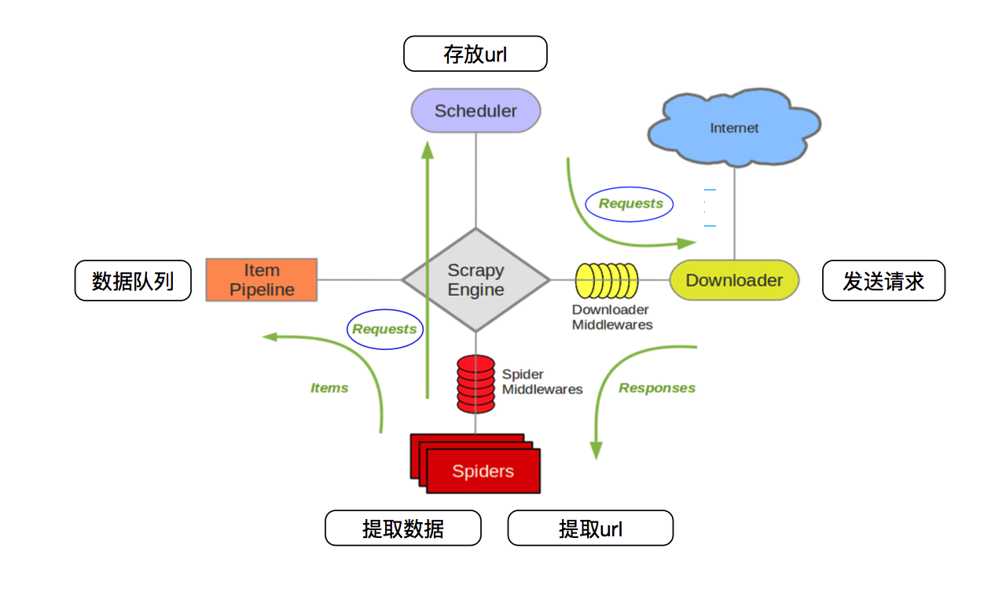
第一步:首先Spiders(爬虫)将需要发送请求的url(request)经过ScrapyEngine(引擎)交给Scheduler(调度器).
第二步:Scheduler(排序,入队)处理后,经过ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent,Proxy代理)交给Downloader.
第三步:Downloader向互联网发送请求,斌接受下载响应(response)。将响应(response)经过ScrapyEngine,SpiderMiddlewares(可选)交给Spiders.
第四步:Spiders处理response,提取数据并将数据经过ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。循环,提取url重新经过ScrapyEngine交给Scheduler进行下一个循环。知道无Url请求程序停止结束。直到无Url请求程序停止结束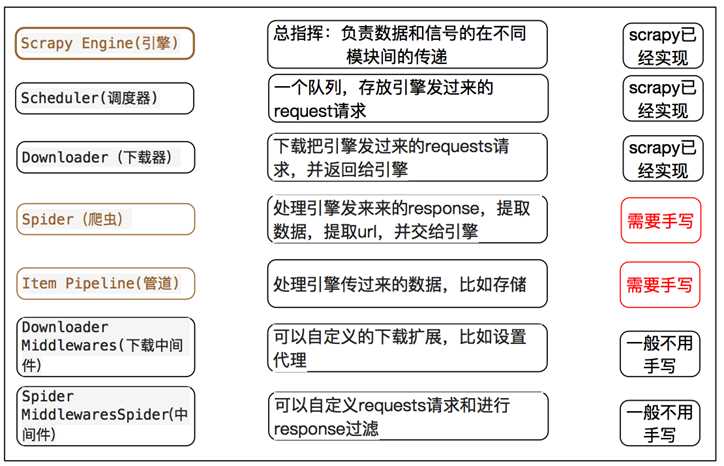
项目结构以及爬虫引用简介
project_name/
scrapy.cfg project_name/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py 爬虫1.py 爬虫2.py 爬虫3.py
使用scrapy解析文本内容时,可以使用每个应用中的response.xpath(xxx) 进行数据的解析。
Selector对象。selector对象可以继续xpath进行数据的解析。
response = HtmlResponse(url=‘http://example.com‘, body=html,encoding=‘utf-8‘) hxs = HtmlXPathSelector(response) print(hxs) # selector对象 hxs = Selector(response=response).xpath(‘//a‘) print(hxs) #查找所有的a标签 hxs = Selector(response=response).xpath(‘//a[2]‘) print(hxs) #查找某一个具体的a标签 取第三个a标签 hxs = Selector(response=response).xpath(‘//a[@id]‘) print(hxs) #查找所有含有id属性的a标签 hxs = Selector(response=response).xpath(‘//a[@id="i1"]‘) print(hxs) # 查找含有id=“i1”的a标签 # hxs = Selector(response=response).xpath(‘//a[@href="link.html"][@id="i1"]‘) # print(hxs) # 查找含有href=‘xxx’并且id=‘xxx’的a标签 # hxs = Selector(response=response).xpath(‘//a[contains(@href, "link")]‘) # print(hxs) # 查找 href属性值中包含有‘link’的a标签 # hxs = Selector(response=response).xpath(‘//a[starts-with(@href, "link")]‘) # print(hxs) # 查找 href属性值以‘link’开始的a标签 # hxs = Selector(response=response).xpath(‘//a[re:test(@id, "i\d+")]‘) # print(hxs) # 正则匹配的用法 匹配id属性的值为数字的a标签 # hxs = Selector(response=response).xpath(‘//a[re:test(@id, "i\d+")]/text()‘).extract() # print(hxs) # 匹配id属性的值为数字的a标签的文本内容 # hxs = Selector(response=response).xpath(‘//a[re:test(@id, "i\d+")]/@href‘).extract() # print(hxs) #匹配id属性的值为数字的a标签的href属性值 # hxs = Selector(response=response).xpath(‘/html/body/ul/li/a/@href‘).extract() # print(hxs) # hxs = Selector(response=response).xpath(‘//body/ul/li/a/@href‘).extract_first() # print(hxs) # ul_list = Selector(response=response).xpath(‘//body/ul/li‘) # for item in ul_list: # v = item.xpath(‘./a/span‘) # # 或 # # v = item.xpath(‘a/span‘) # # 或 # # v = item.xpath(‘*/a/span‘) # print(v)
备注:xpath中支持正则的使用: 用法 标签+[re:test(@属性值,"正则表达式")]
scrapy的持久化过程分为四个部分
首先,items定义传输的格式,其次,在爬虫应用中yield这个item对象,pipeline收到yield的item对象,进行持久化操作,这个过程中,settings中要进行相应的配置
items.py
# 规范持久化的格式
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url=scrapy.Field()
