
game为游戏列表,p=为页数。
2.Htmls页面解析
所需要的信息在class名字为list_app_title,list_app_info,list_app_count的标签中。
3.节点(标签)查找方法与遍历方法
import requests from bs4 import BeautifulSoup import os, matplotlib import matplotlib.pyplot as plt # 爬取酷安网的游戏列表信息 def getHTMLText(url): try: # 获取酷安网的游戏页面 r = requests.get(url="https://www.coolapk.com/game/") # 判断是否调用成功,注:返回值为200的状态码才是可以正常爬取 r.raise_for_status() # 使用HTML页面的编码方式以免出现乱码的行为 r.encoding = r.apparent_encoding # 返回爬取成功的页面内容 return r.text except: return "爬取失败" # 爬取游戏名称 def getGameName(ulist1, html): # 使用之前导入的BeautifulSoup包创建对象 soup = BeautifulSoup(html, "html.parser") # 使用find_all()方法遍历所有class名为list_app_title的p标签 for p in soup.find_all("p", attrs="list_app_title"): # 将p标签中的list_app_title标签中的内容存放在ulist1列表中 ulist1.append(str(p.string).strip()) # 返回列表 return ulist1 # 爬取游戏评分 def getScore(ulist2, html): # 使用之前导入的BeautifulSoup包创建对象 soup = BeautifulSoup(html, "html.parser") # 使用find_all()方法遍历所有class名为list_app_info的p标签 for p in soup.find_all("p", attrs="list_app_info"): # 将p标签中的特定内容存放在ulist2列表中 ulist2.append(("".join(list(p.text)[0:3]))) # 返回列表 return ulist2 # 爬取游戏下载次数 def getDownloadsAmount(ulist3, html): # 使用之前导入的BeautifulSoup包创建对象 soup = BeautifulSoup(html, "html.parser") # 使用find_all()方法遍历所有class名为list_app_count的span标签 for span in soup.find_all("span", attrs="list_app_count"): # 将span标签中的特定内容存放在ulist3列表中 ulist3.append("".join(list(span.text)[0:8])) # 返回列表 return ulist3 # 爬取游戏大小 def getGameSize(ulist4, html): # 使用之前导入的BeautifulSoup包创建对象 soup = BeautifulSoup(html, "html.parser") # 使用find_all()方法遍历所有class名为list_app_info的p标签 for p in soup.find_all("p", attrs="list_app_info"): # 将span标签中的特定内容存放在ulist4列表中 ulist4.append("".join(list(p.text)[4:14])) # 返回列表 return ulist4 # 将获取到的数据全部打印出来 def printUnivList(ulist1, ulist2, ulist3,ulist4, num): # 打印标题 print("{0:^30}\t{1:^20}\t{2:^20}\t{3:^20}".format("游戏名称", "游戏评分","游戏下载次数","游戏大小")) # 