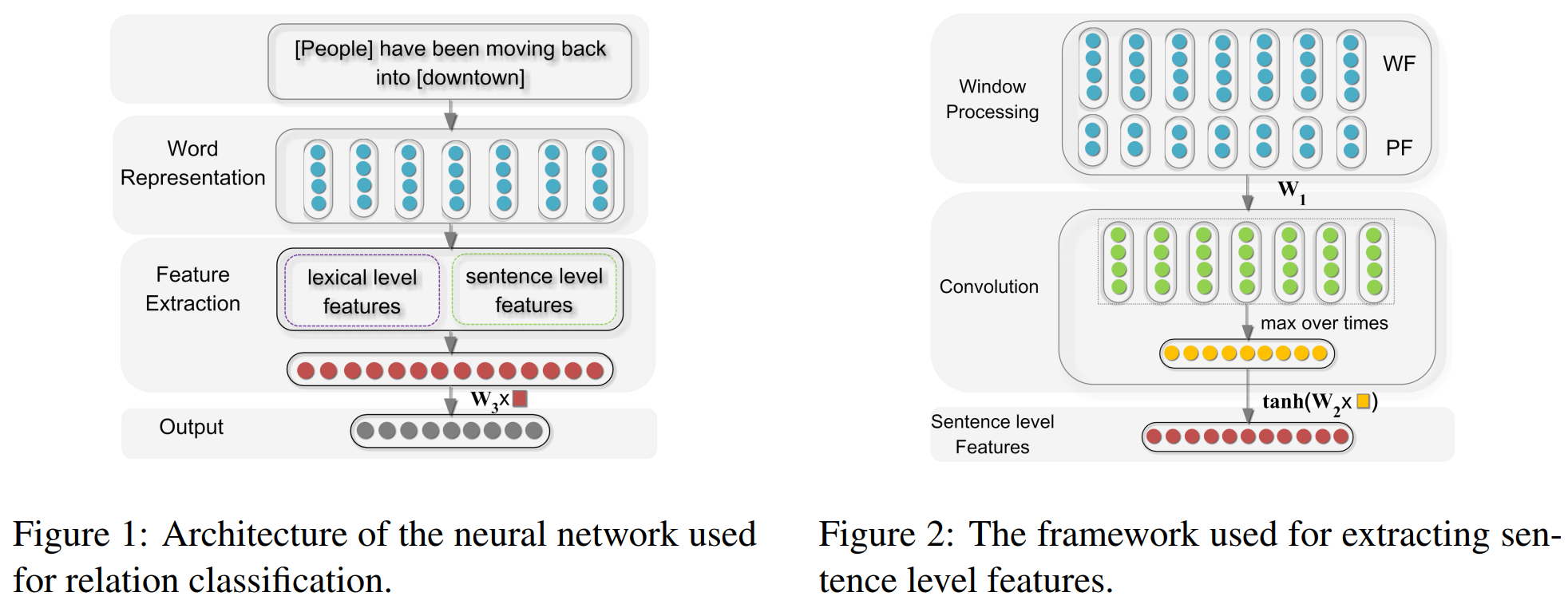
模型的输入主要包括两个部分,即词汇级别特征以及句子级别特征:
lexical level features:词汇级别特征包括实体对\(e_1\) 和 \(e_2\) 的词嵌入向量,\(e_1\) 和 \(e_2\) 的左右两边词的词嵌入向量,以及一个 WordNet 上位词向量。WordNet 上位词特征指的是 \(e_1\) 和 \(e_2\) 同属于哪一个上位名次,如“狗”和“猫”的上位词可以是“动物”或者“宠物”,具体需要参考的 WordNet 词典是怎样构建的。直接将上述的5个向量直接拼接构成词汇级别的特征向量 \(l\)
将词汇级别特征与句子级别特征直接拼接,即\(f = [l, g]\),最终将其送入分类器进行分类。
该模型将关系抽取任务利用神经网络进行建模,利用无监督的词向量以及位置向量作为模型的主要输入特征,一定程度上避免了传统方法中的误差累积。但仍然有 lexical level feature 这个人工构造的特征,且 CNN 中的卷积核大小是固定的,抽取到的特征十分单一
原文链接:https://www.aclweb.org/anthology/W15-1506/
该论文首先提出关系分类和关系抽取两个主要任务:
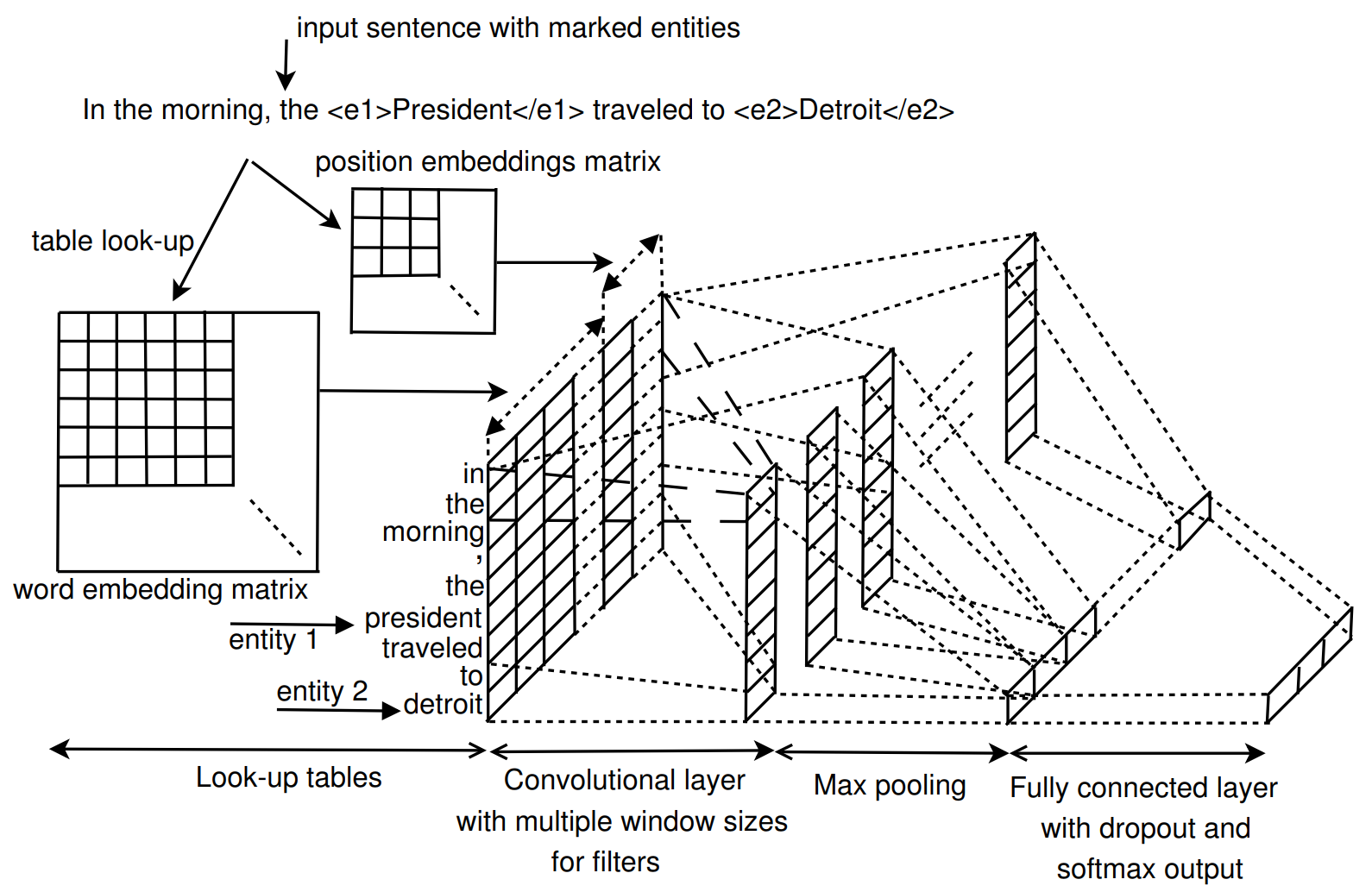
论文主要关注的是关系抽取任务。与 Model 1 类似,同样是利用卷积神经网络作为主要的特征抽取模型,模型细节如下所示:
该论文的模型输入完全没有人工特征,且使用多宽度大小的卷积核进行特征抽取,相对于 Zeng 的效果来说仅提升了 \(0.1\%\),个人认为提升的主要关键点在于多粒度大小的卷积核上,而 lexical feature 在这种简单的深度学习模型上还是能够起到一定的效果的,这在之后的工作中也得到了证实
