一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
中国天气网的数据爬取与分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取全国所有的城市白天天气, 晚上天气, 白天温度, 晚上温度, 日出时间, 日落时间, 平均温度, 风力等级, 降水量, 平均湿度的信息并加以分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
通过对整个网页的爬取获得的数据进行费雷和分析,然后总结出全国各地各个地方的天气情况
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
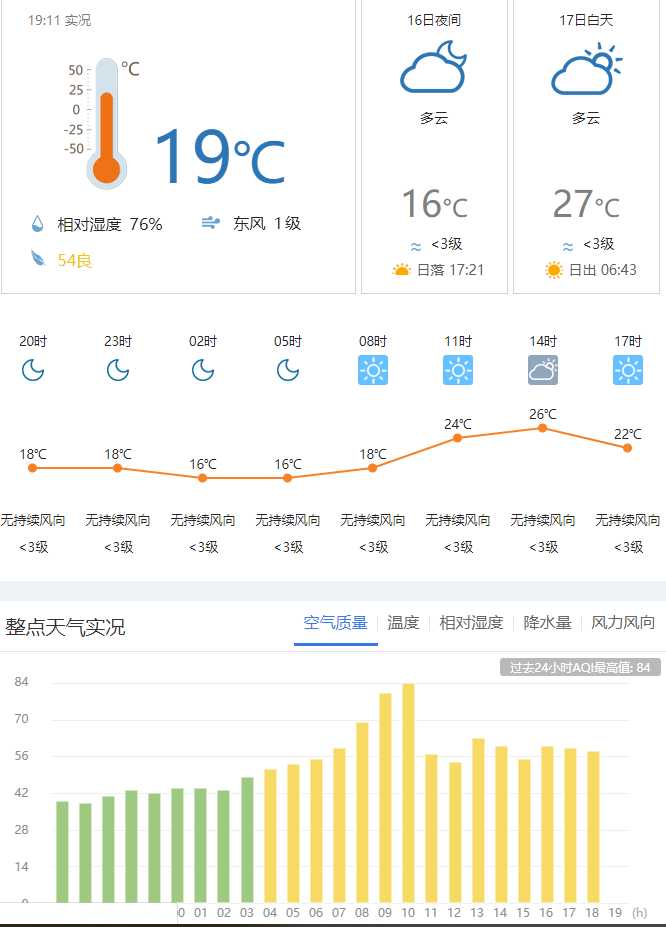
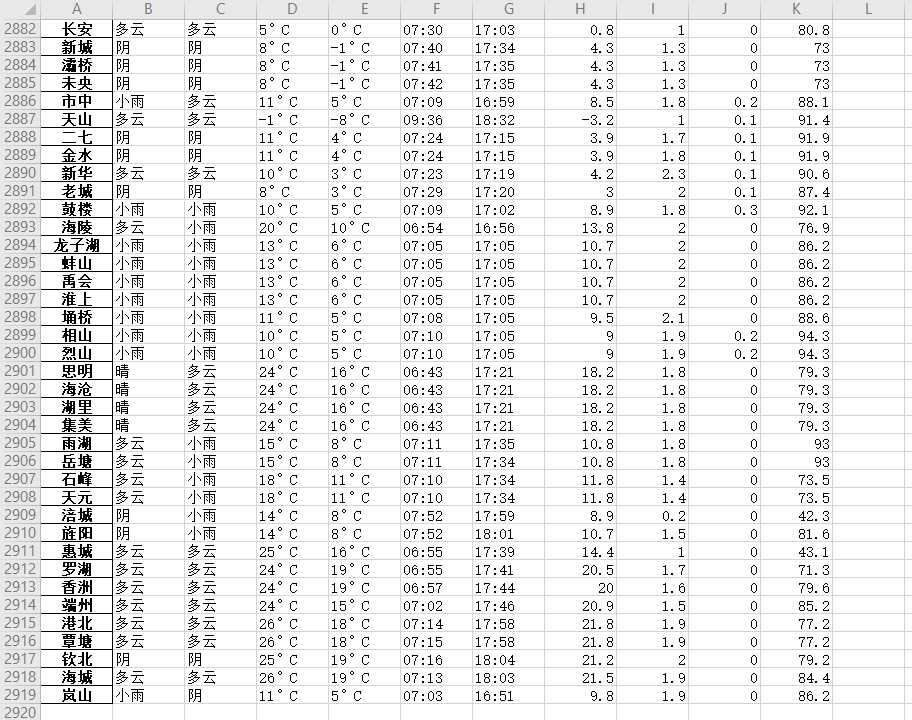
对中国所有地区共2919个数据进行爬取分析
2.Htmls页面解析


3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
根据F12中的数据查找到相应位置并requests.get(),再利用正则找到正确的数据并保存起来
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests import re import pandas as pd def mainpage(): """ http://www.weather.com.cn/weather1d/101140210.shtml 打开城市列表及对应的id以便进行url获取 "http://www.weather.com.cn/weather1d/" + 城市id + ".shtml" """ with open(‘城市列表.txt‘, ‘r‘, encoding=‘UTF-8‘) as f: sss = f.readlines() sss = sss[0] # 通过正则拿出城市的id以及城市名称 req = r‘name’: ‘(.*?)’, ‘id’: ‘(.*?)’‘ re1 = re.findall(req, sss) # print(re1[0][1]) # 逐个打开城市的天气页面获取数据 for n in range(len(sss)): url = "http://www.weather.com.cn/weather1d/" + re1[n][1] + ".shtml" # 获取页面 url_html = requests.get(url) # 配置页面编码 url_html.encoding = "utf-8" # print(url_html.text) # 获取天气信息 re_weather = re.compile(r‘<p\sclass="wea"\stitle=".*?">(.*?)</p>‘) re_weather_search = re_weather.findall(url_html.text) try: # 白天天气 daytime_weather = re_weather_search[0] # 黑夜天气 daynight_weather = re_weather_search[1] except: pass # <p class="tem"><span>3</span><em>°C</em></p> # 获取温度信息 re_temperature = re.compile(r‘<p\sclass="tem">\n<span>(.