自动装箱时编译器调用valueOf将原始类型值转换成对象,同时自动拆箱时,编译器通过调用类似intValue(),doubleValue()这类的方法将对象转换成原始类型值。
只有double和float的自动装箱代码没有使用缓存,每次都是new 新的对象,其它的6种基本类型都使用了缓存策略。 ????
使用缓存策略是因为,缓存的这些对象都是经常使用到的(如字符、-128至127之间的数字),防止每次自动装箱都创建一次对象的实例。 ????
而double、float是浮点型的,没有特别的热的(经常使用到的)数据的,缓存效果没有其它几种类型使用效率高。
程序在运行时能够动态的获取到一个类的类型信息
创建Class类对象的方式有三种:
对象.getClass()方式类名.Class方式Class.forName( 类的包名 ) 方式反射性能慢的原因
如果在拷贝这个对象的时候,只对基本数据类型进行了拷贝,而对引用数据类型只是进行了引用的传递,而没有真实的创建一个新的对象,则认为是浅拷贝。反之,在对引用数据类型进行拷贝的时候,创建了一个新的对象,并且复制其内的成员变量,则认为是深拷贝。
实现Cloneable 接口,复写clone()方法,实现的是浅拷贝
IOC:
IOC(控制翻转)是一种编程范式,可以在一定程度上解决复杂系统对象耦合度太高的问题,并不是Spring的专利。IOC最常见的方式是DI(依赖注入),可以通过一个容器,将Bean维护起来,方便在其他地方直接使用,而不是重新new。
为什么DI可以起到解耦的作用?
一个软件系统包含了大量的对象,每个对象之间都有依赖关系,在普通的软件编写过程中,对象的定义分布在各个文件之中,对象之间的依赖,只能通过类的构造器传参,方法传参的形式来完成。当工程变大之后,复杂的逻辑会让对象之间的依赖梳理变得异常困难。
在Spring IOC中,一般情况,我们可以在XML文件之中,统一的编写bean的定义,bean与bean之间的依赖关系,从而增加逻辑的清晰度。而且,bean的创建是由Spring来完成的,不需要编程人员关心,编程人员只需要将精力放到业务的逻辑上面,减轻了思维的负担。
Spring 启动时读取应用程序提供的Bean配置信息,并在Spring容器中生成一份相应的Bean配置注册表,然后根据这张注册表实例化Bean,装配好Bean之间的依赖关系,为上层应用提供准备就绪的运行环境。
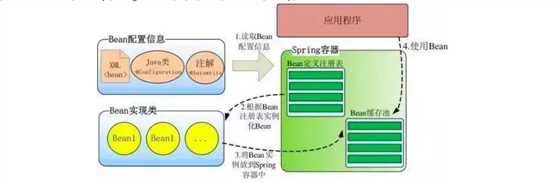
Bean缓存池:HashMap实现
依赖注入的思想是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在Bean缓存池(HashMap)中的类属性注入到类中。
AOP:
aop实现原理其实是java动态代理,但是jdk的动态代理必须实现接口,所以spring的aop是用cglib这个库实现的,cglib使用了asm这个直接操纵字节码的框架,所以可以做到不实现接口的情况下完成动态代理。
controller默认是单例的,不要使用非静态的成员变量,否则会发生数据逻辑混乱。
正因为单例所以不是线程安全的。
补充说明
spring bean作用域有以下5个:
singleton:单例模式,当spring创建applicationContext容器的时候,spring会欲初始化所有的该作用域实例,加上lazy-init就可以避免预处理;
prototype:原型模式,每次通过getBean获取该bean就会新产生一个实例,创建后spring将不再对其管理;
(下面是在web项目下才用到的)
request:搞web的大家都应该明白request的域了吧,就是每次请求都新产生一个实例,和prototype不同就是创建后,接下来的管理,spring依然在监听;
常用的三个状态是:ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。
TCP协议规定,对于已经建立的连接,网络双方要进行四次握手才能成功断开连接,如果缺少了其中某个步骤,将会使连接处于假死状态,连接本身占用的资源不会被释放。网络服务器程序要同时管理大量连接,所以很有必要保证无用连接完全断开,否则大量僵死的连接会浪费许多服务器资源。在众多TCP状态中,最值得注意的状态有两个:CLOSE_WAIT和TIME_WAIT。
TIME_WAIT
TIME_WAIT 是主动关闭链接时形成的,等待2MSL时间,约4分钟。主要是防止最后一个ACK丢失。 由于TIME_WAIT 的时间会非常长,因此server端应尽量减少主动关闭连接
CLOSE_WAIT
CLOSE_WAIT是被动关闭连接是形成的。根据TCP状态机,服务器端收到客户端发送的FIN,则按照TCP实现发送ACK,因此进入CLOSE_WAIT状态。但如果服务器端不执行close(),就不能由CLOSE_WAIT迁移到LAST_ACK,则系统中会存在很多CLOSE_WAIT状态的连接。此时,可能是系统忙于处理读、写操作,而未将已收到FIN的连接,进行close。此时,recv/read已收到FIN的连接socket,会返回0。
为什么需要 TIME_WAIT 状态?