原文链接:https://www.aclweb.org/anthology/P15-1061/
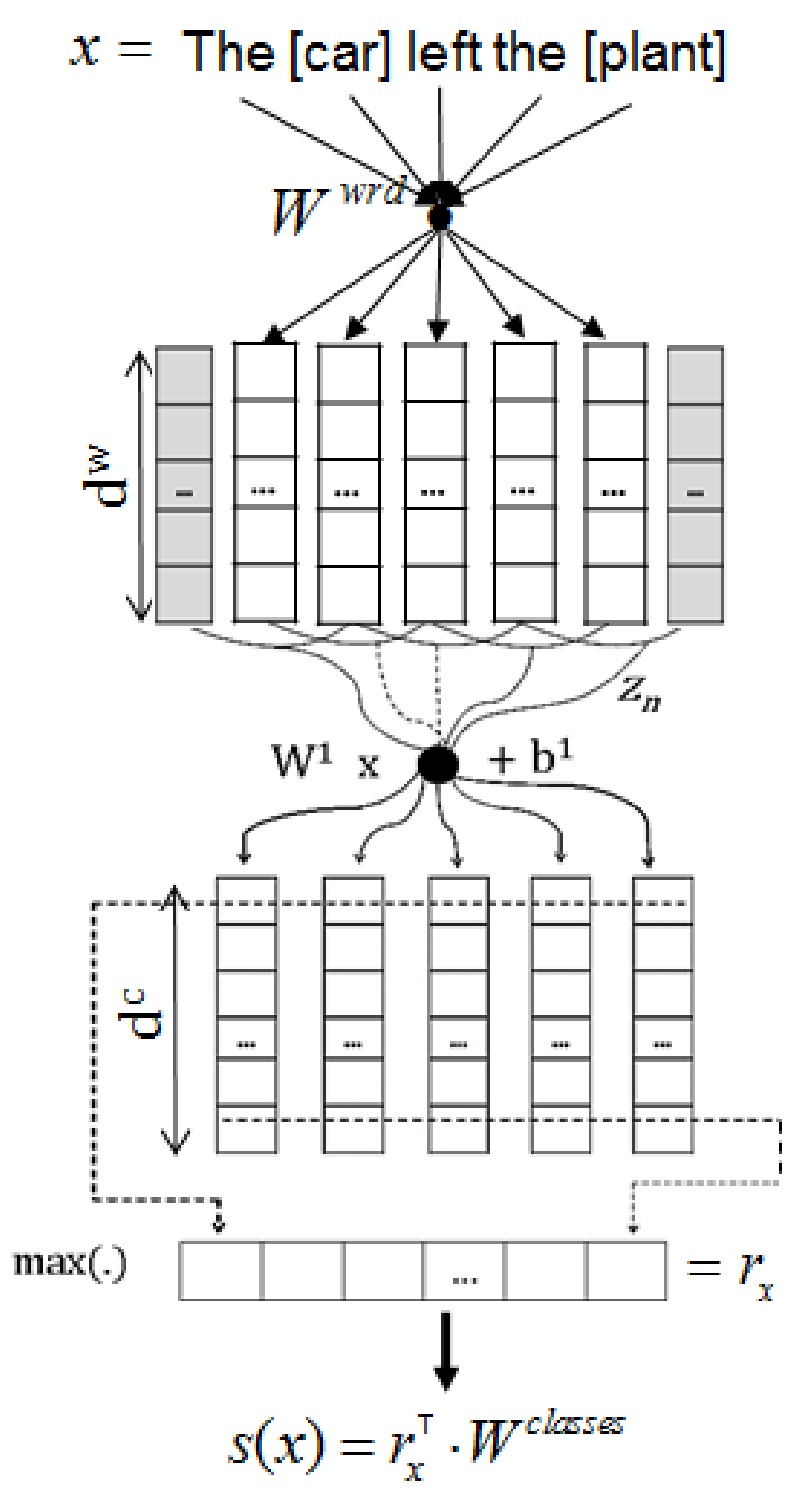
这篇论文同样是在 Model 1 基础上的改进,模型的基本架构与之前基本一致,最大的改变损失函数。模型结构如上图所示,主要有以下几个部分:
对于得到的编码表征,输入一个全连接层,得到每个类别的非归一化分数,但不再对输出做 softmax 操作,而是直接对正类别和负类别进行采样,从而计算损失函数,损失函数(pairwise ranking loss function)如下所示:
\[L = log(1 + exp(\gamma(m^+-s_{\theta}(x)_{y^+}))) + log(1 + exp(\gamma(m^-+s_{\theta}(x)_{c^-})))\]
模型在训练过程中还额外添加了 L2 正则化项
该模型的主要创新点在于其 Ranking loss 上,相比于 Softmax 函数,其能够使得模型不仅仅考虑到正类别分数要尽量高,还要关注易分类错误的类别分数尽量低。其缺点仍然是模型结构上的缺陷。
原文链接:https://www.aclweb.org/anthology/Y15-1009/
在这篇论文之前有过利用简单的 RNN 和 BiRNN 作为模型编码模块的处理关系抽取任务的,但是效果较 CNN 来说差的就不是一点两点了,这里就不提了。该论文用经典的 BiLSTM 作为模型主要模块,此外,重新考虑了 lexical feature,实验证明 lexical feature 对模型性能确实有十分明显的提升效果。
模型的主要架构是 BiLSTM,这个结构大家再熟悉不过了,论文也没有贴模型整体图,这里我也偷下懒...接下来分段阐述一下模型的主要工作。
