一、主题式网络爬虫设计方案(15分)
首先,对厦门人才网的数据进行爬取,其次利用find_all()遍历方法进行爬取数据并将数据存储在recruitList.xlse表中,最后对目标数据进行数据清洗和数据可视化。
主要技术难点在于岗位关联性不高,数据太少,网页不够完整等问题,从而很难对数据进行分析可视化。
https://www.xmrc.com.cn/net/info/Resultg.aspx?a=a&g=g&recordtype=1&searchtype=1&keyword=Python
&releasetime=365&worklengthflag=0&sortby=updatetime&ascdesc=Desc&PageIndex=1
2.Htmls页面解析



3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
节点查找方法与遍历方法使用find_all()遍历页面当中属性为“class=bg” 和 “data-selected”的tr标签
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集


2.对数据进行清洗和处理




3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化


6.附完整程序代码
import re import bs4 import numpy as np import pandas as pd import requests as req from bs4 import BeautifulSoup # 返回网页源码的函数 def getHTMLText(url): try: # 使用requests库爬取网页源码2 r = req.get( url, headers={‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36‘}) # 判断是否爬取过程中出现错误 r.raise_for_status() # 设置源码的编码格式 r.encoding = r.apparent_encoding # 返回源码 return r.text except: return "爬取失败" # 解析页面源码并组成集合返回爬取数据 def XiamiMusicList(html): List = [] # 使用bs4库中的BeautifulSoup类解析html文本 soup = BeautifulSoup(html, "html.parser") trs = soup.find_all("tr","bg") for i in trs: # 招聘岗位 a1 = i.find_all("a")[0].text.replace("\n", "") # 招聘链接 a1href = i.find_all("a")[0].attrs[‘href‘].replace("\n", "") # 唯一id recruit_id = i.find_all("a")[0].attrs[‘href‘].split( "=")[-1].replace("\n", "") # 公司名称 a2 = i.find_all("a")[1].text.replace("\n", "") # 