对源DStream的每个元素,采用func函数进行转换,得到一个新的Dstream。
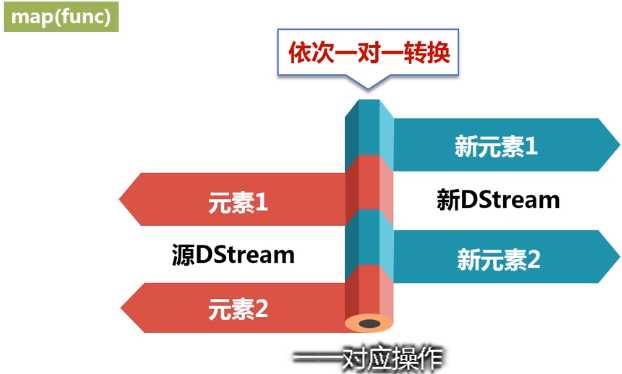
与map相似,但是每个输入项可用被映射为0个或者多个输出项。
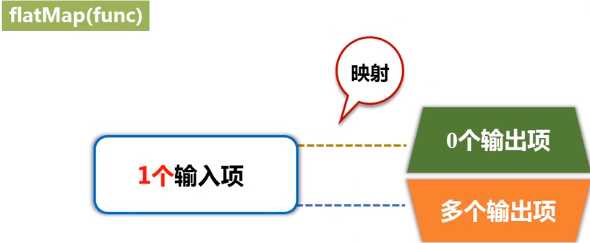
返回一个新的DStream,仅包含源DStream中满足函数func的项。
通过创建更多或者更少的分区改变DStream的并行程度。
利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream。
统计源DStream中每个RDD的元素数量。

返回一个新的DStream,包含源DStream和其他DStream的元素。

应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数。
当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来。
当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新Dstream。
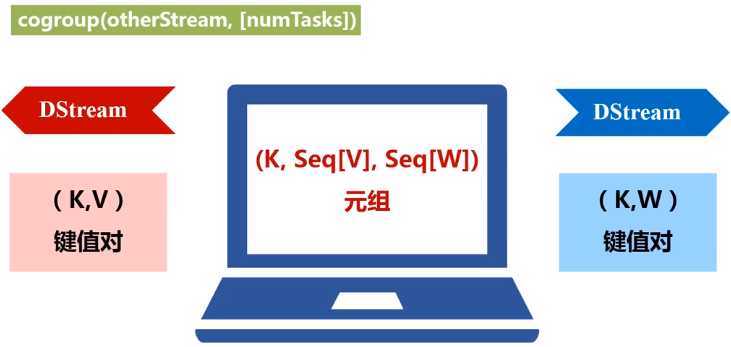
当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组。
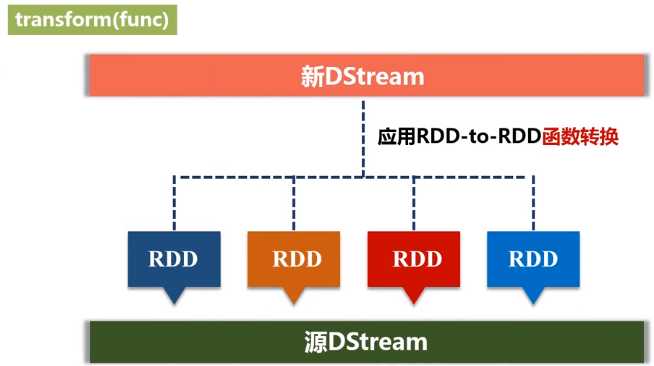
通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作。
无状态转换操作实例:之前“套接字流”部分介绍的词频统计,就是采用无状态转换,每次统计,都是只统计当前批次到达的单词的词频,和之前批次无关,不会进行累计。
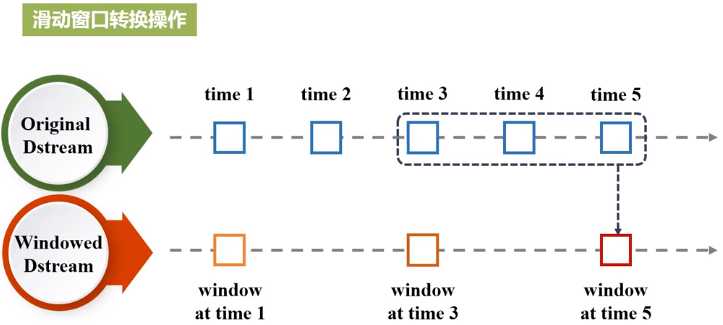
一些窗口转换操作的含义:
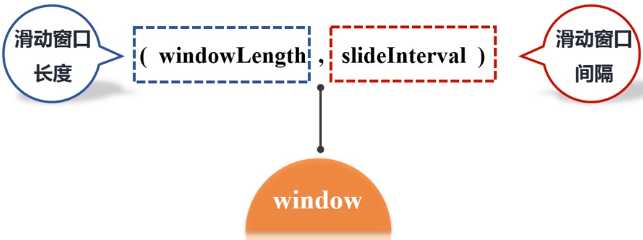
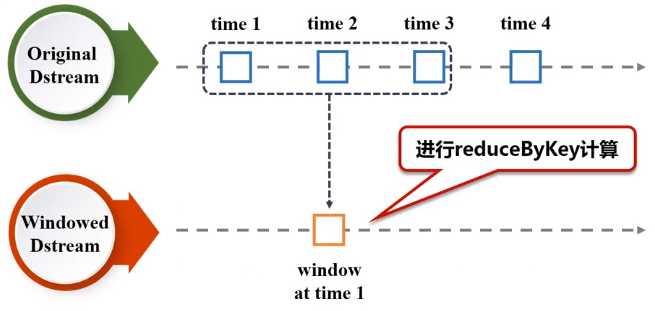
(1)window(windowLength, slideInterval) 基于源DStream产生的窗口化的批数据,计算得到一个新的Dstream;
(2)countByWindow(windowLength, slideInterval) 返回流中元素的一个滑动窗口数;

