爬取网站:https://doupocangqiong1.com/148/1.html
1.首先我看查看网页源代码,发现里面并没有小说内容,只有标题

2.然后我按f12,点network进行查看 ,在图下·找到了里面的内容,这个就是Ajax来加载显示的
3.刷新看看参数,每变一页就在原来的数字上+1,这样我就找到了翻页的办法
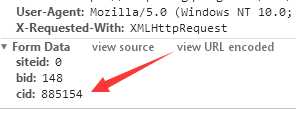
4.下面我就直接按照分析析代码
import requests
from lxml import etree
import os
import re
def bc_url(tltle,req1):
# 保存小说
filename=‘D:/小说/‘
if not os.path.exists(filename):
os.mkdir(filename)
with open(filename+tltle+".txt",‘a‘,encoding="UTF-8")as f:
f.write(req1)
f.close()
def get_url():
url1=‘https://doupocangqiong1.com/novelsearch/chapter/transcode.html‘
# 构建翻页请求
for i in range(1,883):
url=‘https://doupocangqiong1.com/148/‘+str(i)+‘.html‘
headers={
‘Cookie‘: ‘__guid=99673995.150984782037069900.1576402368997.2383; Hm_lvt_e331ad8aeb2484e93d26fbc8a8f7c7e9=1576402370; Hm_lpvt_e331ad8aeb2484e93d26fbc8a8f7c7e9=1576402495; monitor_count=7‘,
‘Host‘: ‘doupocangqiong1.com‘,
‘Origin‘: ‘https://doupocangqiong1.com‘,
‘Referer‘: ‘https://doupocangqiong1.com/148/4.html‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘,
}
data={
‘siteid‘: ‘0‘,
‘bid‘: ‘148‘,
‘cid‘: str(885153+i),
}
try:
req=requests.get(url)
req.encoding=req.apparent_encoding
html=etree.HTML(req.text)
title=html.xpath(‘//div[@class="title"]/h1/a/@title‘)[0]
title=re.sub(r‘[* 《》?!@,.?。,]‘,‘‘,title)#去除标题里面的特殊字符
req1=requests.post(url1,data=data,headers=headers).json()[‘info‘]
req1=re.sub(‘<br>‘,‘‘,req1)
print(‘正在爬取‘+title)
except:
print(‘请求失败‘)
bc_url(title,req1)
if __name__ == ‘__main__‘:
get_url()
代码仅供参考,有什么建议的评论区留言
原文:https://www.cnblogs.com/anpei/p/12067841.html