公司地址 a3 = i.find_all("a")[2].text.replace("\n", "") # 薪资 a4 = i.find_all("a")[3].text.replace("\n", "") # 学历 a5 = i.find_all("a")[4].text.replace("\n", "") # 发布日期 a6 = i.find_all("a")[5].text.replace("\n", "") # 组装集合 temp = [recruit_id, a1, a2, a3, a4, a5, a6, a1href] List.append(temp) return List # 数据持久化 def weiteExcel(musicList, MusicListPath): # 将数据转化为DataFrame格式 df = pd.DataFrame(musicList, columns=[ "recruit_id", "Occupation", "company", "locationi", "salary", "Education", "createtime", "recruit_href"]) # 输出excel的对象 writer = pd.ExcelWriter(MusicListPath) # 将数据写入到excel表格中 df.to_excel(writer, sheet_name="recruitList") # 关闭输出流 writer.save() # 主函数 def main(): Path = "https://www.xmrc.com.cn/net/info/Resultg.aspx?a=a&g=g&recordtype=1&searchtype=1&keyword=" # 搜索关键词 keyword = "python" url = "&releasetime=365&worklengthflag=0&sortby=updatetime&ascdesc=Desc&PageIndex=" # 页数关键词// 修改此项值能获取指定页面数据 page = "1" html = getHTMLText(Path+keyword+url+page) # print(html) # 存放路径 recruitListPath = "recruitList.xlsx" # 获取爬取数组 List = XiamiMusicList(html) # 将数据保存至文件中 weiteExcel(List, recruitListPath) main()
#数据清洗与可视化
import requests as req from bs4 import BeautifulSoup import bs4 import numpy as np import pandas as pd import matplotlib.pyplot as plt import re import seaborn as sns
# 解决seaborn中文乱码问题 sns.set_style(‘whitegrid‘,{‘font.sans-serif‘:[‘simhei‘,‘Arial‘]})
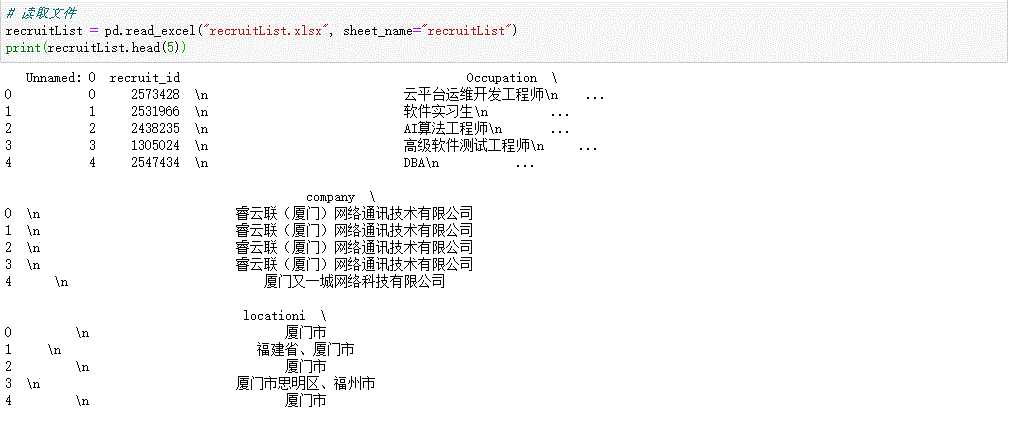
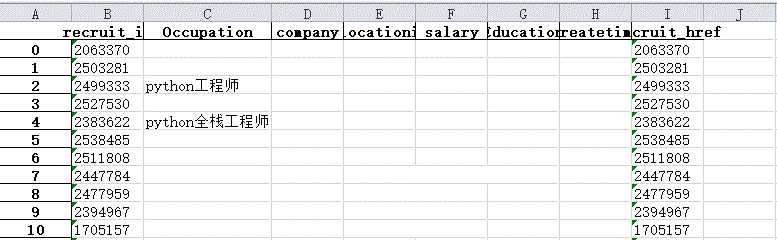
