W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给“茶壶”的hash值“100101”加权得 到:W= 100101*4 = 4 -4 -4 4 -4 4,给“饺子”的hash值“101011”加权得到:W=101011*5 = 5 -5 5 -5 5 5,其余特征向量类似此般操作。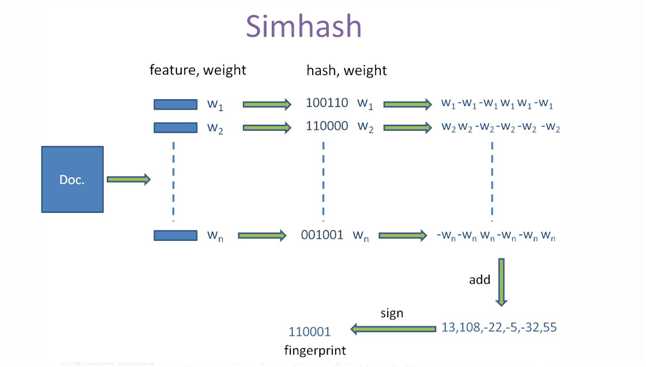
import json
import jieba
import jieba.analyse
import numpy as np
class Simhash(object):
def simhash(self,content):
keylist = []
#jieba分词
seg = jieba.cut(content)
#去除停用词永祥
jieba.analyse.set_stop_words("stopwords.txt")
#得到前20个分词和tf-idf权值
keywords = jieba.analyse.extract_tags("|".join(seg),topK=20,withWeight=True,allowPOS=())
a = 0
for feature,weight in keywords:
weight = int(weight * 20)
feature = self.string_hash(feature)
temp = []
for i in feature:
if i == "1":
temp.append(weight)
else:
temp.append(-1*weight)
keylist.append(temp)
list1 = np.sum(np.array(keylist),axis=0)
if keylist == []:
return "00"
simhash = ""
#降维处理
for i in list1:
if i>0:
simhash += "1"
else:
simhash += "0"
return simhash
def string_hash(self,source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2 ** 128 - 1
for c in source:
x = ((x * m) ^ ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
return str(x)
# x=str(bin(hash(source)).replace('0b','').replace('-','').zfill(64)[-64:])
# return x def hammingDis(s1,s2):
t1 = "0b" + s1
t2 = "0b" + s2
n = int(t1,2) ^ int(t2,2)
i = 0
while n:
n &= (n-1)
i += 1
print(i)
if i <= 18:
print("文本相似")
else:
print("文本不相似")
if __name__ == "__main__":
text1 = open("article1.txt","r",encoding="utf-8")
text2 = open("article2.txt","r",encoding="utf-8")
hammingDis(text1,text2)
text1.close()
text2.close()simhash算法的主要思想是降维,将高维的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两篇文章的f-bit指纹的Hamming Distance来确定文章是否重复或者高度近似。
下载
pip install simhash代码实现
from simhash import Simhash
def simhash_similarity(text1,text2):
a_simhash = Simhash(text1)
b_simhash = Simhash(text2)
print(a_simhash.value)
print(b_simhash.value)
max_hashbit = max(len(bin(a_simhash.value)),len(bin(b_simhash.value)))
print(max_hashbit)
#汉明距离
distince = a_simhash.distance(b_simhash)
print(distince)
similar = distince/max_hashbit
return similar
if __name__ == "__main__":
text1 = open("article1.txt","r",encoding="utf-8")
text2 = open("article2.txt","r",encoding="utf-8")
similar=simhash_similarity(text1,text2)
#相相似度
print(similar)
text1.close()
text2.close()原文:https://www.cnblogs.com/xujunkai/p/12038649.html