假设最终的ACK丢失,server将重发FIN,client必须维护TCP状态信息以便可以重发最终的ACK,否则会发送RST,结果server认为发生错误。TCP实现必须可靠地终止连接的两个方向(全双工关闭),client必须进入 TIME_WAIT 状态,因为client可能面 临重发最终ACK的情形。
为什么 TIME_WAIT 状态需要保持 2MSL 这么长的时间?
RFC 793 [Postel 1981c] 指出MSL为2分钟。然而,实现中的常用值是30秒,1分钟,或2分钟。
2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态,当TCP的一端发起主动关闭,在发出最后一个ACK包后,即第3次握手完成后发送了第四次握手的ACK包后就进入了TIME_WAIT状态,必须在此状态上停留两倍的MSL时间。
等待2MSL时间主要目的是怕最后一个ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包。
在TIME_WAIT状态时两端的端口不能使用,要等到2MSL时间结束才可继续使用。
当连接处于2MSL等待阶段时任何迟到的报文段都将被丢弃。不过在实际应用中可以通过设置SO_REUSEADDR选项达到不必等待2MSL时间结束再使用此端口。
TIME_WAIT 和*CLOSE_WAIT*状态socket过多
如果服务器出了异常,百分之八九十都是下面两种情况:
1.服务器保持了大量TIME_WAIT状态
2.服务器保持了大量CLOSE_WAIT状态,简单来说CLOSE_WAIT数目过大是由于被动关闭连接处理不当导致的。
因为linux分配给一个用户的文件句柄是有限的,而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,Tomcat崩溃。
这个也是线上非常常见的一个问题,就是多客户端同时并发写一个 key,可能本来应该先到的数据后到了,导致数据版本错了;或者是多客户端同时获取一个 key,修改值之后再写回去,只要顺序错了,数据就错了。
解决办法
InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
InnoDB 是聚集索引,MyISAM 是非聚集索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
提供一种简单实现缓存失效的思路: LRU(最近少用的淘汰)
即redis的缓存每命中一次,就给命中的缓存增加一定ttl(过期时间)(根据具体情况来设定, 比如10分钟).
一段时间后, 热数据的ttl都会较大, 不会自动失效, 而冷数据基本上过了设定的ttl就马上失效了.
redis 提供 6种数据淘汰策略:
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
算法的核心思想是结合机器的网卡、当地时间、一个随记数来生成UUID。
使用数据库的id自增策略,如 MySQL 的 auto_increment。并且可以使用两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。
一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台 Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长都是 5。各个 Redis 生成的 ID 为:
A:1, 6, 11, 16, 21
B:2, 7, 12, 17, 22
C:3, 8, 13, 18, 23
D:4, 9, 14, 19, 24
E:5, 10, 15, 20, 25
复制代码随便负载到哪个机确定好,未来很难做修改。步长和初始值一定需要事先确定。使用 Redis 集群也可以方式单点故障的问题。
另外,比较适合使用 Redis 来生成每天从0开始的流水号。比如订单号 = 日期 + 当日自增长号。可以每天在 Redis 中生成一个 Key ,使用 INCR 进行累加。
Twitter一个全局ID生成的服务 Snowflake:github.com/twitter/sno…

如上图的所示,Twitter 的 Snowflake 算法由下面几部分组成:
由于 long 类型在 java 中带符号的,最高位为符号位,正数为 0,负数为 1,且实际系统中所使用的ID一般都是正数,所以最高位为 0。
需要注意的是此处的 41 位时间戳并非存储当前时间的时间戳,而是存储时间戳的差值(当前时间戳 - 起始时间戳),这里的起始时间戳一般是ID生成器开始使用的时间戳,由程序来指定,所以41位毫秒时间戳最多可以使用 (1 << 41) / (1000x60x60x24x365) = 69年。
包括5位数据标识位和5位机器标识位,这10位决定了分布式系统中最多可以部署 1 << 10 = 1024 s个节点。超过这个数量,生成的ID就有可能会冲突。
这 12 位计数支持每个节点每毫秒(同一台机器,同一时刻)最多生成 1 << 12 = 4096个ID
加起来刚好64位,为一个Long型。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)ID按照时间在单机上是递增的。
缺点:
1)在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;这种方案的优缺点如下:
优点:
缺点:
对于MySQL性能问题,可用如下方案解决:在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11…)、TicketServer2的初始值为2(2,4,6,8,10…)。
美团Leaf
Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
具体可以参考官网说明:tech.meituan.com/MT_Leaf.htm…
原文:https://www.cnblogs.com/hongdada/p/12037827.html