*?)</span><em>(.*?)</em>\n</p>‘) re_temperature_search = re_temperature.findall(url_html.text) try: # 白天温度 daytime_temperature = re_temperature_search[0][0] + re_temperature_search[0][1] # 黑夜温度 daynight_temperature = re_temperature_search[1][0] + re_temperature_search[1][1] except: pass # <p class ="sun sunUp"><i></i><span>日出 07:27</span></p> # 获取太阳信息 re_sun = re.compile(r‘<p\sclass="sun\ssun.*?"><i></i>\n<span>.{3}(.*?)</span>\n</p>‘) re_sun_search = re_sun.findall(url_html.text) # 日出时间 try: daytime_sunup = re_sun_search[0] # 日落时间 daynight_sundown = re_sun_search[1] except: pass # 温度,风力等级,降水量,湿度 re_mul = re.compile( r‘{"od21":".*?","od22":"(.*?)","od23":".*?","od24":".*?","od25":"(.*?)","od26":"(.*?)","od27":"(.*?)",‘ r‘"od28":".*?"}‘) re_mul_search0 = re_mul.findall(url_html.text) # 把空值或者null替换成0 re_mul_search = [] for each in re_mul_search0: each = list(each) for z in each: if z == ‘‘ or z == "null": q = each.index(z) each.pop(q) each.insert(q, 0) re_mul_search.append(each) sum0 = 0 # 获取当日的平均温度 for i in range(len(re_mul_search) - 1): sum0 = sum0 + int(re_mul_search[i][0]) eval_temperature = sum0 / (len(re_mul_search) - 1) sum1 = 0 # 获取当日的平均风力等级 for i in range(len(re_mul_search) - 1): sum1 = sum1 + int(re_mul_search[i][1]) eval_wind = sum1 / (len(re_mul_search) - 1) sum2 = 0.0 # 获取当日的平均降水量 for i in range(len(re_mul_search) - 1): sum2 = sum2 + float(re_mul_search[i][2]) eval_water = sum2 / (len(re_mul_search) - 1) sum3 = 0.0 # 获取当日的平均湿度 for i in range(len(re_mul_search) - 1): sum3 = sum3 + float(re_mul_search[i][3]) eval_humidity = sum3 / (len(re_mul_search) - 1) city_list.append(re1[n][0]) ever_city_list = [] ever_city_list.append(daytime_weather) ever_city_list.append(daynight_weather) ever_city_list.append(daytime_temperature) ever_city_list.append(daynight_temperature) ever_city_list.append(daytime_sunup) ever_city_list.append(daynight_sundown) ever_city_list.append(round(eval_temperature, 1)) ever_city_list.append(round(eval_wind, 1)) ever_city_list.append(round(eval_water, 1)) ever_city_list.append(round(eval_humidity, 1)) totle_city_list.append(ever_city_list) # 设置表格 pd.set_option(‘display.unicode.ambiguous_as_wide‘, True) pd.set_option(‘display.unicode.east_asian_width‘, True) columns_list = ["白天天气", "晚上天气", "白天温度", "晚上温度", "日出时间", "日落时间", "平均温度", "风力等级", "降水量", "平均湿度"] df = pd.DataFrame(totle_city_list, index=city_list, columns=columns_list) df.name = "城市气候总结" # 把表格打印出来 df.to_excel(‘城市气候总结.xlsx‘) # 所有城市列表 city_list = [] # 每个城市数据 totle_city_list = [] mainpage()
2.对数据进行清洗和处理
import pandas as pd import matplotlib.pyplot as plt from pandas import Series from pylab import mpl # 指定默认字体:解决plot不能显示中文问题 mpl.rcParams[‘font.sans-serif‘] = [‘Microsoft YaHei‘] # 解决保存图像是负号‘-‘显示为方块的问题 mpl.rcParams[‘axes.unicode_minus‘] = False # 数据对齐 