1.进入地址我们可以发现,页面有着非常整齐的目录,那么网页源代码中肯定也有非常规律的目录,进去看看吧。如果你看不懂,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,进步更快哦!
2.很明显猜对了,源代码中确实有这很明显的规律,每一章节都有着及其固定的模板:
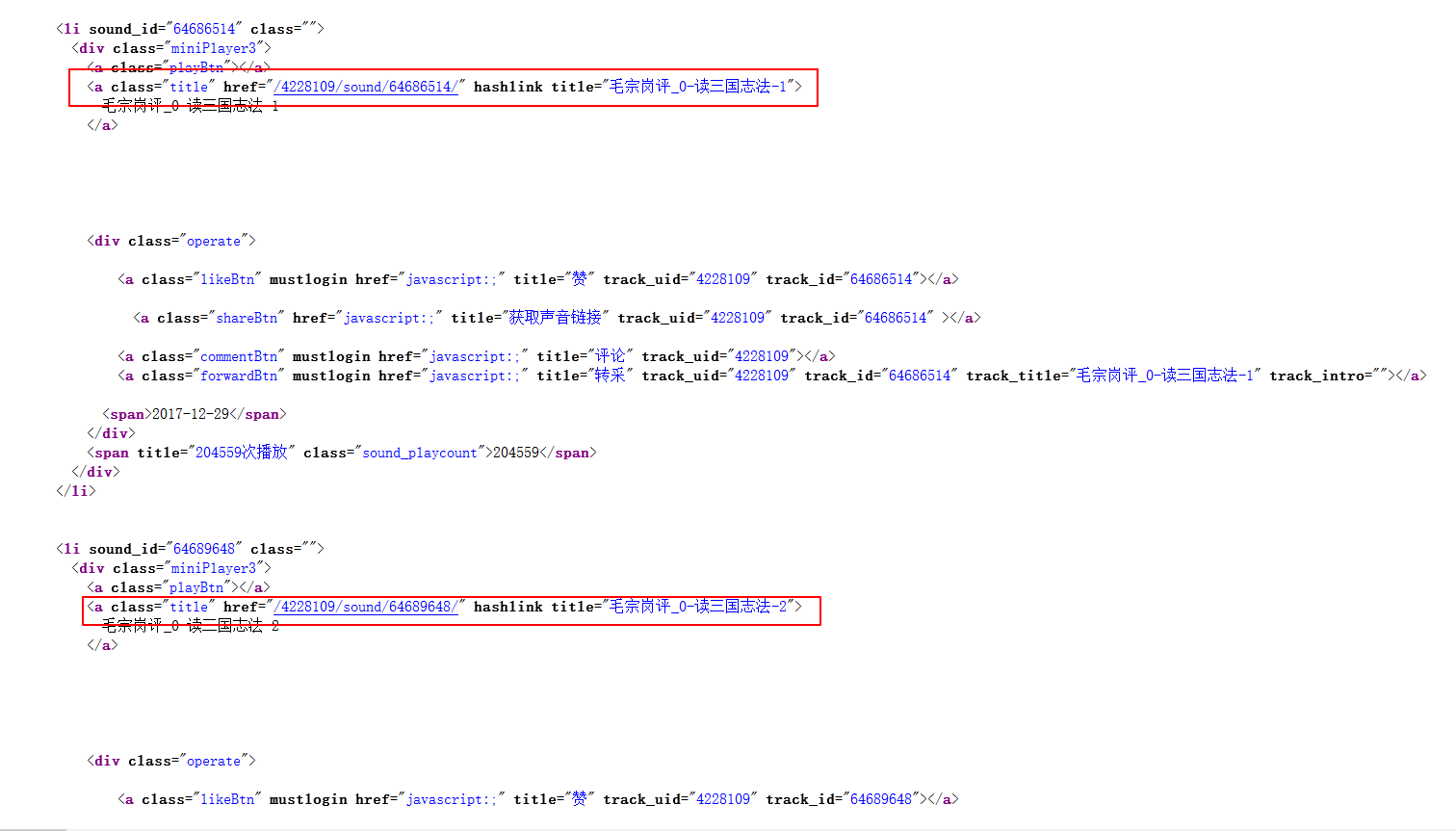
但是这时候我们并找不到深层的规律,那么下一步我们尝试下播放一条音频,但不仅仅是播放,更重要的是要抓包!!!
