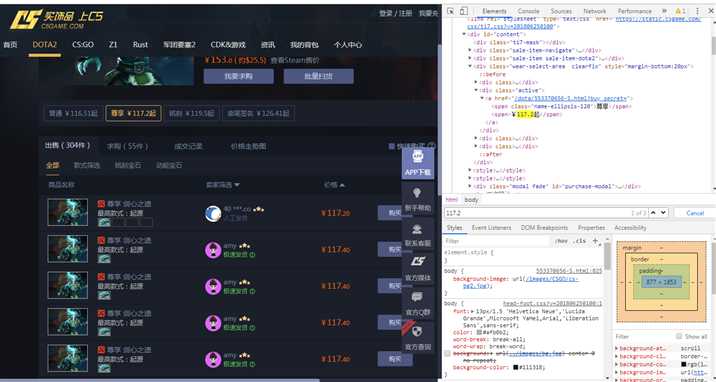
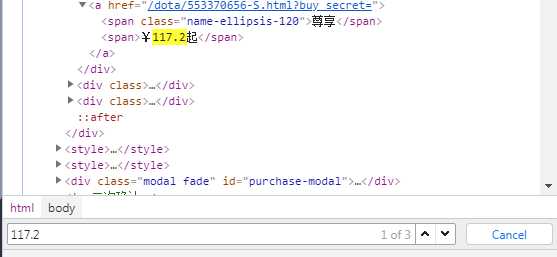
通过谷歌浏览器(F12)查看页面结构
import requests, matplotlib, re import matplotlib.pyplot as plt from bs4 import BeautifulSoup #url定位 def ahtml(url): a = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘} try: data = requests.get(url, headers=a) data.raise_for_status() data.encoding = data.apparent_encoding return data.text except: return " " #获取商品代码 def getcommodity(coms): for i in range(1, 3): html = ahtml(‘https://www.c5game.com/dota.html?quality=&hero=&type=&exterior=&tag=%E8%8F%A0%E8%8F%9C&page={}‘.format(i)) soup = BeautifulSoup(html, "html.parser") for span in soup.find_all("p", attrs="name"): temp = span.a.attrs[‘href‘] temp1 = temp.split(‘/‘)[2] temp2 = temp1.split(‘-‘)[0] coms.append(temp2) return coms #获取价格 def getprice(coms): count = [] html = ahtml(‘https://www.c5game.com/dota/history/{}.html‘.format(coms)) soup = BeautifulSoup(html, "html.parser") span = soup.find_all("span", attrs="ft-gold") i = 0 while i < 8: temp = span[i].string count.append(eval(temp.split(‘¥‘)[1])) i += 1 return count #获取饰品名称 def getname(coms): name = [] html = ahtml(‘https://www.c5game.com/dota/history/{}.html‘.format(coms)) soup = BeautifulSoup(html, "html.parser") span = soup.find_all("div", attrs="name-ellipsis") name.append(span[0].string) return name def ChartBroken(x, y, doc): plt.figure() plt.plot(x, y) plt.ylabel(‘Price‘) plt.xlabel(‘Times‘) plt.title(doc) plt.savefig(doc, dpi=600) plt.show() def ChartBar(x, y, doc): plt.figure() plt.bar(left=x, height=y, color=‘b‘, width=0.5) plt.ylabel(‘Price‘) plt.xlabel(‘Times‘) plt.title(doc) plt.savefig(doc, dpi=600) plt.show() #修正pandas绘图中文乱码问题 matplotlib.rcParams[‘font.sans-serif‘] = [‘SimHei‘] matplotlib.rcParams[‘font.family‘]=‘sans-serif‘ matplotlib.rcParams[‘axes.unicode_minus‘] = False #主函数 def main(): a = [] comslist = getcommodity(a)[0:3] i = 0 while i < 3: name = getname(comslist[i]) print(name) price = getprice(comslist[i]) print(price) ChartBroken([1, 2, 3, 4, 5, 6, 7, 8], price, name[0]) ChartBar([1, 2, 3, 4, 5, 6, 7, 8], price, name[0]) i += 1 if __name__ == ‘__main__‘: main()
