Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
基于BeautifulSoup的链家网二手房信息爬取和分析
2.主题式网络爬虫爬取的内容与数据特征分析
利用requests和BeautifulSoup进行爬取链家网信息,爬取内容包括二手房的楼房名称、价格、地址、单价、房间样式、房间规模和楼层规模,同时利用split函数进行数据信息分割,获得自己想要的数据信息。其数据特征有以下几点:
(1)分析二手房名称,对其数据进行清洗,把相同数据删除。
(2)分析二手房价格,构建数据分析模型,观察模型图价格的分布情况。
(3)分析房间样式和楼层规模,并对其进行可视化。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)利用requests方法请求网页,并进行验证头部信息,尝试运行返回的get值,是200则继续下一步,否则检查程序并再次尝试。
(2)利用BeautifulSoup进行网页解析,同时利用其语法获取需要的数据信息。
(3)利用find_all方法获取ul标签下的li标签。
(4)利用循环实现翻页获取数据。
(5)利用split进行数据的分割,并获取想要的数据。
(6)利用DataFrame把数据写入特定位置,为后续数据分析和数据清洗做准备。
技术难点:
(1)在爬取数据的过程中,进行翻页爬取数据时应注意利用循环和注意代码对齐。
(2)要在爬取数据之前加入请求头部信息,相当于验证身份信息,否则会出现错误提示。
(3)注意要获取的数据在哪一个标签下,利用F12进行数据检查和分析所要爬取的数据特征。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
打开链家网页面按F12,点击Elements,观察网页的HTML代码,可以发现所要去获取的数据都在ul标签下的li标签,同时一个房源信息对应着一个li标签。由于网页是静态的,我通过检索发现要获取的数据都可以在网页源代码中找到,因此可以利用BeautifulSoup中的find、find_all方法获取数据。
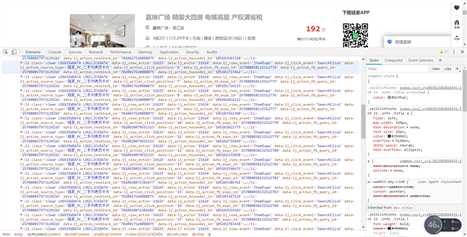
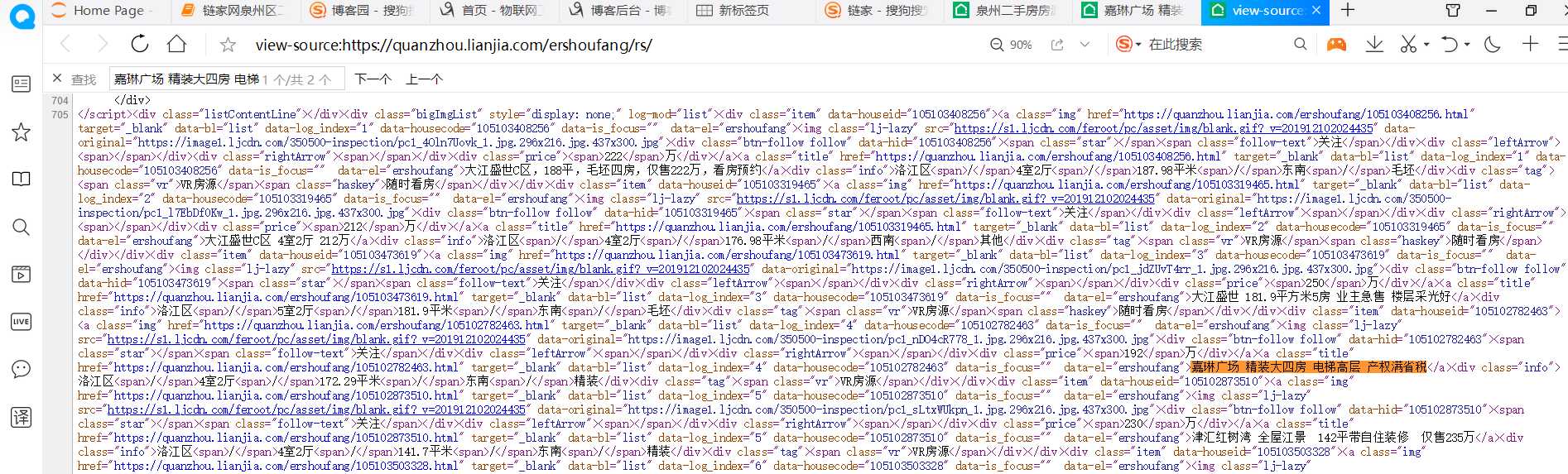
2.Htmls页面解析
利用BeautifulSoup语法解析网站页面,并解析要获取的内容,通过解析可以发现我们想要获取的楼房名称是在li标签下,div class=”info clear”下div class=”title”下的a标签中。同理其他信息通过观察下图可得到。
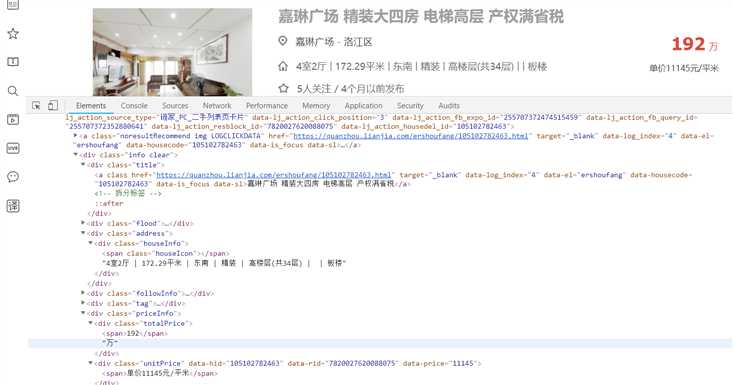