爬虫引用
import scrapy from myspider.items import MyspiderItem class ChoutiSpider(scrapy.Spider): name = ‘chouti‘ allowed_domains = [‘chouti.com‘] start_urls = [‘https://dig.chouti.com/‘] def parse(self, response): # print(response.text) a_list = response.xpath(‘//div[@id="content-list"]//div[@class="part1"]/a[@class="show-content color-chag"]/@href‘).extract() for url in a_list: yield MyspiderItem(url=url)
pipelines.py
class MyspiderPipeline(object): def __init__(self,file_path): self.f = None self.file_path = file_path @classmethod def from_crawler(cls,crawler): ‘‘‘ 执行pipeline类时,会先去类中找from_crawler的方法, 如果有,则先执行此方法,并且返回一个当前类的对象, 如果没有,则直接执行初始化方法 :param crawler: :return: ‘‘‘ # 可以进行一些初始化之前的处理,比如:文件的路径配置到settings文件中,方便后期的更改。 file_path = crawler.settings.get(‘PACHONG_FILE_PATH‘) return cls(file_path) def open_spider(self,spider): ‘‘‘ 爬虫开始时被调用 :param spider: :return: ‘‘‘ self.f = open(self.file_path,‘w‘,encoding=‘utf8‘) def process_item(self, item, spider): ‘‘‘ 执行持久化的逻辑操作 :param item: 爬虫yield过来的item对象 (一个字典) :param spider: 爬虫对象 :return: ‘‘‘ self.f.write(item[‘url‘]+‘\n‘) self.f.flush() #将写入到内存的文件强刷到文件中,防止夯住,不使用此方法会夯住 return item def close_spider(self,spider): ‘‘‘ 爬虫结束时调用 :param spider: :return: ‘‘‘ self.f.close()
备注:执行pipeline时,会先找from_crawler方法,这个方法中,我们可以设置一些settings文件中的配置,通过crawler.settings得到一个settings对象(配置文件对象) <scrapy.settings.Settings object at 0x000002525581F908>
执行pipeline中的process_item() 方法进行数据的持久化处理时,如果有多个pipeline(比如:将数据分别写入文件和数据库)时,先执行的pipeline(按照配置文件中数值的大小顺序执行),必须返回一个item对象,否则,后续的pipeline执行时,接收的item为None,无法进行数据的持久化操作,如果只是单纯的对某些数据进行一个持久化的处理,可以通过抛出异常,来阻止当前item对象后续的pipeline执行。抛出异常为:from scrapy.exceptions import DropItem 直接 raise DropItem()
return不返回item对象与抛异常的区别:无返回值或者返回值为None时,后续的pipeline会执行,只是,此时的item为None,而抛出异常,会跳过当前对象后续的pipeline,执行下一个item对象。
setting.py
ITEM_PIPELINES = {
‘myspider.pipelines.MyspiderPipeline‘: 300,
‘xxxxx.pipelines.FilePipeline‘: 400,
} # 每行后面的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
备注:数值小的先执行。
获取所有页面
import scrapy from myspider.items import MyspiderItem from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = ‘chouti‘ allowed_domains = [‘chouti.com‘] start_urls = [‘https://dig.chouti.com/‘] def parse(self, response): a_list = response.xpath(‘//div[@id="content-list"]//div[@class="part1"]/a[@class="show-content color-chag"]/@href‘).extract() for url in a_list: yield MyspiderItem(url=url) # 获取分页的url url_list = response.xpath(‘//div[@id="dig_lcpage"]//a/@href‘).extract() for url in url_list: url = ‘https://dig.chouti.com%s‘%url yield Request(url=url,callback=self.parse)