1.爬取
#url定位 def ahtml(url): a = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36‘} try: data = requests.get(url, headers=a) data.raise_for_status() data.encoding = data.apparent_encoding return data.text except: return " " #获取商品代码并将无用信息删除 def getcommodity(coms): for i in range(1, 3): html = ahtml(‘https://www.c5game.com/dota.html?quality=&hero=&type=&exterior=&tag=%E8%8F%A0%E8%8F%9C&page={}‘.format(i)) soup = BeautifulSoup(html, "html.parser") for span in soup.find_all("p", attrs="name"): temp = span.a.attrs[‘href‘] temp1 = temp.split(‘/‘)[2] temp2 = temp1.split(‘-‘)[0] coms.append(temp2) return coms #获取价格 def getprice(coms): count = [] html = ahtml(‘https://www.c5game.com/dota/history/{}.html‘.format(coms)) soup = BeautifulSoup(html, "html.parser") span = soup.find_all("span", attrs="ft-gold") i = 0 while i < 8: temp = span[i].string count.append(eval(temp.split(‘¥‘)[1])) i += 1 return count #获取饰品名称 def getname(coms): name = [] html = ahtml(‘https://www.c5game.com/dota/history/{}.html‘.format(coms)) soup = BeautifulSoup(html, "html.parser") span = soup.find_all("div", attrs="name-ellipsis") name.append(span[0].string) return name
2.对数据进行清洗和处理
#获取商品代码并将无用信息删除 def getcommodity(coms): for i in range(1, 3): html = ahtml(‘https://www.c5game.com/dota.html?quality=&hero=&type=&exterior=&tag=%E8%8F%A0%E8%8F%9C&page={}‘.format(i)) soup = BeautifulSoup(html, "html.parser") for span in soup.find_all("p", attrs="name"): temp = span.a.attrs[‘href‘] temp1 = temp.split(‘/‘)[2] temp2 = temp1.split(‘-‘)[0] coms.append(temp2) return coms

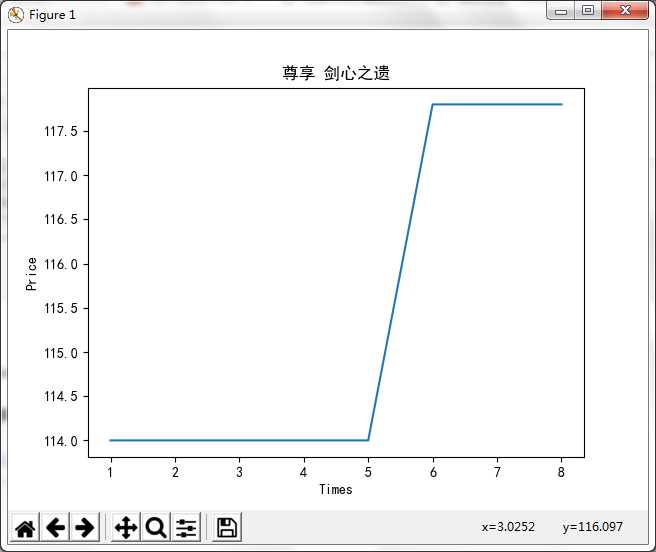
#数据保存 def ChartBroken(x, y, doc): plt.figure() plt.plot(x, y) plt.ylabel(‘Price‘) plt.xlabel(‘Times‘) plt.title(doc) plt.savefig(doc, dpi=600) plt.show() def ChartBar(x, y, doc): plt.figure() plt.bar(left=x, height=y, color=‘b‘, width=0.5) plt.ylabel(‘Price‘) plt.xlabel(‘Times‘) plt.title(doc) plt.savefig(doc, dpi=600) plt.show()
原文:https://www.cnblogs.com/smile1988/p/12045468.html