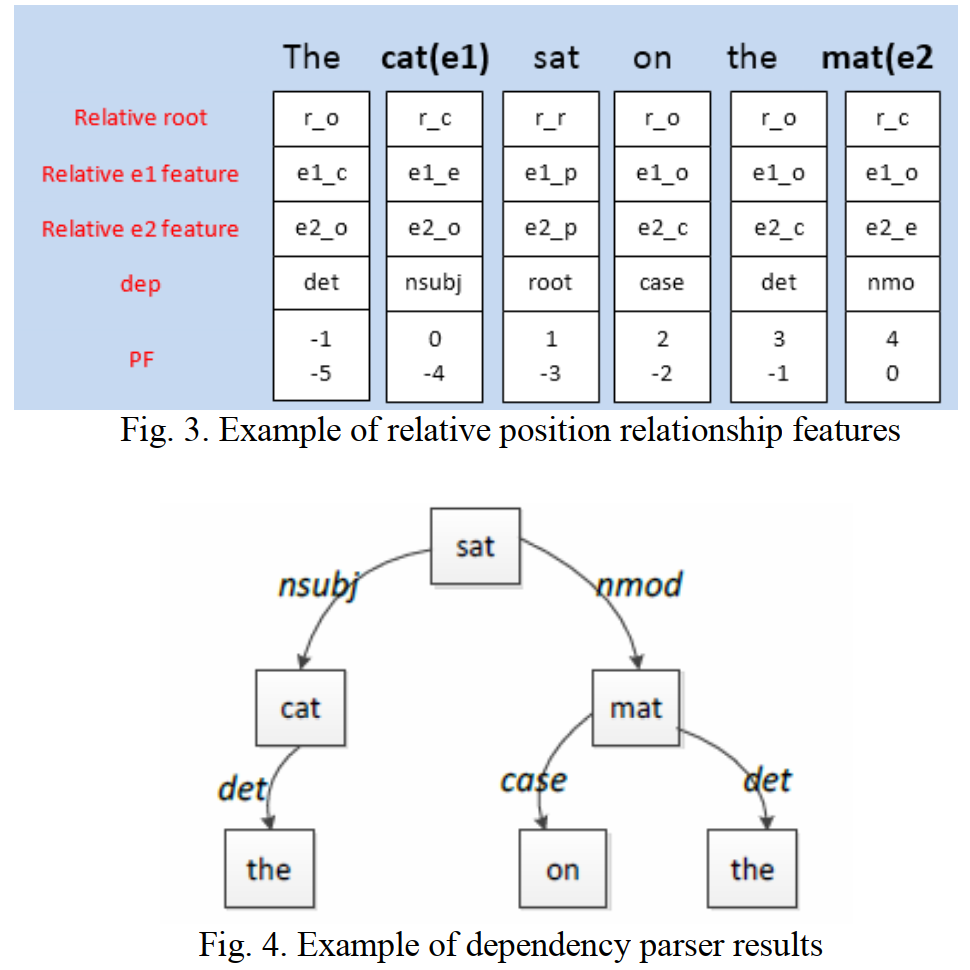
特征嵌入:第个词的词向量 \(r_i^w\) 利用预训练的词向量查表得到,第j个特征向量 \(r_i^{kj}\) 直接随机初始化得到,最终的词表征为词向量与特征向量拼接而成:
\[x_i = [r_i^w, r_i^{k1}, ..., r_i^{km}]\]
句子级别表征:直接将词表征输入 BiLSTM 进行编码,用 \(F\) 和 \(B\) 表示两个方向,\(h_i\)和\(c_i\)表示隐藏信息与全局信息,则第 \(i\) 时刻的输出为:
\[F_i = [F_{h_i}, F_{c_i}, B_{h_i}, B_{c_i}]\]
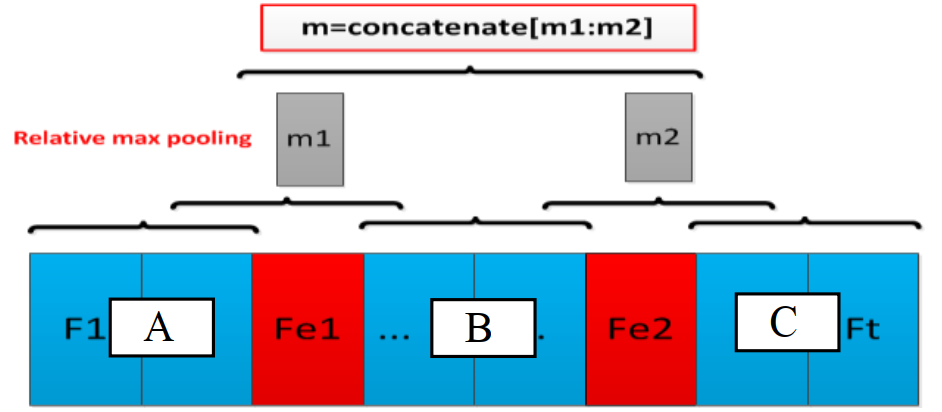
最后利用前连接层 + softmax 进行分类
论文最后测试了不加人工特征,只用 word embedding,结果下降了\(1.5\)个点,说明人工特征还是有一定效果的。此外,论文还测试了移除某个特征对模型的影响,发现位置特征和 NER 特征的移除对模型的影响非常小,这也是十分好理解的,这里就不多说了。
原文链接:
该模型利用了典型的注意力机制对 BiLSTM 的输出进行了注意力加权求和,在仅利用了词向量的情况下效果接近加入人工特征的模型,可见注意力机制的作用也是十分强大的。
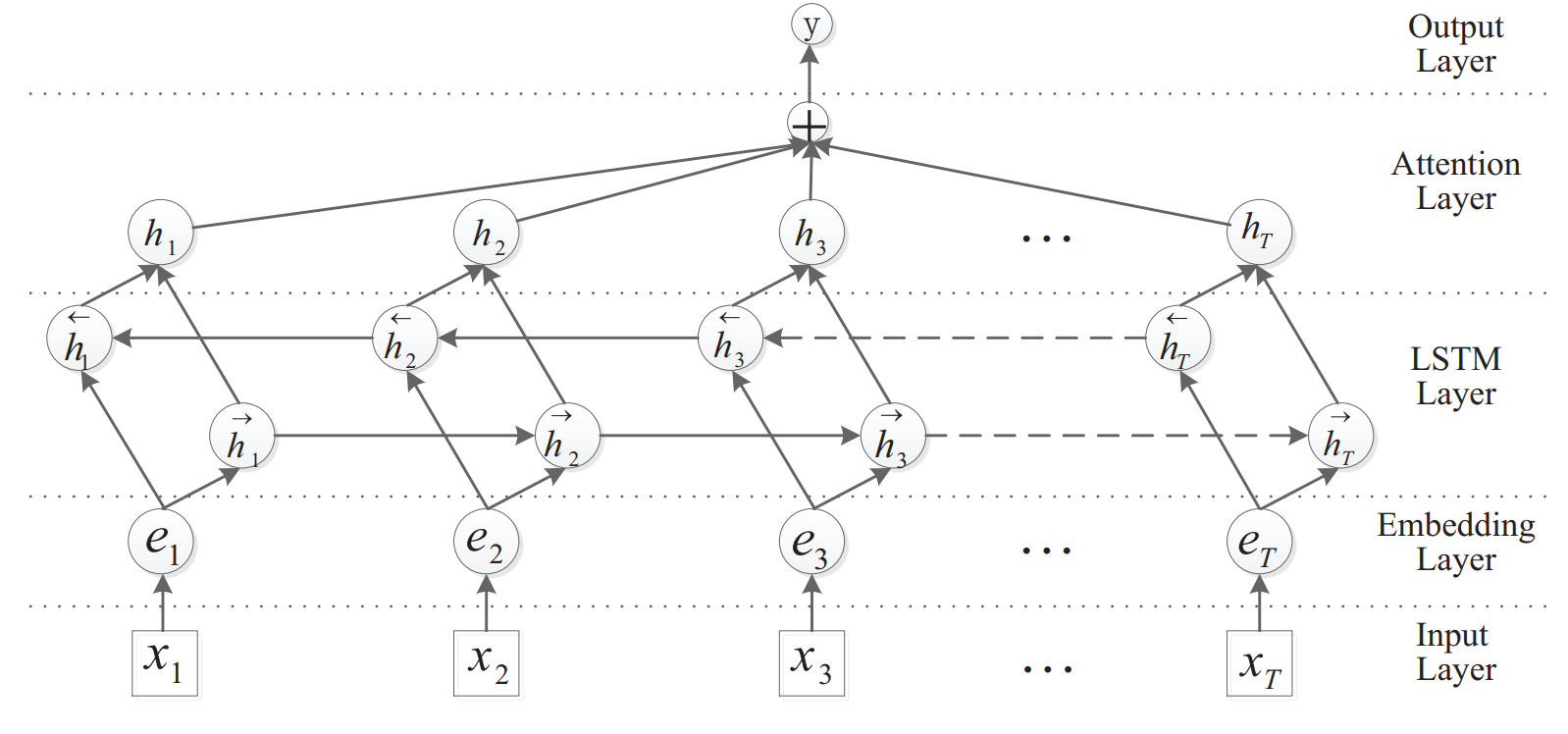
模型的主要架构如上图所示。其实模型的主要架构还是比较常规的,下面简单介绍一下:
从论文的结果来看,不进行特征工程,仅仅将整个句子作为模型输入,并加入注意力机制,模型效果得到了非常大的提高,一方面说明必要的特征工程还是有效的,另一方面表明注意力机制也起到了十分明显的作用