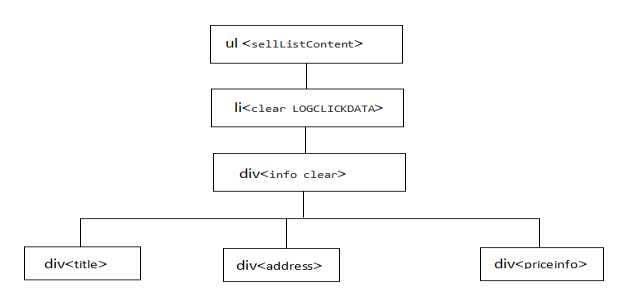
3.节点(标签)查找方法与遍历方法
节点的查找利用BeautifulSoup中的find、find_all方法,观察页面代码中的标签上下节点,适当使用其方法。遍历方法利用for循环实现对ul标签下li标签的全部遍历,同时实现其翻页遍历的操作。
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
#!/usr/bin/python3 #_*_coding:utf-8 _*_ #@Author:lixiaohong #@title:爬取链家网二手房信息 #导入所需要的包 import requests from bs4 import BeautifulSoup import pandas as pd from pandas import DataFrame import os # 定义翻页的数量 page =100 def detail_xinx(): # 循环实现翻页 for i in range(page): url = ‘https://quanzhou.lianjia.com/ershoufang/pg‘+str(i) try: #异常处理 r=requests.get(url) #如果状态不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding=r.apparent_encoding except: print("产生异常") # 验证请求头部信息 headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400‘, ‘Host‘: ‘quanzhou.lianjia.com‘, ‘Referer‘: ‘https: // quanzhou.lianjia.com /?utm_source = sogou & utm_medium = pinzhuan & utm_term = biaoti & utm_content = biaoti & utm_campaign = sousuo‘ } #定义数据文件名称及写入位置 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), ‘lianjia_data.xlsx‘) resp = requests.get(url,headers=headers) #print(resp.text) #网页内容 文本形式 #print(resp.content.decode(‘utf-8‘)) #网页 内容 二进制形式 html = resp.text # 利用BeautifulSoup语法解析网页 soup = BeautifulSoup(html,‘html.parser‘) #print(soup) # 获取ul标签下所有的li标签 infos = soup.find(‘ul‘,{‘class‘:‘sellListContent‘}).find_all(‘li‘) # print(infos) # 对li标签进行遍历,获取每一个li标签下的所需要数据 for info in infos: #获取楼房的标题名称 name = info.find(‘div‘,{‘class‘:‘title‘}).find(‘a‘).get_text() print(name) #获取楼房的价格(套/万元) price = info.find(‘div‘,{‘class‘:‘priceInfo‘}).find(‘div‘,{‘class‘:‘totalPrice‘}).find(‘span‘).get_text() print(price) #获取楼房单价(m2/元) totleprice =info.find(‘div‘,{‘class‘:‘priceInfo‘}).find(‘div‘,{‘class‘:‘unitPrice‘}).get_text() #print(totleprice) # 对输出的楼房单价进行分割 只获取其单价 totle = totleprice.split(r‘单价‘) #print(totle) date0=totle[1] #print(date0) date1 =date0.split(r‘元‘) #print(date1) date2 =date1[0] print(date2) #获取楼房的地址信息 address = info.find(‘div‘,{‘class‘:‘flood‘}).find(‘a‘).get_text() print(address) #获取房间样式信息 new = info.find(‘div‘,{‘class‘:‘houseInfo‘}).get_text() #print(new) list = new.split(r‘|‘) area =list[0] #获取房间规模信息(m2) print(area) area1=list[1] # print(area1) area2=area1.split(r‘平‘) # print(area2) area3 =area2[0] print(area3) area2=list[4] # print(area2) #获取楼层规模信息 lou=area2.split(r‘(‘) # print(lou) lou1=lou[0] print(lou1) #定义一个字典用于存放创建列的名称 