
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有
30%的值是缺失的。下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归
和随机梯度上升算法来预测病马的生死。
准备数据:处理被据中的缺失值
因为有时候数据相当昂贵,扔掉和重新获取
都是不可取的,所以必须采用一些方法来解决这个问题。
下面给出了一些可选的做法:

这里选择实数0来替换所有缺失值,恰好能适用于Logistic回归。这样做的直觉在
于 ,我们需要的是一个在更新时不会影响系数的值。回归系数的更新公式如下:

使 用 Logistic
回归方法进行分类并不需要做很多工作,所需做的只是把测试集上每个特征向量乘以最优化方法
得来的回归系数,再将该乘积结果求和,最后输人到sigmoid 函数中即可0 如果对应的sigmoid值
大于0.5就预测类别标签为1,否则为0。
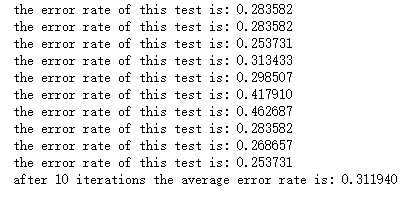
def classifyVector(inX, weights): prob = sigmoid(sum(inX*weights)) if prob > 0.5: return 1.0 else: return 0.0 def colicTest(): frTrain = open(‘F:\\machinelearninginaction\\Ch05\\horseColicTraining.txt‘) frTest = open(‘F:\\machinelearninginaction\\Ch05\\horseColicTest.txt‘) trainingSet = [] trainingLabels = [] for line in frTrain.readlines(): currLine = line.strip().split(‘\t‘) lineArr =[] for i in range(21): lineArr.append(float(currLine[i])) trainingSet.append(lineArr) trainingLabels.append(float(currLine[21])) trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000) errorCount = 0; numTestVec = 0.0 for line in frTest.readlines(): numTestVec += 1.0 currLine = line.strip().split(‘\t‘) lineArr =[] for i in range(21): lineArr.append(float(currLine[i])) if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]): errorCount += 1 errorRate = (float(errorCount)/numTestVec) print("the error rate of this test is: %f" % errorRate) return errorRate
def multiTest(): numTests = 10; errorSum=0.0 for k in range(numTests): errorSum += colicTest() print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))) multiTest()
小结:

吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
原文:https://www.cnblogs.com/tszr/p/12045453.html