原文链接:https://www.aclweb.org/anthology/P16-1123/
这篇文章公布其在 SemEval-2010 Task 8 上的分数达到了 88.0,但是没有开源,且复现结果也不太好,这个模型的效果存在争议,或许是论文中个别细节描述有误,但是其思路还是非常不错的,先给概括一下整个论文的工作:
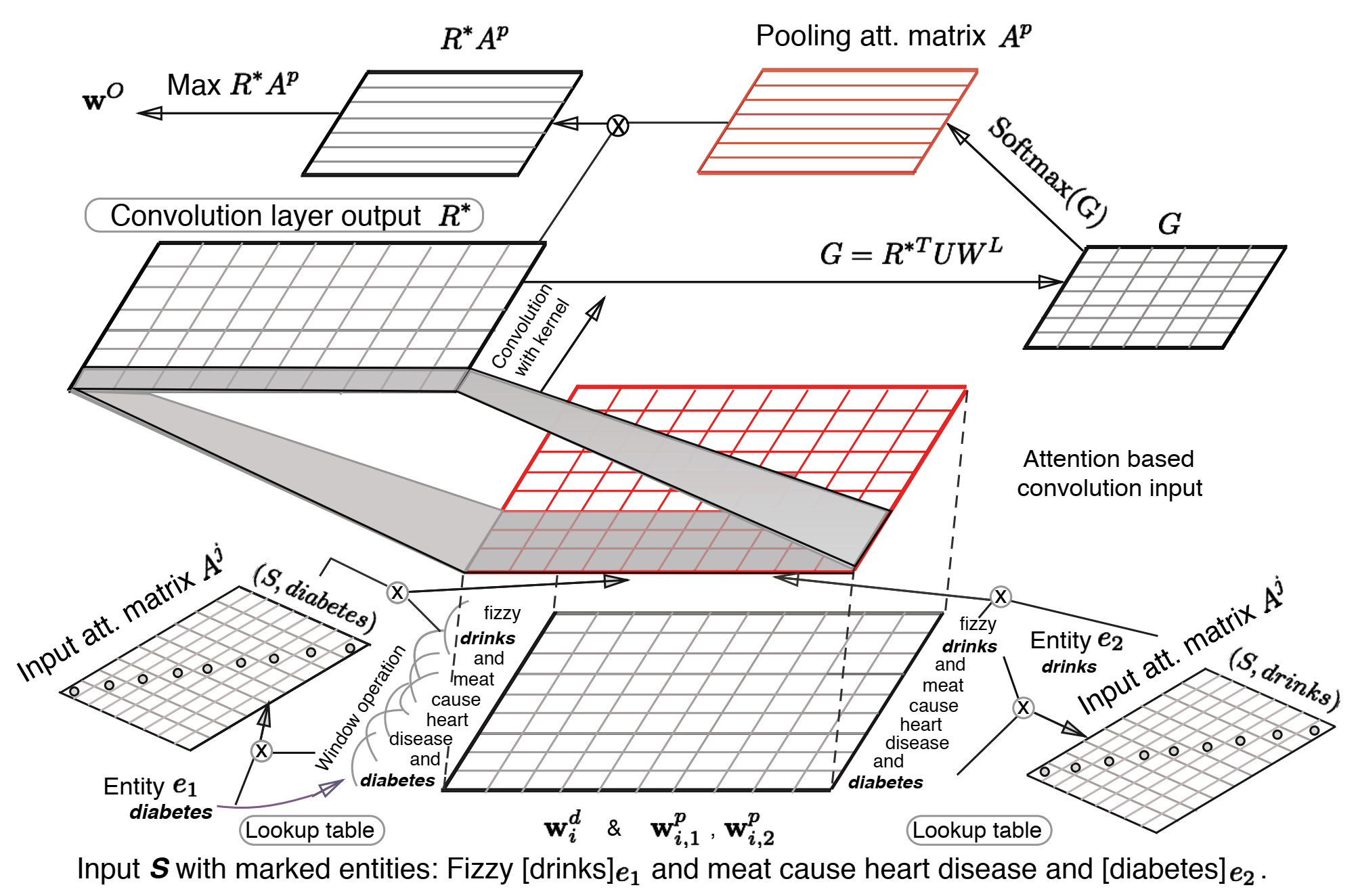
模型的主要结构如上图所示,下面分别阐述下模型的各个模块:
Input Attention Mechanism: 直接使用向量内积的方式来计算实体与其他词之间的相关性,并且将其构造成一个对角阵(其实可以直接用向量来表示的),再将其进行softmax归一化得到注意力分数:
\[A^j_{i, i} = e_i \cdot w_i \\alpha^j_i = \frac{exp(A^j_{i, i})}{\sum_{i'=1}^nexp(A^j_{i', i'})} \]
Convolution Layer: 由于事先在数据上做了 n-gram 操作,所以卷积核窗口设置为 1,其余的常规的卷积层没有区别,激活函数为 tanh,即
\[R^* = tanh(W_fR + B_f)\]
假设我们得到的 \(w^O\) 为我们得到的实体间的 inferred relation embedding,此外,我们还在 Attention-Based Pooling 中训练了 relation embedding,则计算两个向量间的距离:
\[\delta_{\theta}(S, y) = ||\frac{w^O}{|w^O|} - W_y^L||\]
我们希望 inferred relation embedding 与 正确标签的 embedding 距离尽量小,且与其他样本的 embedding 距离尽量大,作者借鉴了 pairwise ranking loss function (见 Model 3) 中的做法,损失函数函数定义如下:
\[L = [\delta_{\theta}(S, y) + (1-\delta_{\theta}(S, \hat{y}^-))] + \beta||\theta||^2\]
其中,\(\hat{y}^-\) 为所有标签中与 \(w^O\) 距离最大的负标签(个人在这里存在疑惑,认为这个应该是与 \(w^O\)距离最小的负标签才更为合适,因为我们期望将最易分错的类别与 \(w^O\) 应该尽量远)
可以看到这篇论文的两次 Attention 以及 损失函数的设计都是十分巧妙的,且论文中提到效果非常好,许多技巧还是可以借鉴的。
原文链接:https://www.aclweb.org/anthology/P16-1072/
论文的主要思想是对两个实体间的词法句法的最短依赖路径 SDP (shortest dependency path)进行建模,这也是常见的一种关系抽取任务的建模方法,并与之前的建模方式存在一些区别,下面相对详细地阐述一下。
由于受到卷积神经网络和循环神经网络特性的限制,之前的工作将句法依赖关系看作是词或者某些句法特征,如词性标签 (POS)。该论文的第一个贡献就是提出了一种 RCNN 的网络结构:
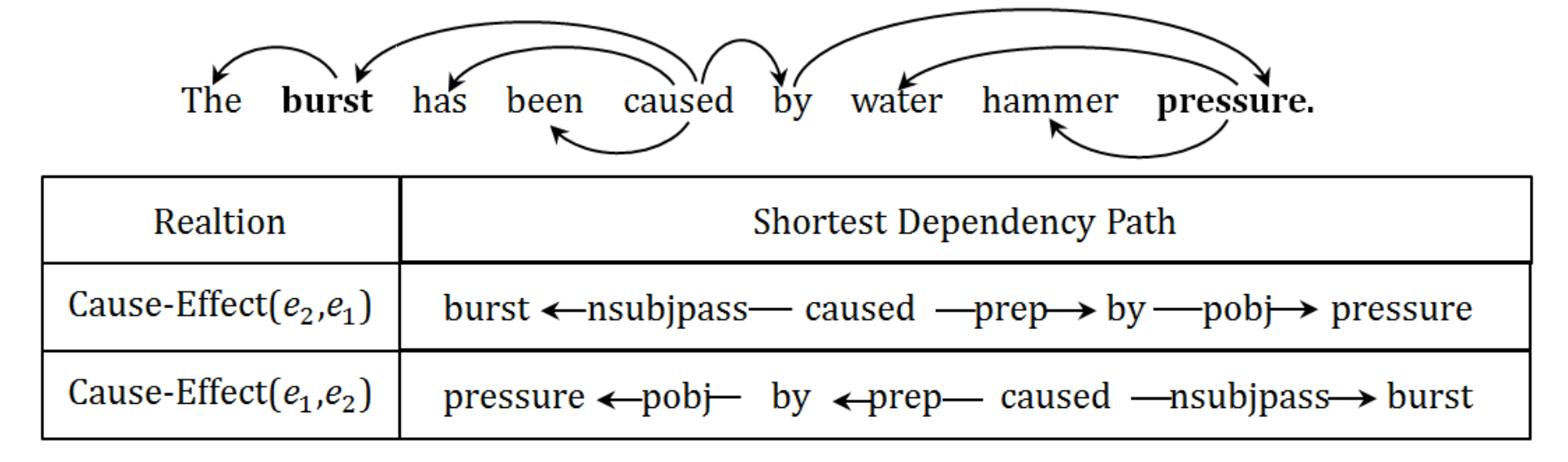
此外,作者还指出,两个实体之间的依赖关系是有向的,如上图展示的因果关系示例图,若存在 \(K\) 个关系,则需要将其看作 \((2K + 1)\) 种分类问题,其中 \(1\) 为 \(Other\) 类。因此,作者提出其第二个贡献就在于使用双向的循环卷积神经网络 (BRCNN) 来同时学习双向的表征,可以将双向依赖问题建模为对称的依赖问题,从而将其简化为 \((K + 1)\) 的分类问题