infos={} # 定义表格中列的名称 infos[‘楼房名称‘] = name infos[‘价格‘] = price infos[‘单价‘] = date2 infos[‘地址‘] = address infos[‘房间样式‘] = area infos[‘房间规模‘] = area3 infos[‘楼层规模‘] = lou1 df = DataFrame(infos, index=[0]) if os.path.exists(file_path): # 字符编码采用utf-8 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") else: df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") def main(): # 调用函数 detail_xinx() if __name__ == ‘__main__‘:#程序执行时调用主程序main() main()
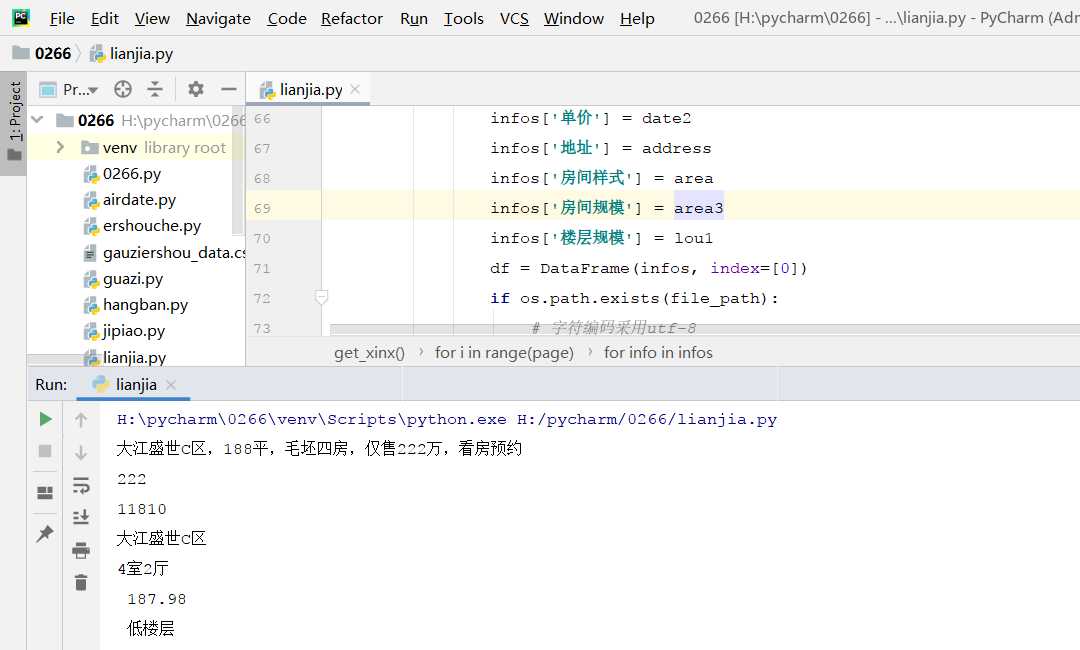
2.对数据进行清洗和处理
#利用DataFrame进行数据加载,并查看前5行数据 import pandas as pd df = pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) df.name="链家网泉州二手房信息" df.head()
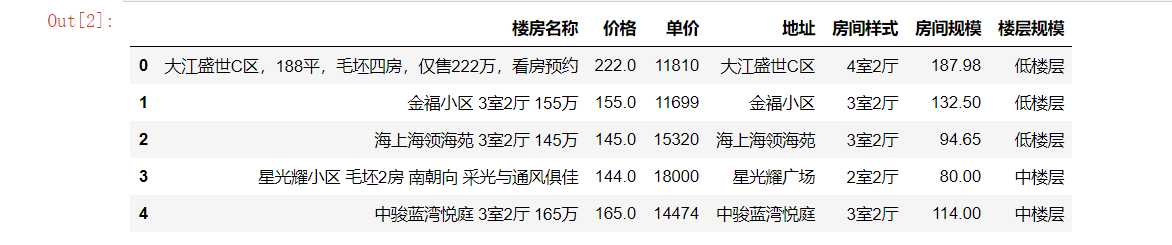
#删除无效列 df.drop(‘楼层规模‘,axis=1,inplace=True) df.head()
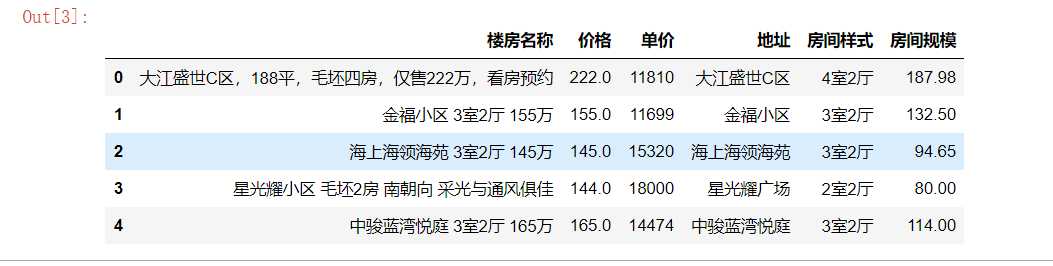
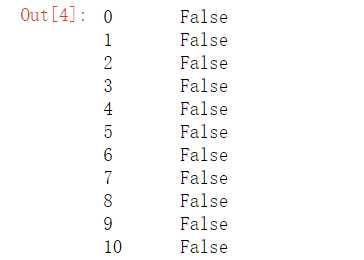
#对数据进行重复值处理 df.duplicated()
#把重复楼房信息删除 df =df.drop_duplicates() df.head()
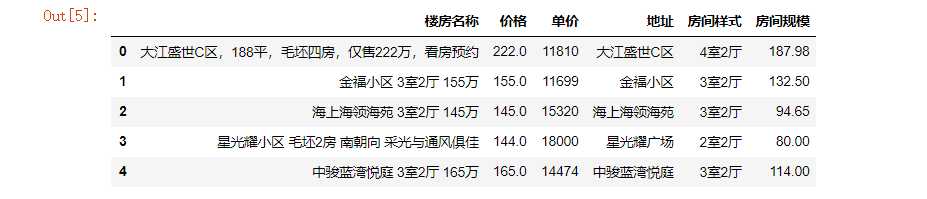
#对数据进行空值处理 df[‘价格‘].isnull().value_counts()

#观察数据是否需要异常值处理 df.describe()
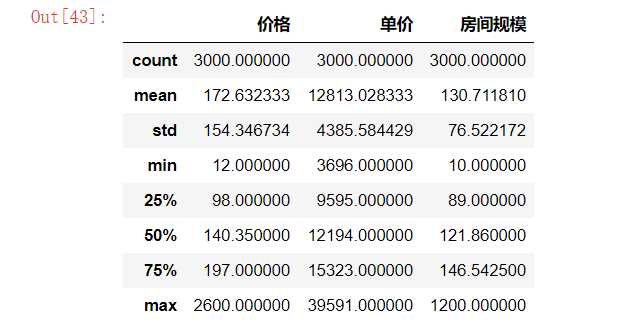
房间规模中1200有可能是一个异常值,将其用平均值表示
#把房间规模中的异常值用平均值表示 df.replace([1200.000000],df[‘房间规模‘].mean())
