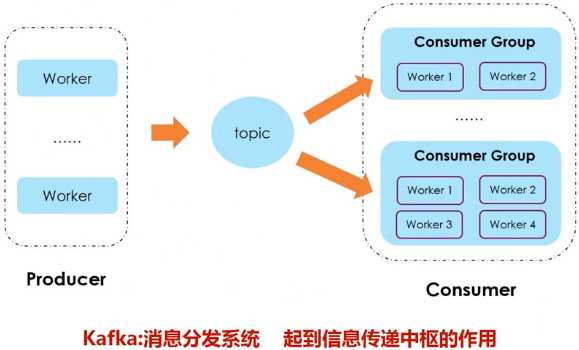
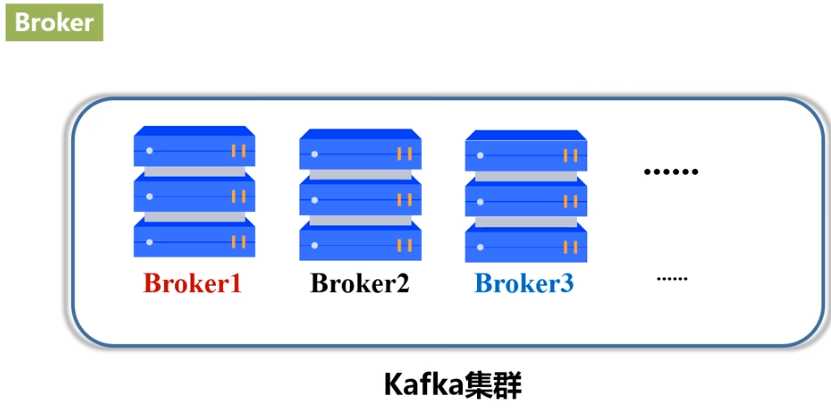
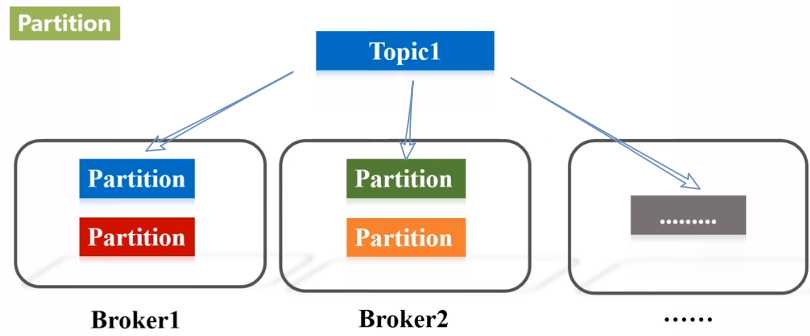
Kafka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafka系统可以发布大量的消息,同时也能实时订阅消费消息。Kafka可以同时满足在线实时处理和批量离线处理。
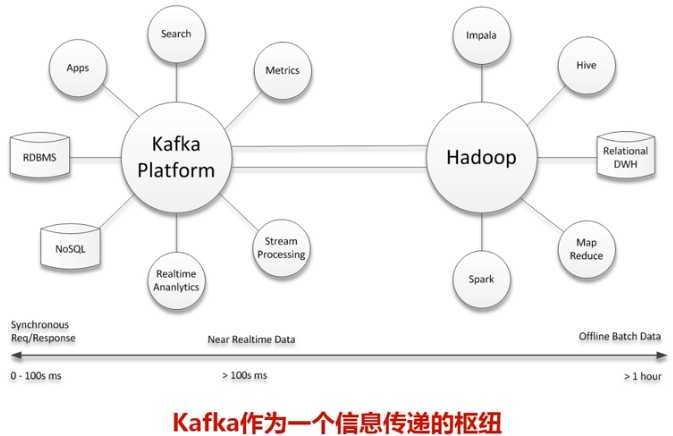
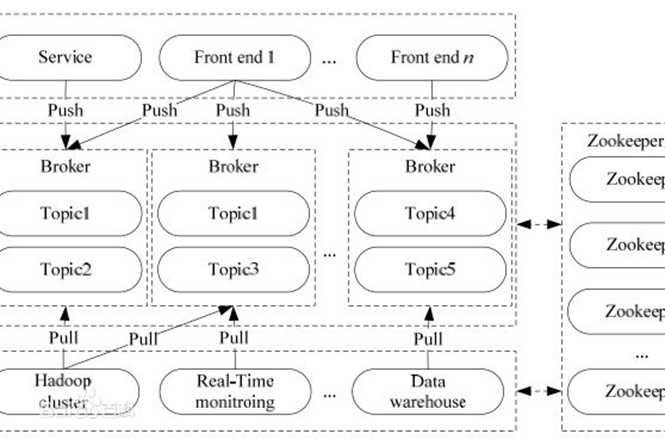
在公司的大数据生态系统中,可以把Kafka作为数据交换枢纽,不同类型的分布式系统(关系数据库、NoSQL数据库、流处理系统、批处理系统等),可以统一接入到Kafka,实现和Hadoop各个组件之间的不同类型数据的实时高效交换。

这里假设已经成功安装Kafka到“/usr/local/kafka”目录下
下载的安装文件为Kafka_2.11-0.10.2.0.tgz,前面的2.11就是该Kafka所支持的Scala版本号,后面的0.10.2.0是Kafka自身的版本号。
打开一个终端,输入下面命令启动Zookeeper服务:

千万不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了。
打开第二个终端,然后输入下面命令启动Kafka服务:

千万不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了。
再打开第三个终端,然后输入下面命令创建一个自定义名称为“wordsendertest”的Topic:

原文:https://www.cnblogs.com/nxf-rabbit75/p/12028371.html