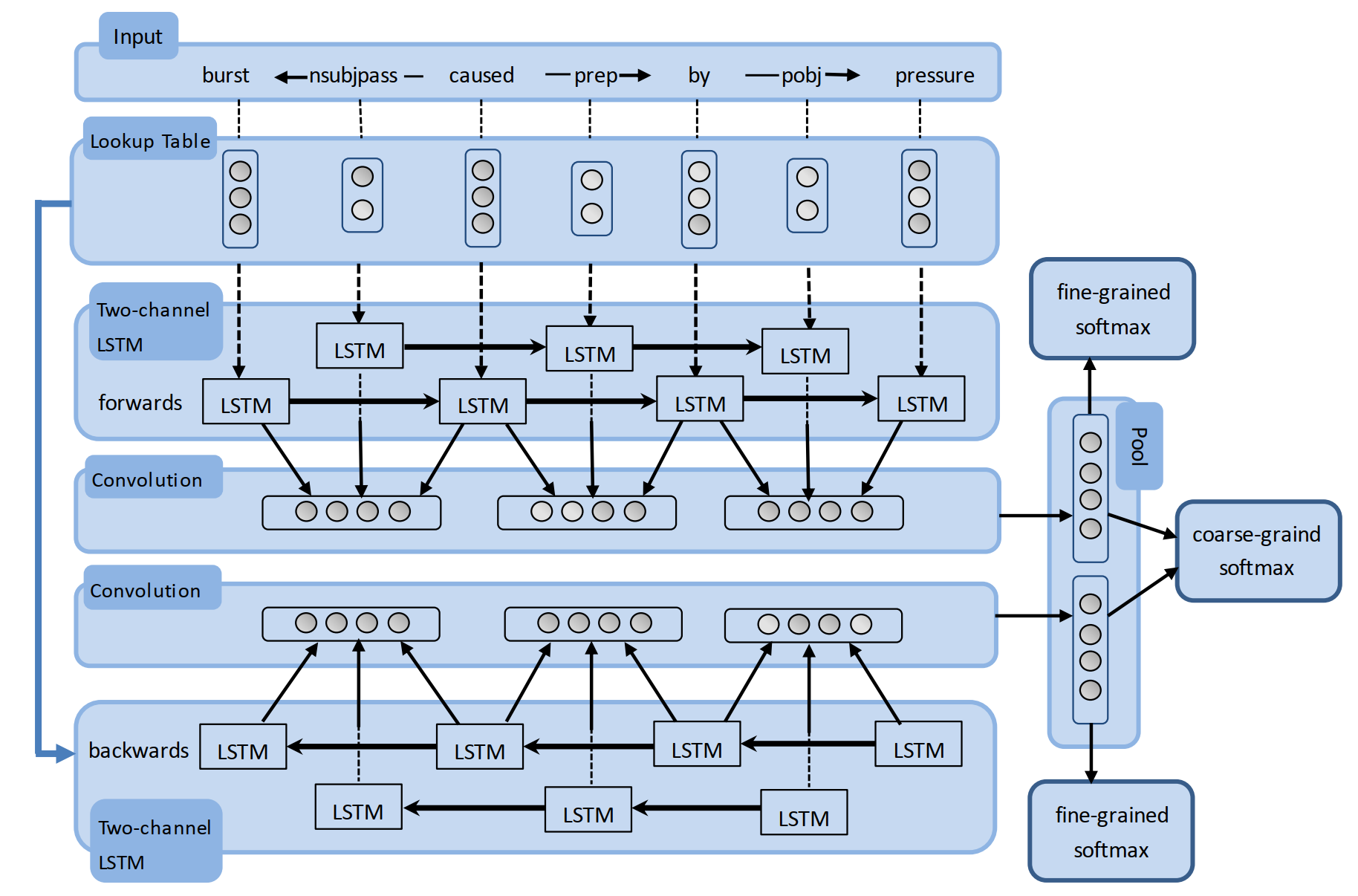
模型细节如上图所示,下面简单讲解一下整个模型结构:
对于存在关系的词与依赖关系 \(w_a -r_{ab}-> w_b\),分别用 \(h_a, h_{ab}', h_b\) 来表示 LSTM 的对应隐藏表征,则可以利用 CNN 将词及依赖关系的局部特征 \(L_{ab}\) 进行抽取,即
\[L_{ab} = tanh(W_{con} \cdot [h_a , h_{ab}', h_b] + b_{con})\]
目标函数:由于存在三个分类器,损失函数为三个分类器的交叉熵的累加和,同时加上了 l2 正则化
\[J = \sum_{i=1}^{2K+1}\overrightarrow{t}_ilog\ \overrightarrow{y}_i + \sum_{i=1}^{2K+1}\overleftarrow{t}_ilog\ \overleftarrow{y}_i + \sum_{i=1}^{K+1}{t}_ilog\ {y}_i + \lambda||\theta||^2\]
而对于解码过程,两个实体之间只存在一个单向的关系,因此仅需要两个 fine-grained softmax classifiers 的输出结果即可
\[y_{test} = \alpha\cdot \overrightarrow{y} + (1-\alpha)\cdot z(\overleftarrow{y})\]
其中,\(\alpha\) 为一个超参数,论文中将其设置为 0.65。另外由于两个预测结果的方向是相反的,因此需要用一个函数 \(z(·)\) 来将 \(\overleftarrow{y}\) 转化为与 \(\overrightarrow{y}\) 对应的格式