3.打开浏览器抓包工具(F12),点击任意一条音频,这里我就以第一条为例了。
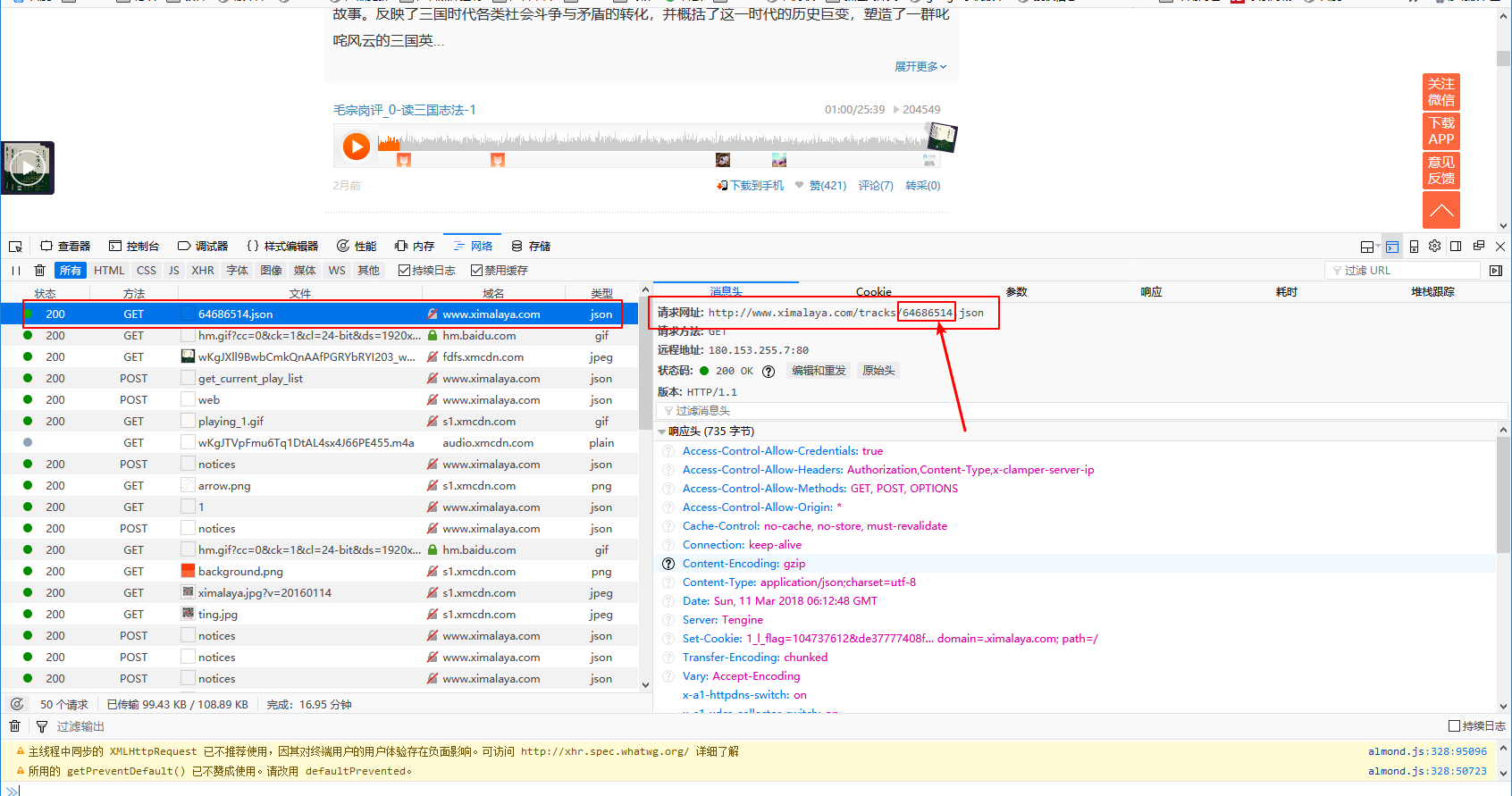
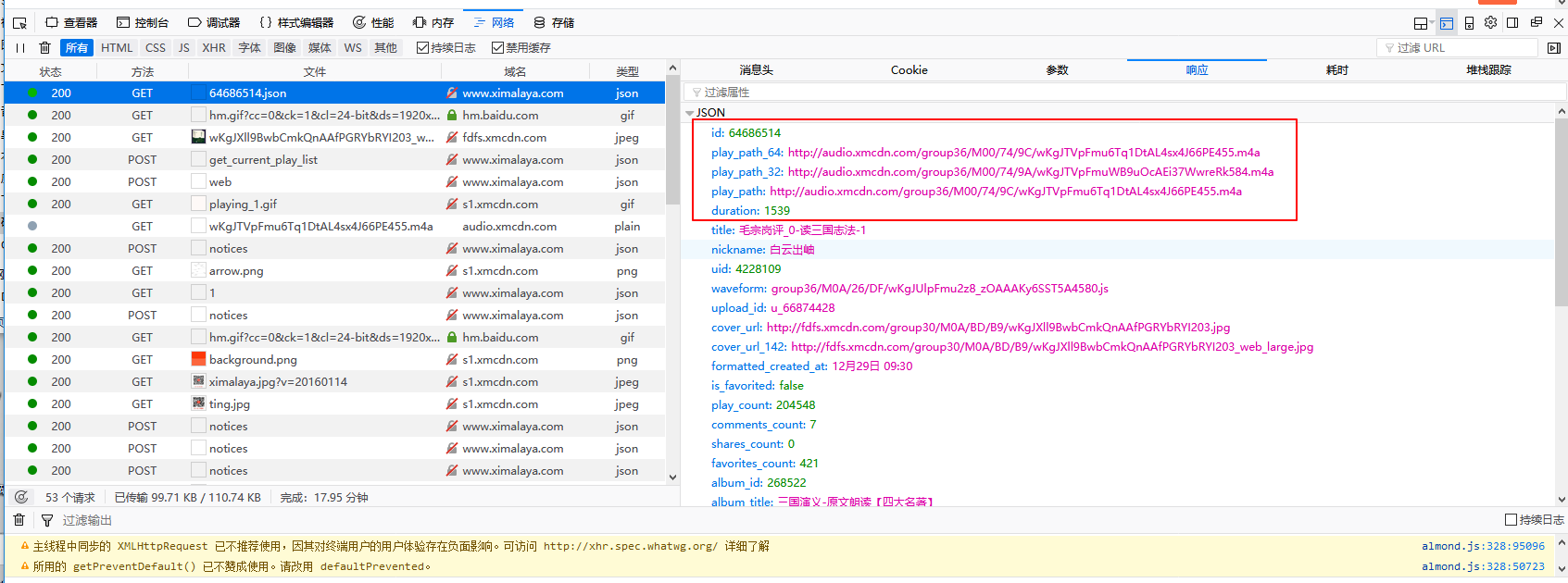
上面两张图是我抓取到的getURL和返回的json,可以看出返回的内容里确实有三条音频地址,复制到浏览器可以直接播放,听一听就是我们要的宝贝。重点来了,getURL中我圈出来的看着是不是很眼熟?不错,那个就是网页源代码里面每个章节URL里的一个值,而这个值就是每个章节的sound_id,再按照上面的步骤,操作其他章节看看,也是一样的规律。那么思路很清晰了,我们只需要把每个章节的ID的sound_id替换到getURL中不就可以获取到每个章节的音频了么?
