

进入spark-shell创建文件流。另外打开一个终端窗口,启动进入spark-shell

上面在spark-shell中执行的程序,一旦你输入ssc.start()以后,程序就开始自动进入循环监听状态,屏幕上会显示一堆的信息,如下:

在“/usr/local/spark/mycode/streaming/logfile”目录下新建一个log.txt文件,就可以在监听窗口中显示词频统计结果
在当前streaming下创建三级子目录,因为只有把代码放到src/main/scala目录下,sbt打包编译工具才能够正确运行。

用vim编辑器新建一个TestStreaming.scala代码文件,请在里面输入以下代码:
import org.apache.spark._
import org.apache.spark.streaming._
object WordCountStreaming {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("WordCountStreaming").setMaster("local[2]")//设置为本地运行模式,2个线程,一个监听,另一个处理数据
val ssc = new StreamingContext(sparkConf, Seconds(2))// 时间间隔为2秒
val lines = ssc.textFileStream("file:///usr/local/spark/mycode/streaming/logfile") //这里采用本地文件,当然你也可以采用HDFS文件
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}


在simple.sbt文件中输入以下代码: 
执行sbt打包编译的命令如下:

打包成功以后,就可以输入以下命令启动这个程序:

Spark Streaming可以通过Socket端口监听并接收数据,然后进行相应处理
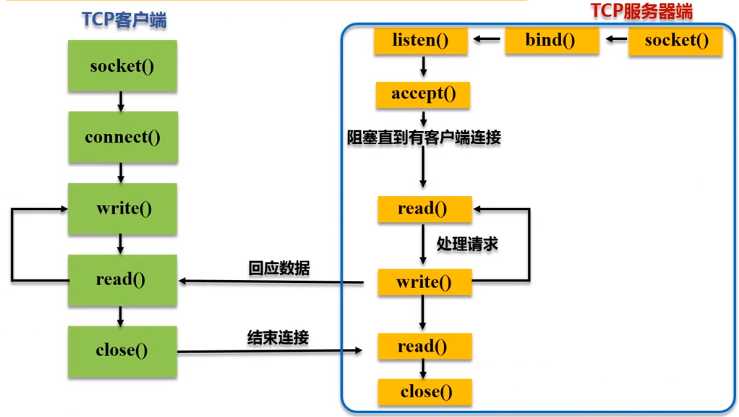

请在NetworkWordCount.scala文件中输入如下内容:(客户端向服务端发起连接,需要告诉它向哪个主机哪个端口发起连接)
package org.apache.spark.examples.streaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels() # 设置日志显示级别
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]") #生成sparkConf对象
val ssc = new StreamingContext(sparkConf, Seconds(1)) #生成一个StreamingContext对象
# 1.定义输入数据流,args(0)是TCP服务端的主机名,args(1)是TCP服务端的端口号(字符串转整数)
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)#保存数据方式
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
在相同目录下再新建另外一个代码文件StreamingExamples.scala,文件内容如下:
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging { # 单例对象,不需要实例化,直接用它的静态方法
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark‘s default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}




新打开一个窗口作为nc窗口,启动nc程序:

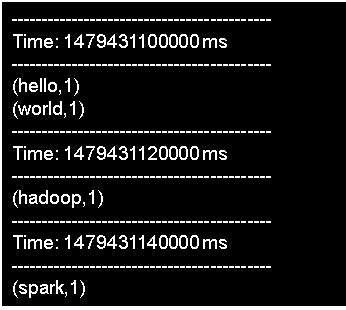
可以在nc窗口中随意输入一些单词,监听窗口就会自动获得单词数据流信息,在监听窗口每隔1秒就会打印出词频统计信息,大概会在屏幕上出现类似如下的结果:
下面我们再前进一步,把数据源头的产生方式修改一下,不要使用nc程序,而是采用自己编写的程序产生Socket数据源。



原文:https://www.cnblogs.com/nxf-rabbit75/p/12025106.html