将词法句法的 SDP 作为输入特征来实现关系抽取也是常见的一种建模方法,且效果也非常不错。这篇论文通过对文本以及依赖关系分别建模,利用 LSTM 和 CNN 进行不同层次的特征编码,并分两个方向进行信息融合,确实是一大亮点。如果词向量只用 Word Embeddings,分数可以达到 85.4,如果加上 NER、POS 以及 WordNet 等特征可以达到 86.3。
将关系抽取看作单独任务的模型总结就做到这里了,或许之后看见更优秀的论文还会进行一些更新,这里将每个模型在 SemEval-2010 Task-8 上的分数都记载一下:
|模型| 论文名称 | 输入特征 |F1|
| :----- | :----- | :----- | :----- |
| Model 1 | Relation Classification via Convolutional Deep Neural Network | Word Embeddings, Position Embeddings, WordNet | 82.7 |
| Model 2 | Relation Extraction: Perspective from Convolutional Neural Networks | Word Embeddings, Position Embeddings | 82.8 |
| Model 3 | Classifying Relations by Ranking with Convolutional Neural Networks | Word Embeddings, Position Embeddings | 84.1 |
| Model 4 | Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification | Word Embeddings, Position Embeddings, POS, NER, WordNet, Dependency Feature | 84.3 |
| Model 5 | Bidirectional Long Short-Term Memory Networks for Relation Classification | Word Embeddings, Position Embeddings | 84.0 |
| Model 6 | Relation Classification via Multi-Level Attention CNNs | Word Embeddings, Position Embeddings | 88.0 |
| Model 7 | Bidirectional Recurrent Convolutional Neural Network for Relation Classification |Word Embeddings, WordNet, NER, WordNet | 86.3 |
总的来说,人工特征、句法特征、注意力机制、特殊的损失函数都是关系抽取模型性能提升的关键点,其余的就需要在模型架构上进行合理的设计了,下一篇准备介绍实体与关系联合抽取模型,争取早点写出来...
https://zhuanlan.zhihu.com/p/45422620
http://www.shuang0420.com/2018/09/15/知识抽取-实体及关系抽取/
https://zhuanlan.zhihu.com/p/91762831
http://shomy.top/2018/02/28/relation-extraction/
原文:https://www.cnblogs.com/sandwichnlp/p/12020066.html