4.开始写代码:
-
-
-
-
-
header = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘}
-
html = requests.get(‘http://www.ximalaya.com/4228109/album/268522/‘,headers=header)
-
-
reg = ‘<a class="title" href="/4228109/sound/(.*?)/" hashlink title="(.*?)">‘
-
name_url = re.findall(reg,html.text)
-
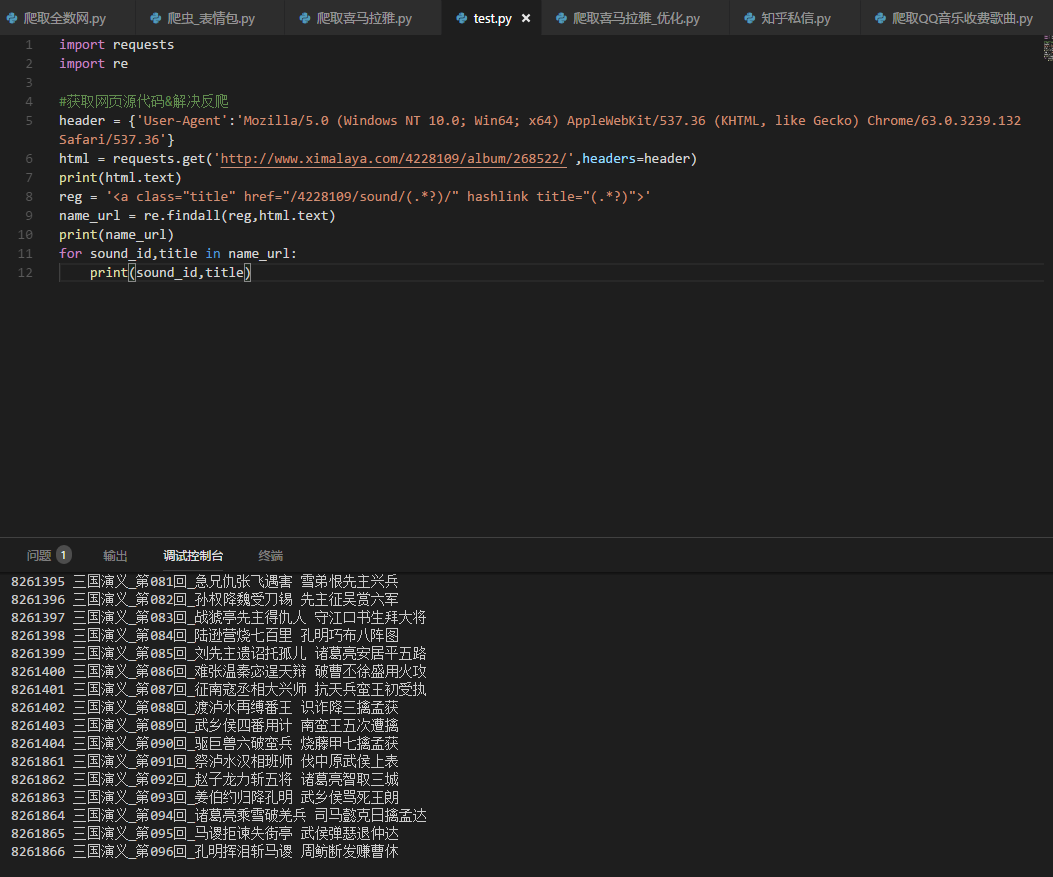
这个时候我们可以看到,网页每个章节和对应sound_id都被找出来了。
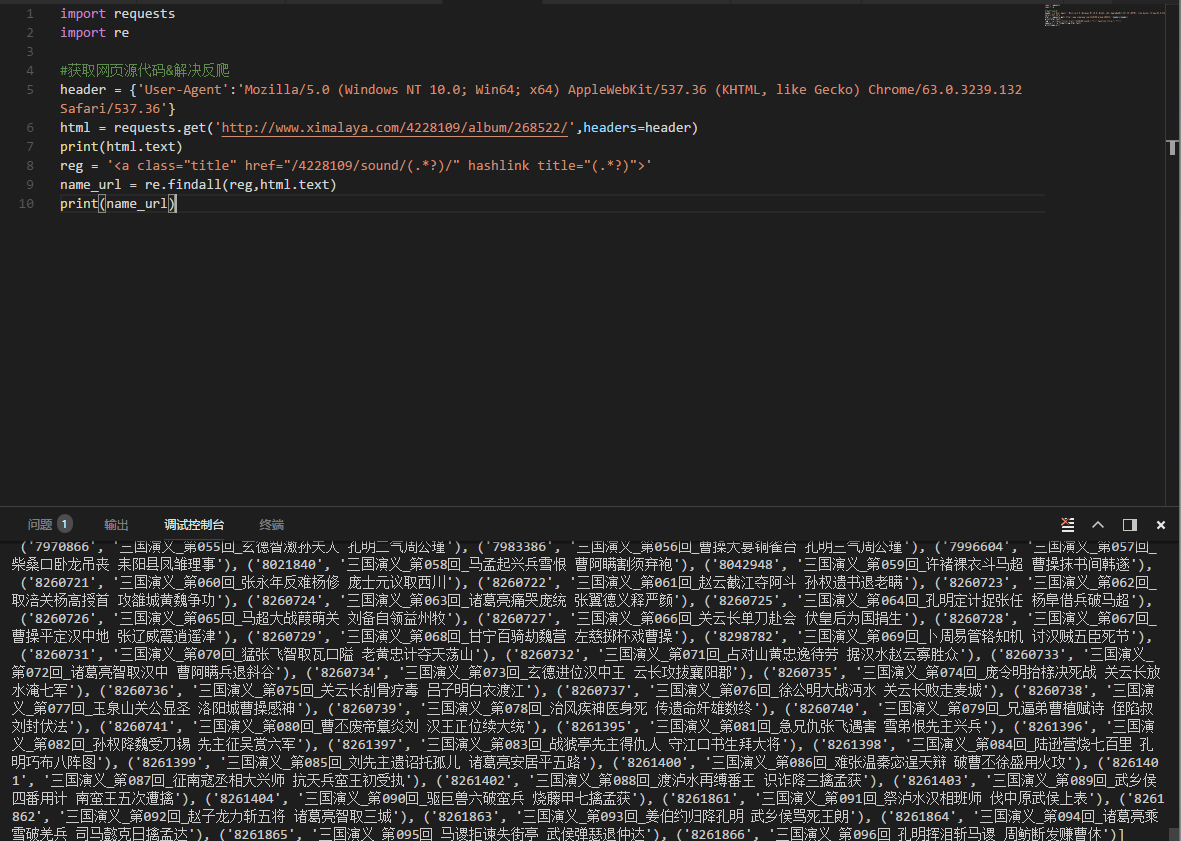
5.返回的有没有很乱?确实很乱,但是返回的都是元组类型,那么我们来定义一个ID和标题吧。