打印主要内容 for i in range(num): print("{0:^30}\t{1:^20}\t{2:^20}\t{3:^20}".format(ulist1[i], ulist2[i], ulist3[i],ulist4[i])) # 数据保存函数 def dataSave(ulist1, ulist2, ulist3,ulist4,num): try: # 创建文件夹 os.mkdir("D:\\酷安网游戏信息\\") except: # 如果文件夹存在则什么也不做 "" try: # 创建文件用于存储爬取到的数据 with open("D:\\酷安网游戏信息\\爬取结果.txt" , "w",encoding=‘utf8‘) as f: f.write("{0:^30}\t{1:^20}\t{2:^20}\t{3:^20}\n".format("游戏名称", "游戏评分","游戏下载次数","游戏大小")) for i in range(num): f.write("{0:^30}\t{1:^20}\t{2:^20}\t{3:^20}\n".format(ulist1[i], ulist2[i], ulist3[i],ulist4[i])) except: "存储失败" #修正pandas绘图中文乱码问题 matplotlib.rcParams[‘font.sans-serif‘] = [‘SimHei‘] matplotlib.rcParams[‘font.family‘]=‘sans-serif‘ matplotlib.rcParams[‘axes.unicode_minus‘] = False # 折线图可视化 def Zhexiantu(x, y): #图片在额外的窗口显示 plt.plot(x, y) #y轴命名 plt.ylabel(‘游戏得分‘) #x轴命名 plt.xlabel(‘游戏名字‘) # plt.axis([0, 1, 0, 10]) plt.title(‘游戏评分-折线图比较‘) # 保存程序结果,数据持久化 plt.savefig(‘Broken‘, dpi=300) # 使x轴文字竖向显示 plt.xticks(rotation=270) print(‘折线图保存成功‘) plt.show() # 主函数 def main(): # 酷安网网站 url = "https://www.coolapk.com/game/" # 用来存放游戏名称 gameName= [] # 用来存放游戏得分 gameScore = [] # 用来存放游戏下载数量 downloadAmount = [] # 用来存放游戏大小 gameSize=[] html = getHTMLText(url) # 获取游戏名称并存放在相关的列表中 getGameName(gameName, html) # 获取游戏得分并存放在相关的列表中 getScore(gameScore, html) # 获取游戏下载数量并存放在相关的列表中 getDownloadsAmount(downloadAmount, html) # 获取游戏大小并存放在相关的列表中 getGameSize(gameSize, html) try: # 将目标信息打印出来 printUnivList(gameName,gameScore,downloadAmount,gameSize,20) except: # 如果招聘信息不足,则引发异常。 print("无更多招聘信息。") #将数据存储 dataSave(gameName,gameScore,downloadAmount,gameSize, 20) #可视化操作 Zhexiantu(gameName, gameScore) if __name__==‘__main__‘: main()
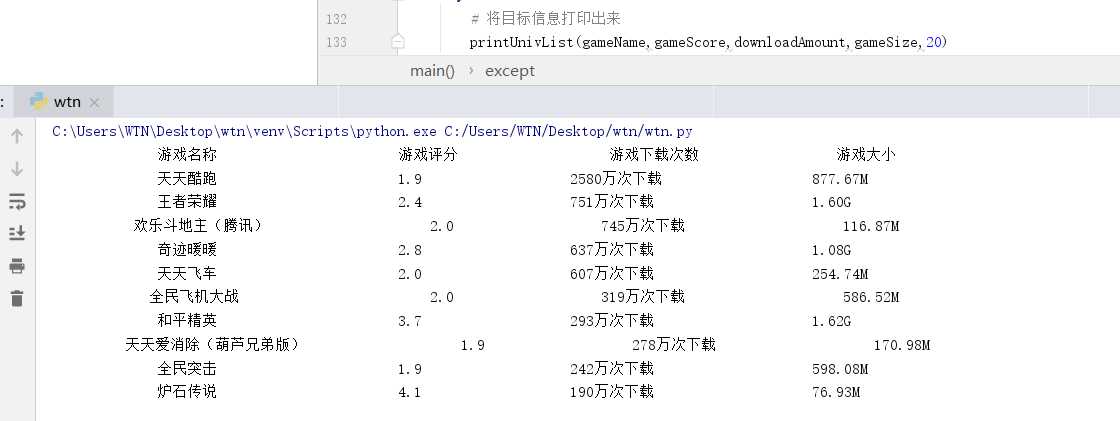
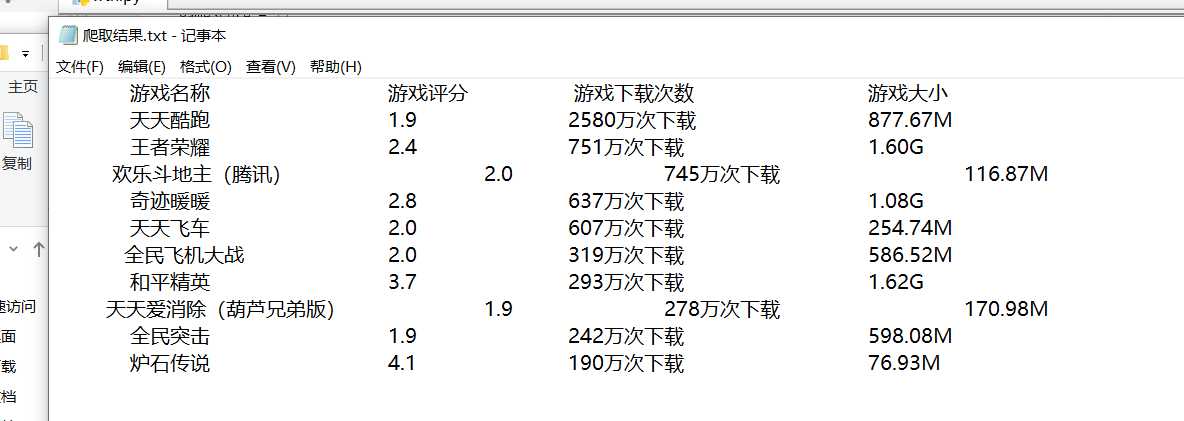
txt文件生成结果
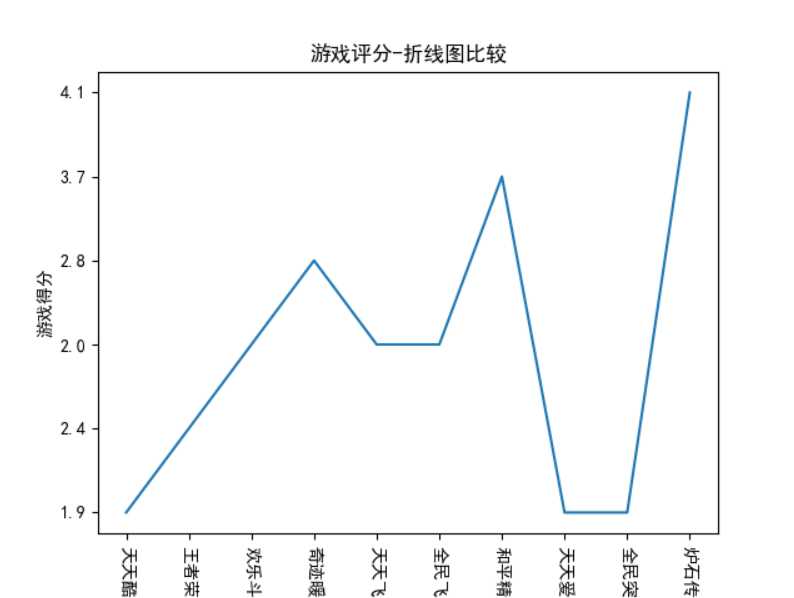
可视化结果
原文:https://www.cnblogs.com/naytyns/p/12049518.html