流式计算中处理延迟是一个非常重要的监控metric
flink中通过开启配置 metrics.latency.interval 来开启latency后就可以在metric中看到askManagerJobMetricGroup/operator_id/operator_subtask_index/latency指标了
如果每一条数据都打上时间监控 输出时间- 输入时间,会大量的消耗性能
来看一下flink自带的延迟监控是怎么做的
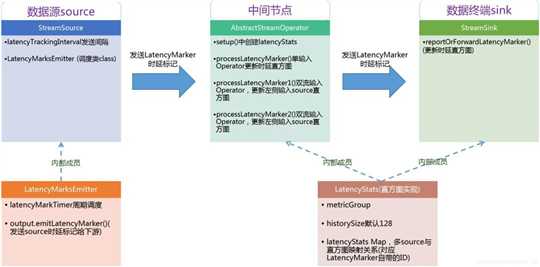
其实也可以想到原理很简单,就是在source周期性的插入一条特殊的数据LatencyMarker
LatencyMarker初始化的时候会带上它产生时的时间
每次当task接收到的数据是LatencyMarker的时候他就用 当前时间 - LatencyMarker时间 = lateTime 并发送到指标收集系统
接着继续把这个LatencyMarker往下游emit
来看一下源码是如何实现的
因为是从source加入LatencyMarker先看StreamSource.java
在StreamSource的run 方法中
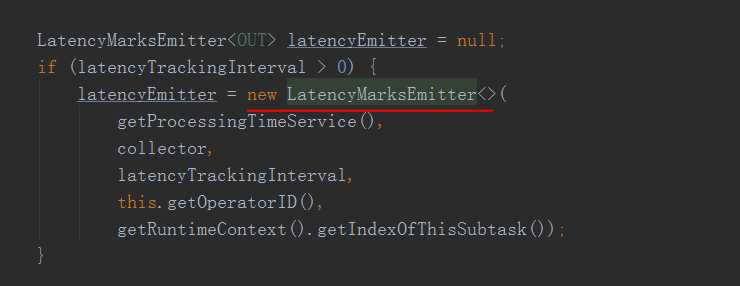
初始化了一个LatencyMarksEmitter
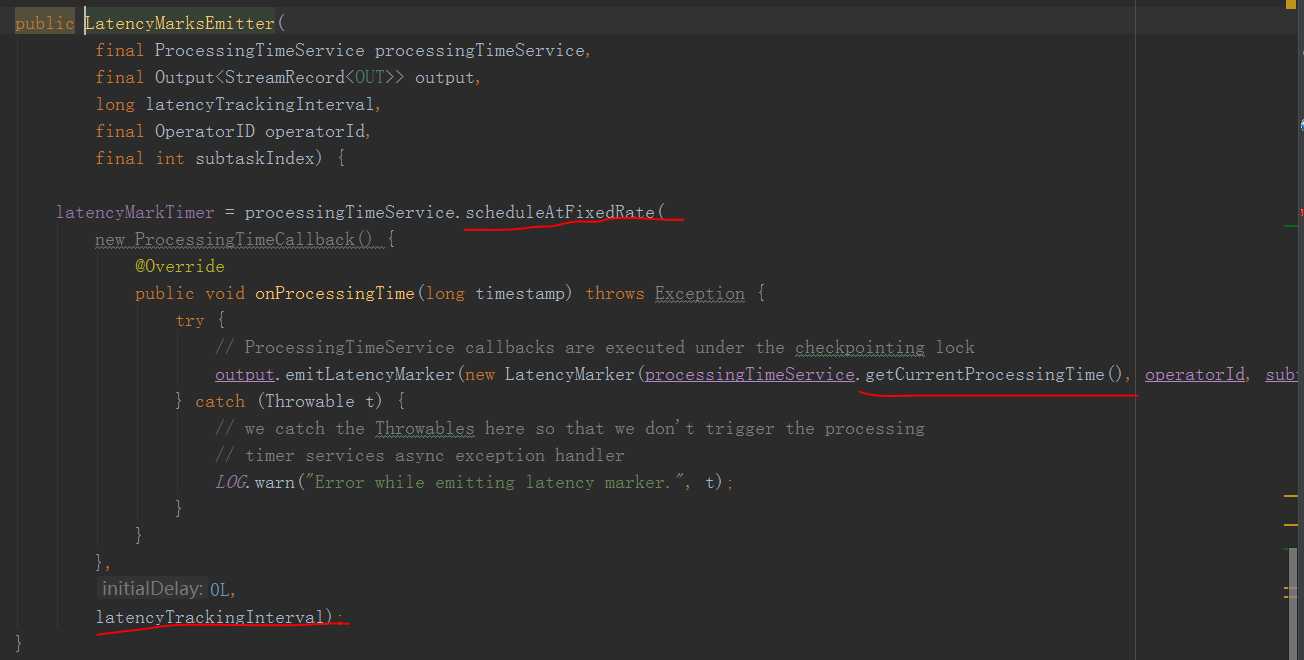
其实就是在processTimeServera中周期性(我们设置的metrics.latency.interval 时长)去向下游emit 当前时间的LatencyMarker
接着来到task接收数据的地方
StreamInputProcessor的processInput方法中

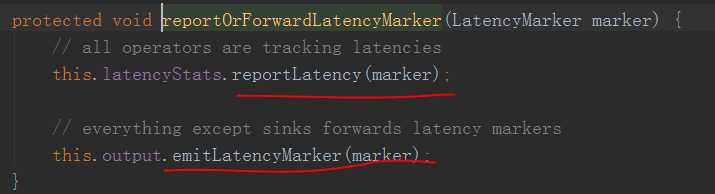

可以看到就是用当前时间 - LatencyMarker,然后就往report发送了,然后emit
而sink算子的唯一区别就是
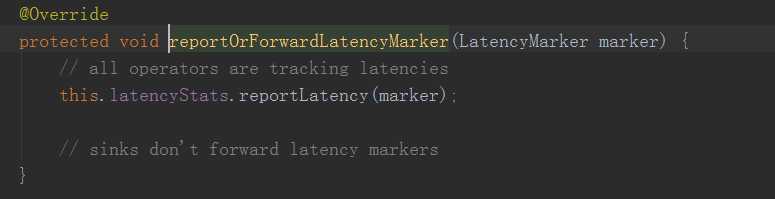
区别就是sink没有emit LatencyMarker 因为是最后一个算子了嘛
这里就讲完了
注意的点是:
其实可以看到flink中的LatencyMarker是没有走用户代码逻辑的,也就是说统计出来的延迟时间并不是端到端的,而是除了用户逻辑处理外的延迟,
因为LatencyMarker和数据的处理是同步处理的,虽然监控延迟中没有过用户逻辑代码(正常数据接收以后用户代码处理然后emit,LatencyMarker接收后直接emit)
但是就像马路一样,整个马路拥塞了延迟高了,那还是会使这个指标值越来越大
可能这样的设计是考虑到LatencyMarker如果也走用户处理逻辑的话会消耗过多的性能吧,特别是采集频繁的时候
原文:https://www.cnblogs.com/ljygz/p/12036297.html