-
for sound_id,title in name_url:
-
看下效果,有没有耳目一新:
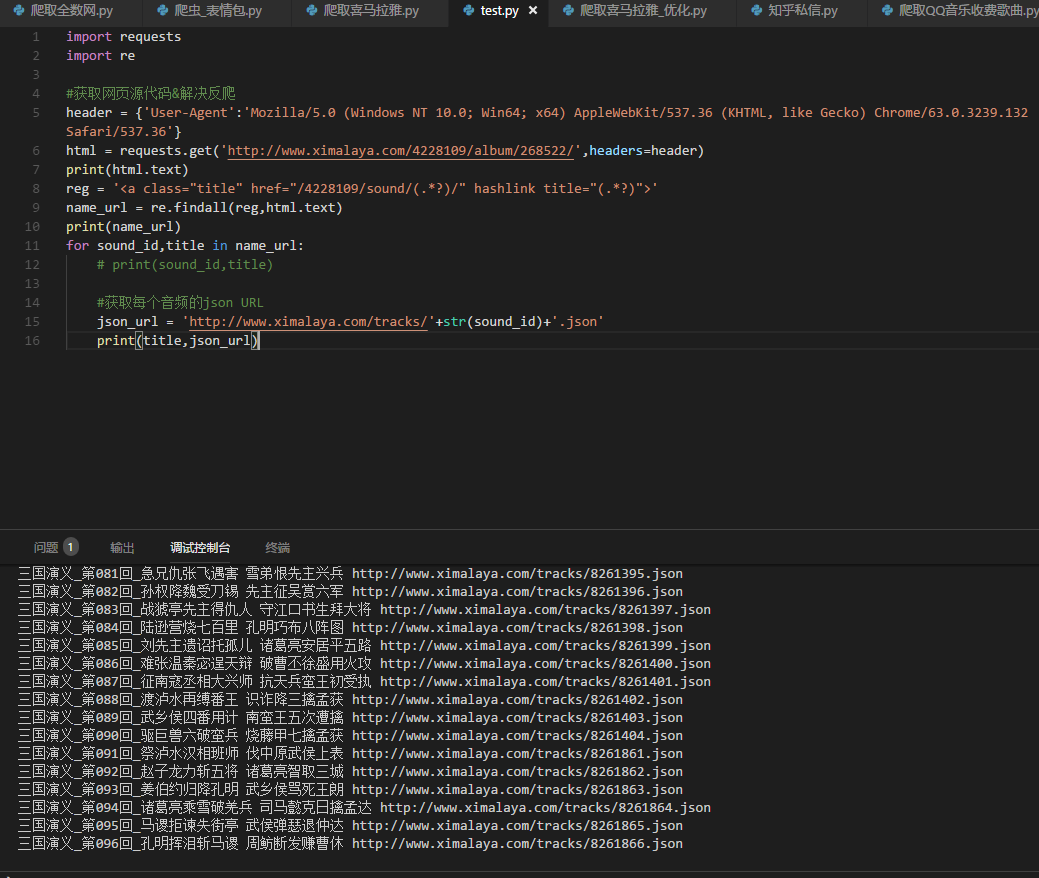
6.好了,回到最开始我们抓包的时候,我们的音频都在一个抓取的json里,开始拼接咱们的json URL
-
json_url = ‘http://www.ximalaya.com/tracks/‘+str(sound_id)+‘.json‘
-
7.既然已经获取到了每个URL,那么现在去json里面取最终的音频URL吧
首先去请求下每个音频的json URL,然后正在匹配出最终的URL吧,另外如果你刚学不久,建议如果你看不懂,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题多跟里面的人交流,进步更快哦!
-
-
json_url = ‘http://www.ximalaya.com/tracks/‘+str(sound_id)+‘.json‘