备注:通过yield 每一个request对象,将所有的页面url添加到调度器中。
scrapy框架会默认的将所有的结果进行去重操作。如果不去重,可以在request参数中,设置 dont_filter=True
class Spider(object_ref): def start_requests(self): cls = self.__class__ if method_is_overridden(cls, Spider, ‘make_requests_from_url‘): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won‘t be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: yield Request(url, dont_filter=True)
备注:在执行爬虫应用时,会先执行start_requests方法,所以我们可以重写此方法自定制。
返回的response中,无法通过 .cookies 获取cookie,只能通过从响应头中获取,但是获取的结果还得需要解析.
{b‘Server‘: [b‘Tengine‘], b‘Content-Type‘: [b‘text/html; charset=UTF-8‘], b‘Date‘: [
b‘Fri, 20 Jul 2018 13:43:42 GMT‘], b‘Cache-Control‘: [b‘private‘], b‘Content-Language‘: [b‘en‘],
b‘Set-Cookie‘: [b‘gpsd=5b05bcae8c6f4a273a53addfc8bbff22; domain=chouti.com; path=/; expires=Sun,
19-Aug-2018 13:43:42 GMT‘, b‘JSESSIONID=aaadbrXmU-Jh2_kvbaysw; path=/‘], b‘Vary‘: [b‘Accept-Encoding‘],
b‘Via‘: [b‘cache15.l2nu29-1[69,0], kunlun9.cn125[73,0]‘], b‘Timing-Allow-Origin‘: [b‘*‘],
b‘Eagleid‘: [b‘6a78b50915320942226762320e‘]}
所以,要通过scrapy封装的方法,将cookie解析出来
import scrapy
from scrapy.http.cookies import CookieJar
class ChoutiSpider(scrapy.Spider):
name = ‘chouti‘
allowed_domains = [‘chouti.com‘]
start_urls = [‘https://dig.chouti.com/‘]
cookie_dict = {}
def parse(self, response):
cookie_jar = CookieJar()
cookie_jar.extract_cookies(response,response.request)
for k, v in cookie_jar._cookies.items():
for i, j in v.items():
for m, n in j.items():
self.cookie_dict[m] = n.value
print(self.cookie_dict)
备注:CookieJar中封装的内容特别丰富,print(cookie_jar._cookies) 包含很多
{‘.chouti.com‘: {‘/‘: {‘gpsd‘: Cookie(version=0, name=‘gpsd‘, value=‘fcb9b9da7aaede0176d2a88cde8b6adb‘,
port=None, port_specified=False, domain=‘.chouti.com‘, domain_specified=True, domain_initial_dot=False,
path=‘/‘, path_specified=True, secure=False, expires=1534688487, discard=False, comment=None,
comment_url=None, rest={}, rfc2109=False)}}, ‘dig.chouti.com‘: {‘/‘: {‘JSESSIONID‘:
Cookie(version=0, name=‘JSESSIONID‘, value=‘aaa4GWMivXwJf6ygMaysw‘, port=None, port_specified=False,
domain=‘dig.chouti.com‘, domain_specified=False, domain_initial_dot=False, path=‘/‘,
path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={},
rfc2109=False)}}}
备注:爬取过程中的坑:请求头中,一定要携带content-type参数。请求过程中的url不能重复,尤其是和起始url。
我们可以使用urllib中的urlencode帮我们把数据转化为formdata格式的.
from urllib.parse import urlencode
ret = {‘name‘:‘xxx‘,‘age‘:18}
print(urlencode(ret))
原文:https://www.cnblogs.com/superSmall/p/12046177.html