pd.set_option(‘display.unicode.ambiguous_as_wide‘, True) pd.set_option(‘display.unicode.east_asian_width‘, True) # 读取爬到的数据 df = pd.read_excel(r‘D:\pycharm\workspace\城市气候总结.xlsx‘) df.shape print(df.head()) # 查看是否有重复值 print(df.duplicated()) # 数据去重 df.drop_duplicates([‘title‘, ‘username‘]).shape # 查看数据的整体分布 print(df.describe())
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
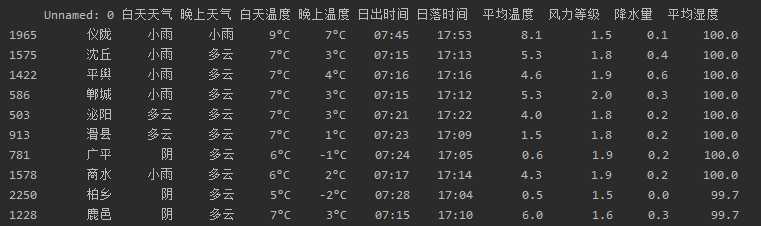
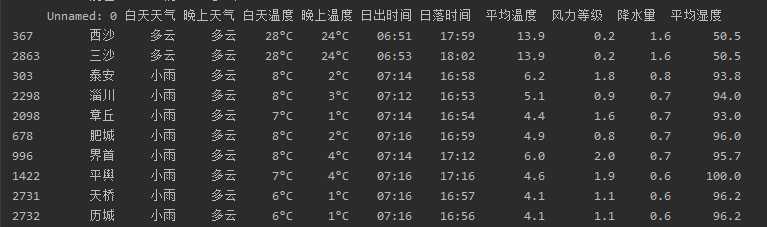
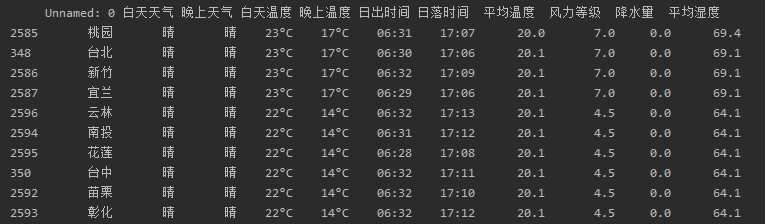
# 平均湿度前十的城市 print(df.sort_values(‘平均湿度‘,ascending=False).head(10)) # 降水量前十的城市 print(df.sort_values(‘降水量‘,ascending=False).head(10)) # 风力等级前十的城市 print(df.sort_values(‘风力等级‘,ascending=False).head(10))
# 了解这一天白天天气和晚上天气的情况 daytime_list = [] for val in df[‘白天天气‘].dropna(): daytime_list.append(val) daytime_series = Series(daytime_list).drop_duplicates() print(daytime_series) daynight_list = [] for val in df[‘晚上天气‘].dropna(): daynight_list.append(val) daynight_series = Series(daynight_list).drop_duplicates() print(daynight_series)
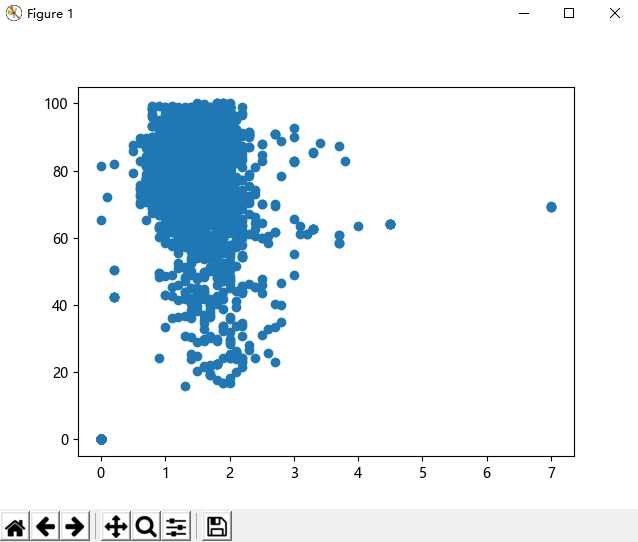
plt.scatter(df[‘风力等级‘], df[‘平均湿度‘]) plt.show()
5.数据持久化
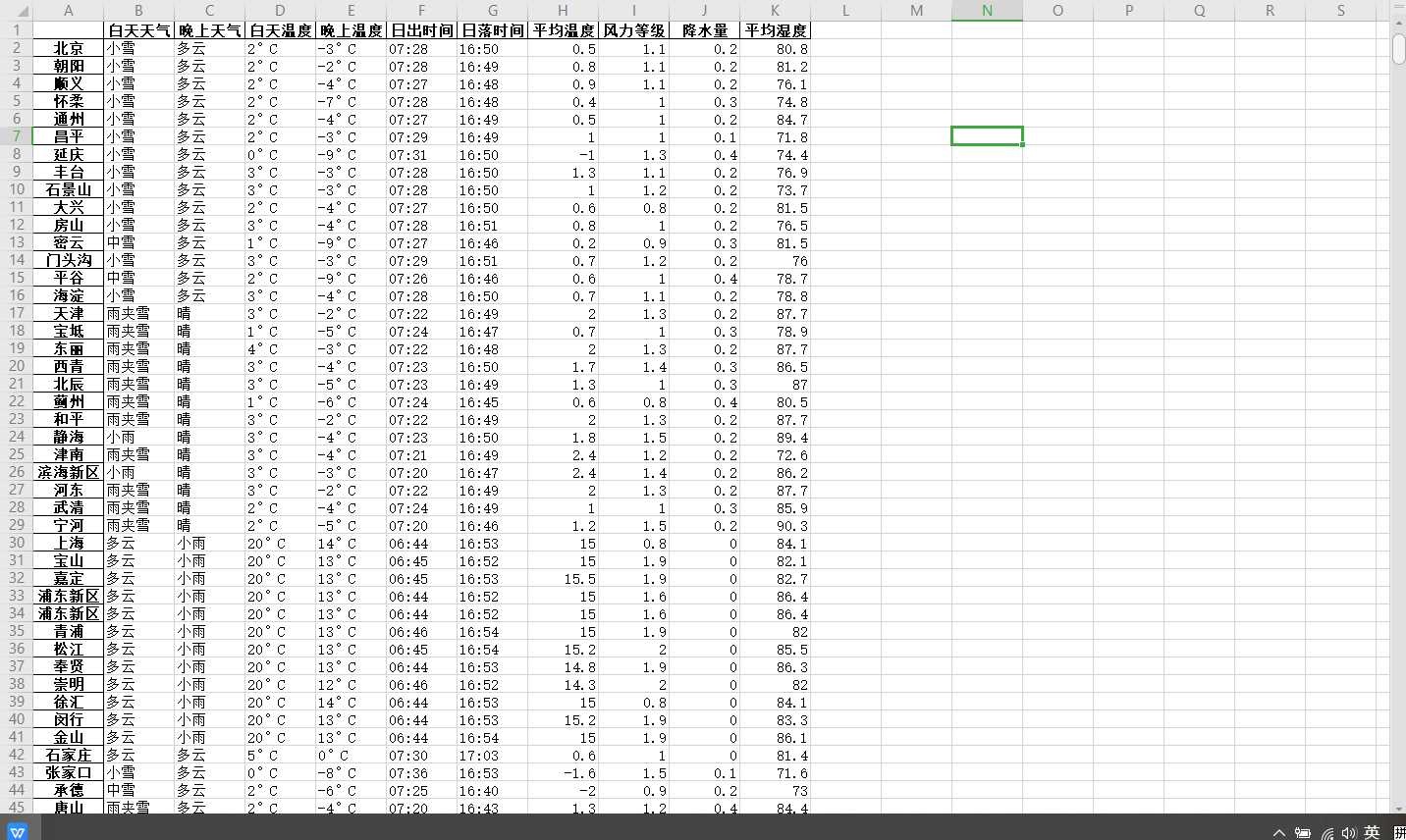
# 把表格打印出来 df.to_excel(‘城市气候总结.xlsx‘)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
根据以上的信息可以发现湿度高的城市基本位于河南地区,降水量大的地方大多数是山东地区,而风力大的地方都在台湾。根据散点图可以观察出大部分地区:风力等级1-2级,平均湿度40-100
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次的作业我学到了很多的知识,发现这门课学的是真的有趣,也希望今后能够多多学习本课程。
原文:https://www.cnblogs.com/piggggest/p/12051226.html