-
-
-
result = requests.get(json_url,headers=header)
-
reg1 = ‘"play_path_64":"(.*?)"‘
-
-
-
sound_url = re.findall(reg1,result.text)
-
-
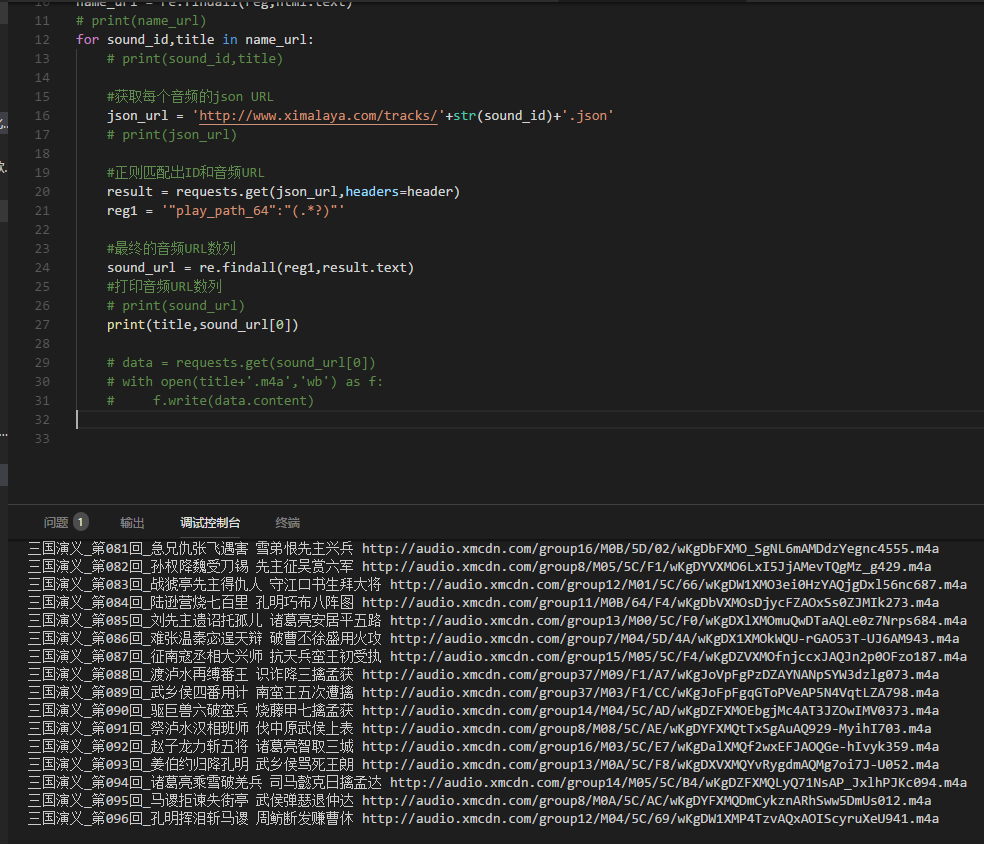
8.好了,URL都拿到了,可以去下载了。。。
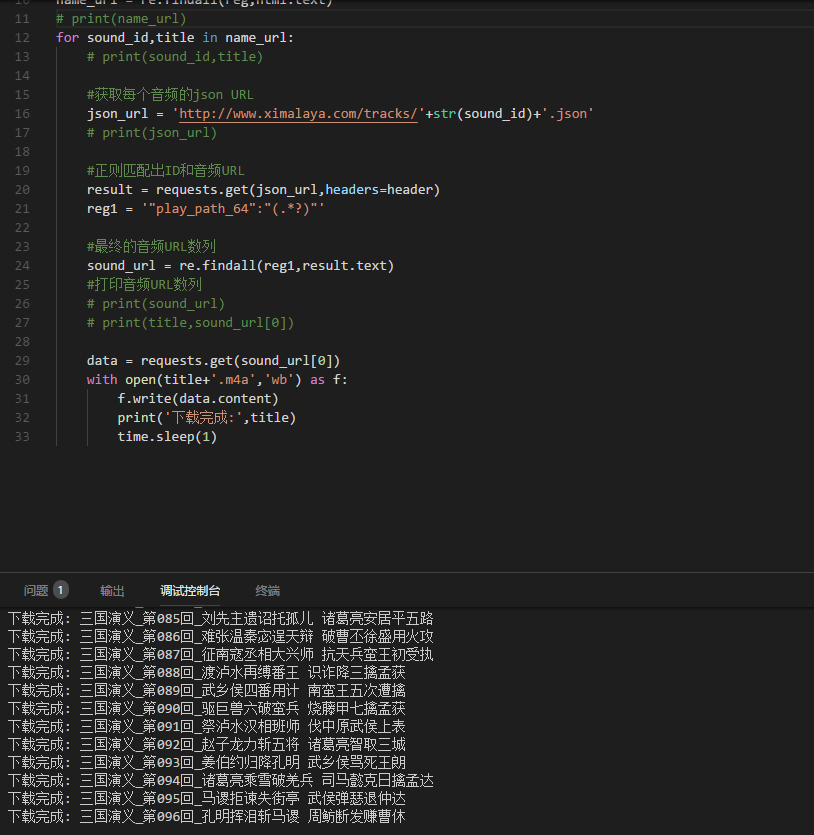
最后,贴上完整代码:
-
-
-
-
-
-
header = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘}
-
html = requests.get(‘http://www.ximalaya.com/4228109/album/268522/‘,headers=header)
-
-
reg = ‘<a class="title" href="/4228109/sound/(.*?)/" hashlink title="(.*?)">‘
-
name_url = re.findall(reg,html.text)
-
-
for sound_id,title in name_url:
-
-
-
-
json_url = ‘http://www.ximalaya.com/tracks/‘+str(sound_id)+‘.json‘
-
-
-
-
result = requests.get(json_url,headers=header)
-
reg1 = ‘"play_path_64":"(.*?)"‘
-
-
-
sound_url = re.findall(reg1,result.text)
-
-
-
-
-
data = requests.get(sound_url[0])
-
with open(title+‘.m4a‘,‘wb‘) as f:
-
-
-
