import requests
from bs4 import BeautifulSoup
# 获取新闻页面源码的函数
def getNews(url):
# 判断异常产生
try:
r = requests.get(url, timeout=30)
# 爬取出错的话抛出异常
r.raise_for_status()
# 返回页面源码
return r.text
except:
return "爬取页面出现错误,停止爬取"
def getContent(html, url):
soup = BeautifulSoup(html, "html.parser")
# 获取新闻页面标题
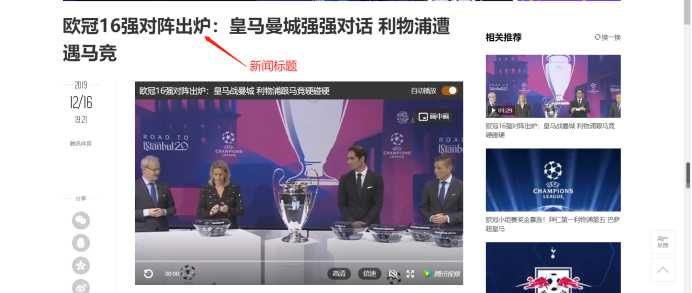
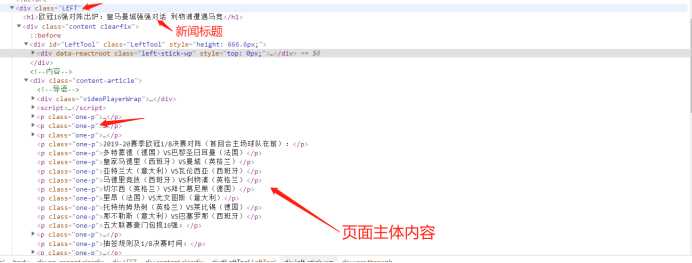
title = soup.select("div.LEFT > h1")
# 打印查看标题是否爬取
print(‘新闻标题:‘ + title[0].get_text())
# 获取新闻编辑作者
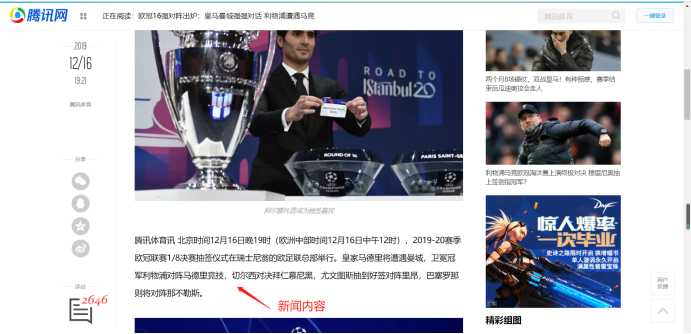
author = soup.select("div.content-article > p.one-p > strong")
print(‘编辑作者:‘ + author[1].get_text())
# 新闻正文
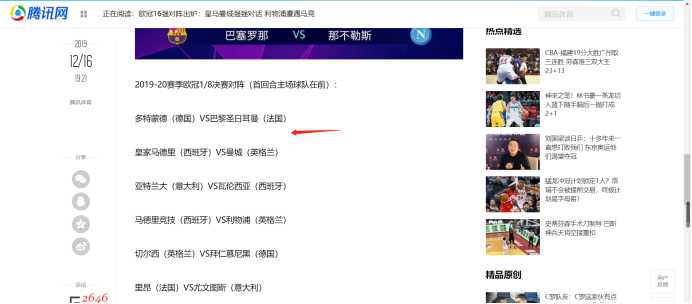
text = soup.select("div.content-article > p.one-p")
n=0
for p in text:
if n > 1:
print(p.get_text())
n = n + 1
# 写入文件
fo = open("text.txt", "w+", encoding=‘utf-8‘)
# 写入新闻标题
fo.writelines(title[0].get_text() + "\n")
# 写入新闻编辑作者
fo.writelines(author[1].get_text() + ‘\n‘)
# 用于计数行数
n=0
for p in text:
if n > 1:
fo.writelines(p.get_text() + "\n\n")
n = n + 1
# 关闭文件流
fo.close()
def main():
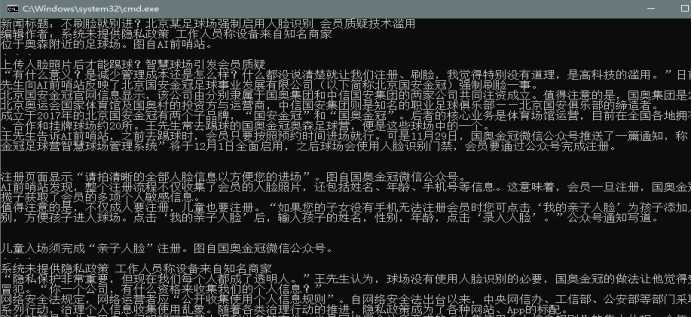
url = "https://new.qq.com/omn/20191215/20191215A0K94W00.html"
html = getNews(url),
# 执行爬取函数
getContent( html,url)
# 执行main函数
main()
import requests
from bs4 import BeautifulSoup
# 获取体育新闻并存储到文件中
def getNews(url):
# 爬取过程中可能会出现爬取失败的情况,一旦失败停止爬取
try:
r = requests.get(url)
r.raise_for_status()
html = r.text
except:
return "Error"
# 使用BeautifulSoup类解析网页源码
soup = BeautifulSoup(html, "html.parser")
# 获取新闻标题
title = soup.select("div.LEFT > h1")
# 打印新闻标题
print(title[0].get_text())
# 获取新闻主题内容
text = soup.select("div.content-article > p.one-p")
n = 0
for p in text:
if n > 1:
print(p.get_text())
n = n + 1
# 获取txt文件输出流对象
fo = open("text.txt", "w+", encoding=‘utf-8‘)
# 将新闻标题写入txt文件中
fo.writelines(title[0].get_text() + "\n")
n = 0
for p in text:
if n > 1:
# 将新闻内容按行写入文件
fo.writelines(p.get_text() + "\n\n")
n = n + 1
# 关闭文件输出流,从内存中存入到硬盘
fo.close()
# 爬取新闻的页面ur路径
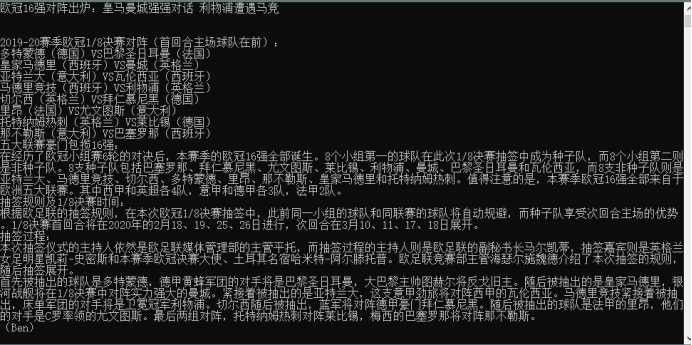
url = "https://new.qq.com/rain/a/SPO2019121602087000"
# 执行函数
getNews(url)
2.对本次程序设计任务完成的情况做一个简单的小结。