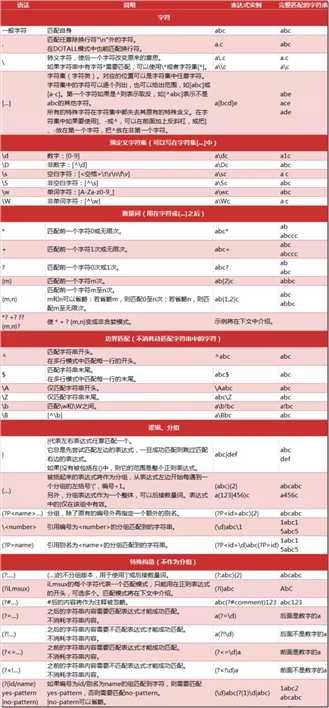
//正则表达式是一种特殊的字符串模式,用于匹配一组字符串,就好比用模具做产品,而正则就是这个模具,定义一种规则去匹配符合规则的字符。
//以/开始,以/结束, 作用于分隔符,表示正则表达式的开始与结束
//以[开始,以]结束,作用于字符集一个,比如[abc],在这个位置字符里面匹配到a或b或c都成立
//以^开始,以$结束 ,作用于字符串,可以单独使用 ^abc以 abc开头, abc$以abc结束
//以(开始,以)结束,作用于表达式,其中 | 类似于if里面的或意思 || 比如(a|b)表示ab任意匹配一个
//以{开始,以}结束,作用于限定符,比如a{1} a必须出现一次
/*限定符6种也叫重复出现次数:在他原来位置上出现次数 + * ? {n} {n,} {n,m}
* a+ 表示a这个字符至少出现一次或多次
* a* 表示a字符可以不出现,也可以出现一次或者多次
* a? 表示a字符,出现只能1次,或者不出现,也就是(0或1次)
*
* n是一个非负整数
* {n} 匹配确定的 n 次
* {n,} 至少匹配n 次, 或大于n的多次。等价于a*
* {n,m} 最少匹配 n 次且最多匹配 m 次(n<=m)
*/
/*元字符与几种反义
* \b 匹配单词边界 ,字与空格间的位置,不占用字符位置,如 "\ba\b" 识别is 两边是否为单词的边界
* \B 匹配不是单词开头或结束的位置
* \d 匹配纯数字
* \D 匹配任意非数字的字符
* \w 匹配字母,数字,下划线
* \W 匹配任意不是字母,数字,下划线 的字符
* \s 匹配空格
* \S 匹配任意不是空白符的字符
* [abc] 匹配包含括号内元素的字符
* [^abc] 匹配除了a或b或c以外的任意字符
* . 匹配除了换行符以外的任何字符 另外\n就是换行符
* \ 转义字符,比如字符串中有*号,和正则表达式冲突 需要 \* 转义 如:([^\["\‘]+?) 表示不能有单引双引号
* \1 如果前面表达式和 后面需要的一样 就用\1指定前面子匹配项 来代替后面的,另外 "\1" 引用第1对括号内匹配到的字符串,"\2" 引用第2对括号内匹配到的字符串……以此类推
* g: 全局匹配 i: 忽略大小写 m 多行查找 可以两个字母和在一起如:gi: 全局匹配 ,忽悠大小写
*/
/*分组语法:正则表达式里每个元括号()就是一组
* (exp) 匹配exp,并捕获文本到自动命名的组里
* (?<name>exp) 匹配exp,并捕获文本到名称为name的组里
* (?:exp) 匹配exp,不捕获匹配的文本
*
* (?=exp) 匹配exp前面的位置
* (?<=exp) 匹配exp后面的位置
* (?!exp) 匹配后面跟的不是exp的位置
* (?<!exp) 匹配前面不是exp的位置
*
* (?#comment)注释:这种类型的组不对正则表达式的处理产生任何影响,只是为了提供让人阅读注释
*/
原文:https://www.cnblogs.com/longxinyv/p/12053451.html