(3)reduceByWindow(func, windowLength, slideInterval) 返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算;
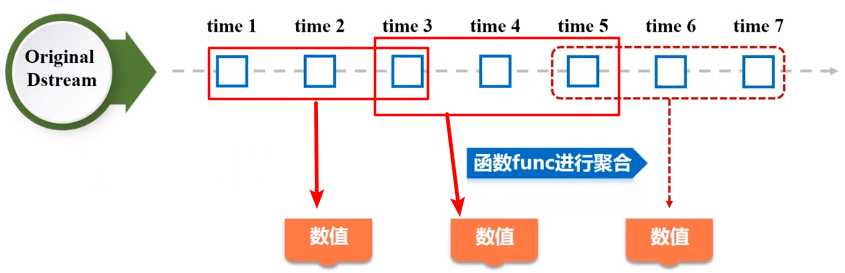

(4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数。
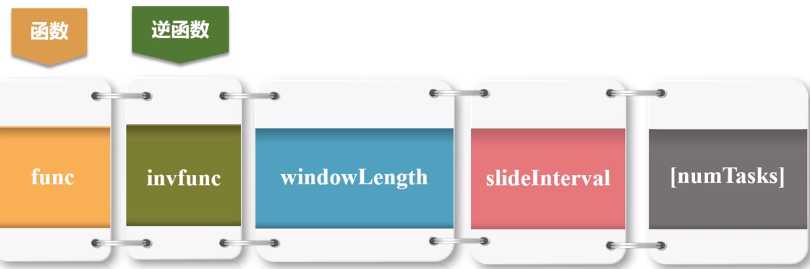
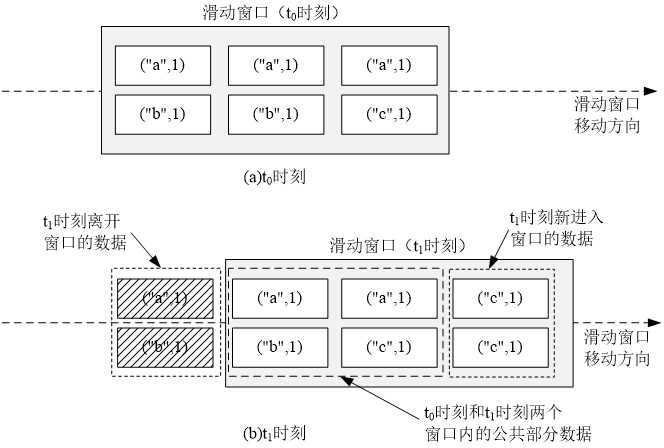
(5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
(6)countByValueAndWindow(windowLength, slideInterval, [numTasks]) 当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
窗口转换操作实例:
在上一节的“Apache Kafka作为DStream数据源”内容中,已经使用了窗口转换操作,在KafkaWordCount.scala代码中,可以找到下面这一行:
val wordCounts = pair.reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2)
原文:https://www.cnblogs.com/nxf-rabbit75/p/12032339.html