# 读取文件 recruitList = pd.read_excel("recruitList.xlsx", sheet_name="recruitList") print(recruitList.head(5))
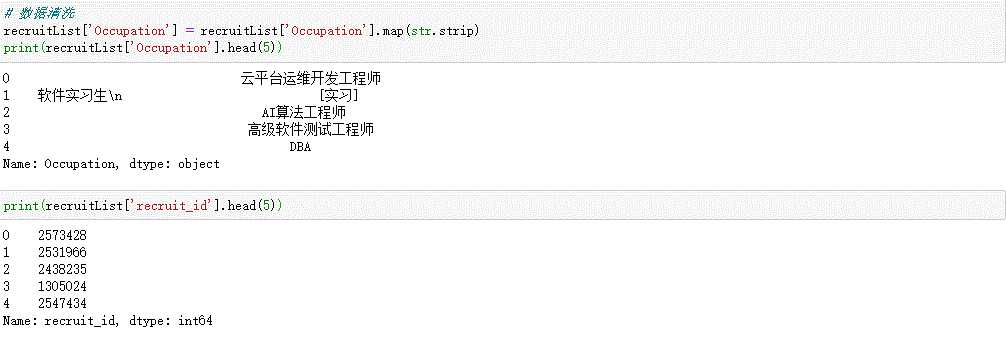
# 数据清洗 recruitList[‘Occupation‘] = recruitList[‘Occupation‘].map(str.strip) print(recruitList[‘Occupation‘].head(5))
print(recruitList[‘recruit_id‘].head(5))
# 数据清洗 recruitList[‘company‘] = recruitList[‘company‘].map(str.strip) print(recruitList[‘company‘].head(5)) recruitList[‘locationi‘] = recruitList[‘locationi‘].map(str.strip) print(recruitList[‘locationi‘].head(5))
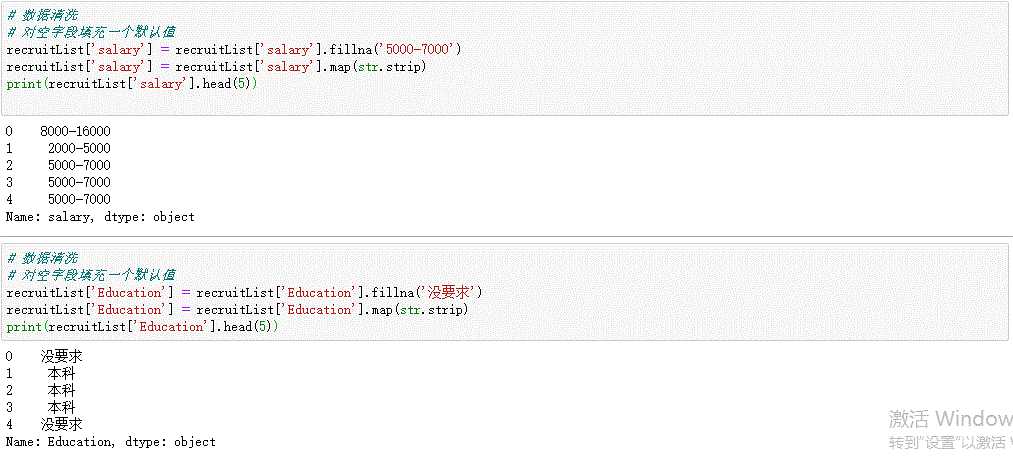
# 数据清洗 # 对空字段填充一个默认值 recruitList[‘salary‘] = recruitList[‘salary‘].fillna(‘5000-7000‘) recruitList[‘salary‘] = recruitList[‘salary‘].map(str.strip) print(recruitList[‘salary‘].head(5))
# 数据清洗 # 对空字段填充一个默认值 recruitList[‘Education‘] = recruitList[‘Education‘].fillna(‘没要求‘) recruitList[‘Education‘] = recruitList[‘Education‘].map(str.strip) print(recruitList[‘Education‘].head(5))
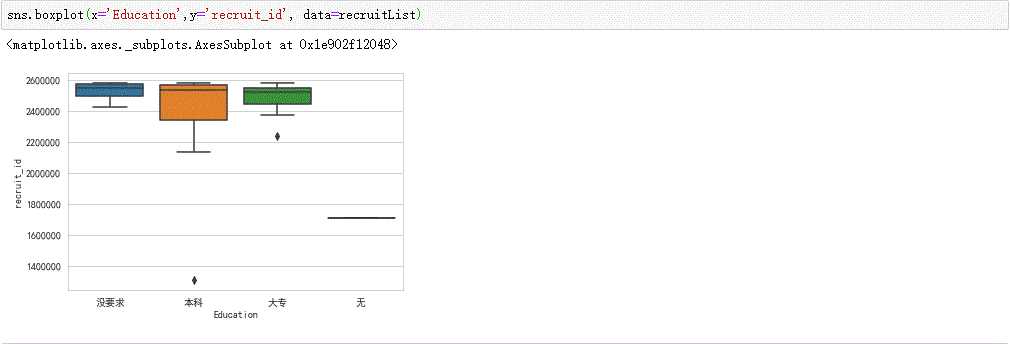
#学历要求可视化
sns.boxplot(x=‘Education‘,y=‘recruit_id‘, data=recruitList)
结论:(1)通过这次数据的分析与可视化可以很清晰的发现厦门人才网工作岗位学历要求,其中对于其他学历来说,本科学历的占比率会多一些。
(2)在分析的过程中由于厦门人才网里面爬取的数据比较少,关联性比较低,不容易从某个特定的职位进行数据的分析。
2.对本次程序设计任务完成的情况做一个简单的小结。
对于这次的网络爬虫,我选择了一个厦门人才网进行爬取,在爬取的过程中发现了很多问题,比如某个职位的招聘信息太少,无法对其进行数据可视化分析。但是通过爬取数据内容的分析,让我对厦门工作岗位也有了清晰大致的了解。最重要的是通过这次的学习让我对网络爬虫有了更深刻的理解,让我学习到之前没有接触过得知识点,提高了我的爬虫水平。
原文:https://www.cnblogs.com/ghtt123/p/12059681.html