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
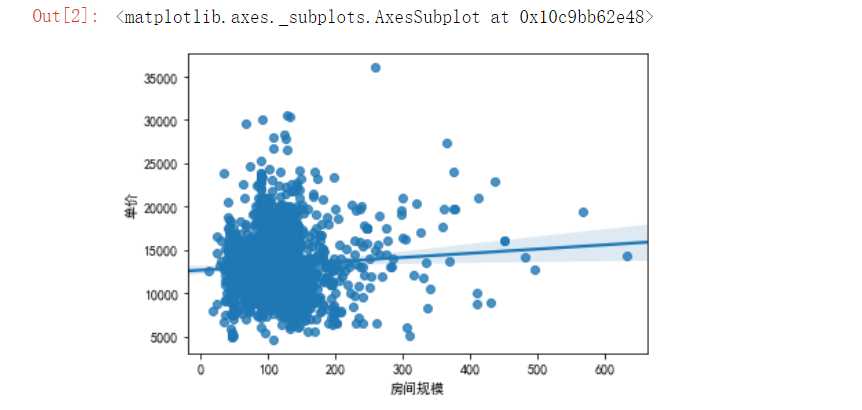
#利用regplot方法绘制回归图,并构建数据分析模型 #利用数据分析模型查看房间规模和单价之间的分布情况 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘] = False sns.regplot( df.房间规模,df.单价)
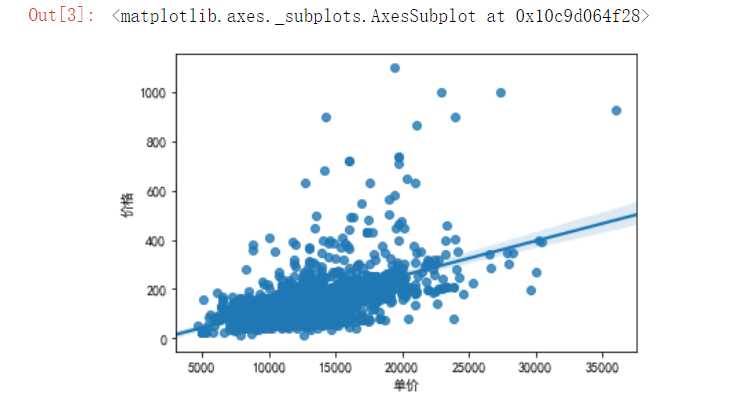
#利用数据分析模型查看价格和单价之间的分布情况 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘] = False sns.regplot( df.单价,df.价格)
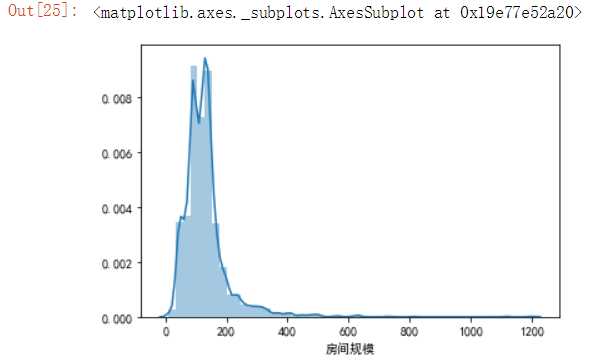
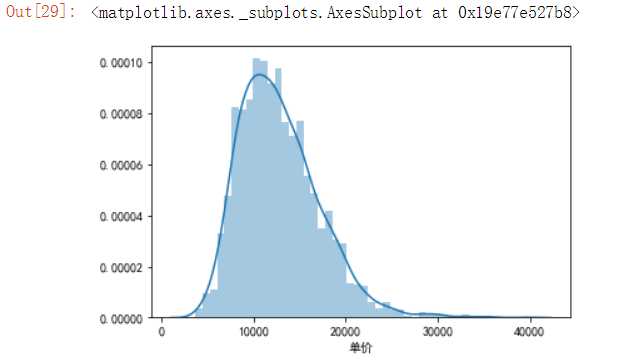
使用直方图查看爬取的链家网泉州二手楼房的房间规模、单价、价格的分布情况。
#查看爬取楼房信息中房间规模的分布 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) sns.distplot(df[‘房间规模‘])
#查看爬取楼房信息中单价的分布 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) sns.distplot(df[‘单价‘])
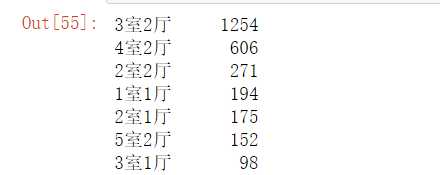
#统计数据中房间样式的分布 import pandas as pd df = pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) df[‘房间样式‘].value_counts()
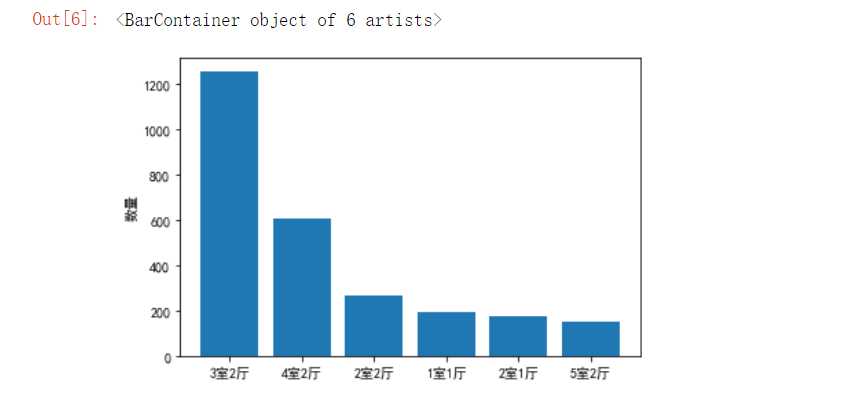
#根据对房间样式统计结果,利用柱形图进行可视化 import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.rcParams[‘axes.unicode_minus‘] = False plt.ylabel(‘数量‘) plt.bar([‘3室2厅‘,‘4室2厅‘,‘2室2厅‘,‘1室1厅‘,‘2室1厅‘,‘5室2厅‘],[1254,606,271,194,175,152])
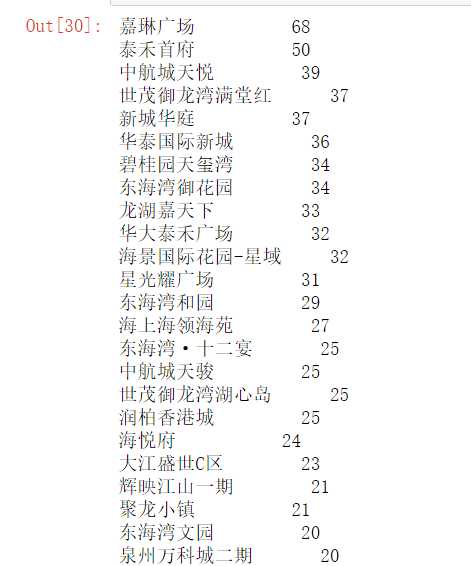
#统计房源数量情况 import pandas as pd df = pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) df[‘地址‘].value_counts()
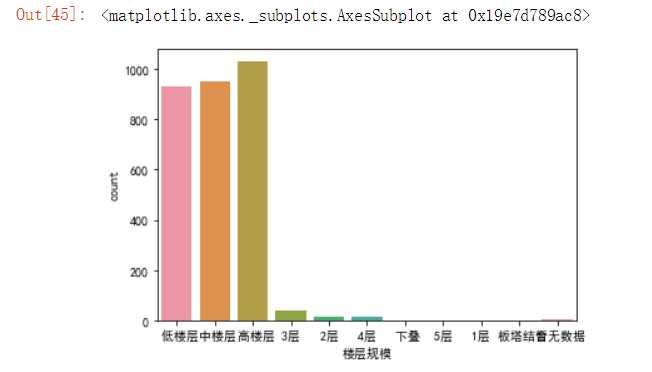
#利用直方图查看楼层规模的分布并可视化 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) sns.countplot(df[‘楼层规模‘])
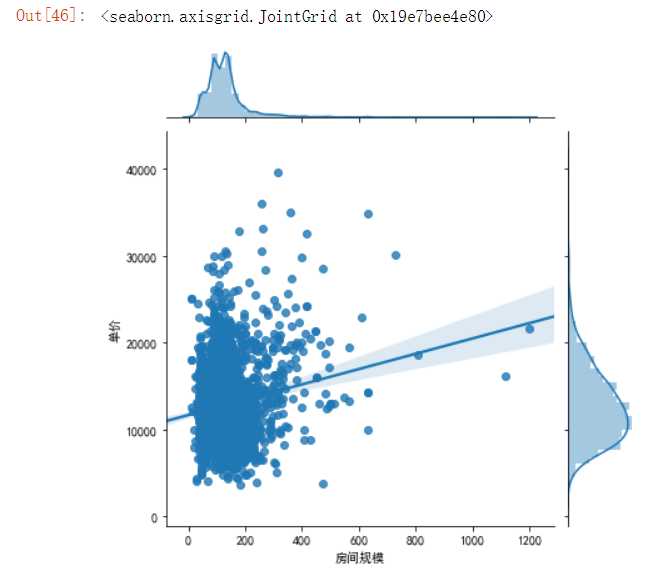
#利用散点图查看房间规模和单价之间的关系 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df=pd.read_excel(‘H:\pycharm\lianjia/lianjia_data.xlsx‘) sns.jointplot(x="房间规模",y="单价",data=df,kind=‘reg‘)
5.数据持久化
将数据存储起来,方便数据分析
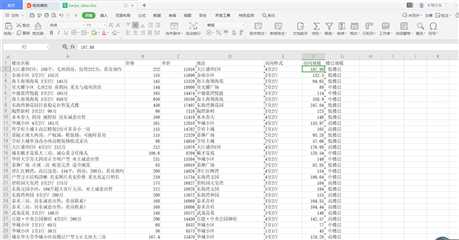
6.附完整程序代码
#!/usr/bin/python3 #_*_coding:utf-8 _*_ #@Author:lixiaohong #@title:爬取链家网二手房信息 #导入所需要的包 import requests from bs4 import BeautifulSoup import pandas as pd from pandas import DataFrame import os # 定义翻页的数量 page =100 def detail_xinx(): # 循环实现翻页 for i in range(page): url = ‘https://quanzhou.lianjia.com/ershoufang/pg‘+str(i) try: #异常处理 r=requests.get(url) #如果状态不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding=r.apparent_encoding except: print("产生异常") # 验证请求头部信息 headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400‘, ‘Host‘: ‘quanzhou.lianjia.com‘, ‘Referer‘: ‘https: // quanzhou.lianjia.com /?utm_source = sogou & utm_medium = pinzhuan & utm_term = biaoti & utm_content = biaoti & utm_campaign = sousuo‘ } #定义数据文件名称及写入位置 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), ‘lianjia_data.xlsx‘) resp = requests.get(url,headers=headers) #print(resp.text) #网页内容 文本形式 #print(resp.content.decode(‘utf-8‘)) #网页 内容 二进制形式 html = resp.text # 利用BeautifulSoup语法解析网页 soup = BeautifulSoup(html,‘html.parser‘) #print(soup) # 获取ul标签下所有的li标签 infos = soup.find(‘ul‘,{‘class‘:‘sellListContent‘}).find_all(‘li‘) # print(infos) # 对li标签进行遍历,获取每一个li标签下的所需要数据 for info in infos: #获取楼房的标题名称 name = info.find(‘div‘,{‘class‘:‘title‘}).find(‘a‘).get_text() print(name) #获取楼房的价格(套/万元) price = info.find(‘div‘,{‘class‘:‘priceInfo‘}).find(‘div‘,{‘class‘:‘totalPrice‘}).find(‘span‘).get_text() print(price) #获取楼房单价(m2/元) totleprice =info.find(‘div‘,{‘class‘:‘priceInfo‘}).find(‘div‘,{‘class‘:‘unitPrice‘}).get_text() #print(totleprice) # 对输出的楼房单价进行分割 只获取其单价 totle = totleprice.split(r‘单价‘) #print(totle) date0=totle[1] #print(date0) date1 =date0.split(r‘元‘) #print(date1) date2 =date1[0] print(date2) #获取楼房的地址信息 address = info.find(‘div‘,{‘class‘:‘flood‘}).find(‘a‘).get_text() print(address) #获取房间样式信息 new = info.find(‘div‘,{‘class‘:‘houseInfo‘}).get_text() #print(new) list = new.split(r‘|‘) area =list[0] #获取房间规模信息(m2) print(area) area1=list[1] # print(area1) area2=area1.split(r‘平‘) # print(area2) area3 =area2[0] print(area3) area2=list[4] # print(area2) #获取楼层规模信息 lou=area2.split(r‘(‘) # print(lou) lou1=lou[0] print(lou1) #定义一个字典用于存放创建列的名称 infos={} # 定义表格中列的名称 infos[‘楼房名称‘] = name infos[‘价格‘] = price infos[‘单价‘] = date2 infos[‘地址‘] = address infos[‘房间样式‘] = area infos[‘房间规模‘] = area3 infos[‘楼层规模‘] = lou1 df = DataFrame(infos, index=[0]) if os.path.exists(file_path): # 字符编码采用utf-8 df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") else: df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig") def main(): # 调用函数 detail_xinx() if __name__ == ‘__main__‘:#程序执行时调用主程序main() main()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)链家网泉州地区的二手楼房单价大概集中在9000元/m2—12000元/m2。
(2)链家网泉州地区的二手楼房的房间规模大概分布在110平方米左右。
(3)链家网泉州地区的二手楼房一套价格大概在150万左右。
(4)泉州地区的二手楼房的房间样式主要以3室2厅、4室2厅、2室2厅三种类型为主。
(5)泉州地区的嘉琳广场 、泰禾首府、中航城天悦、新城华庭房源数量较其他地方多。
2.对本次程序设计任务完成的情况做一个简单的小结。
经过这段时间对爬虫知识的学习,我对爬虫所使用的requests库和BeautifulSoup库有初步的认识,对爬虫的流程也有初步的了解。希望自己能坚持学习,不断进步。
原文:https://www.cnblogs.com/lixiaohong/p/12002029.html