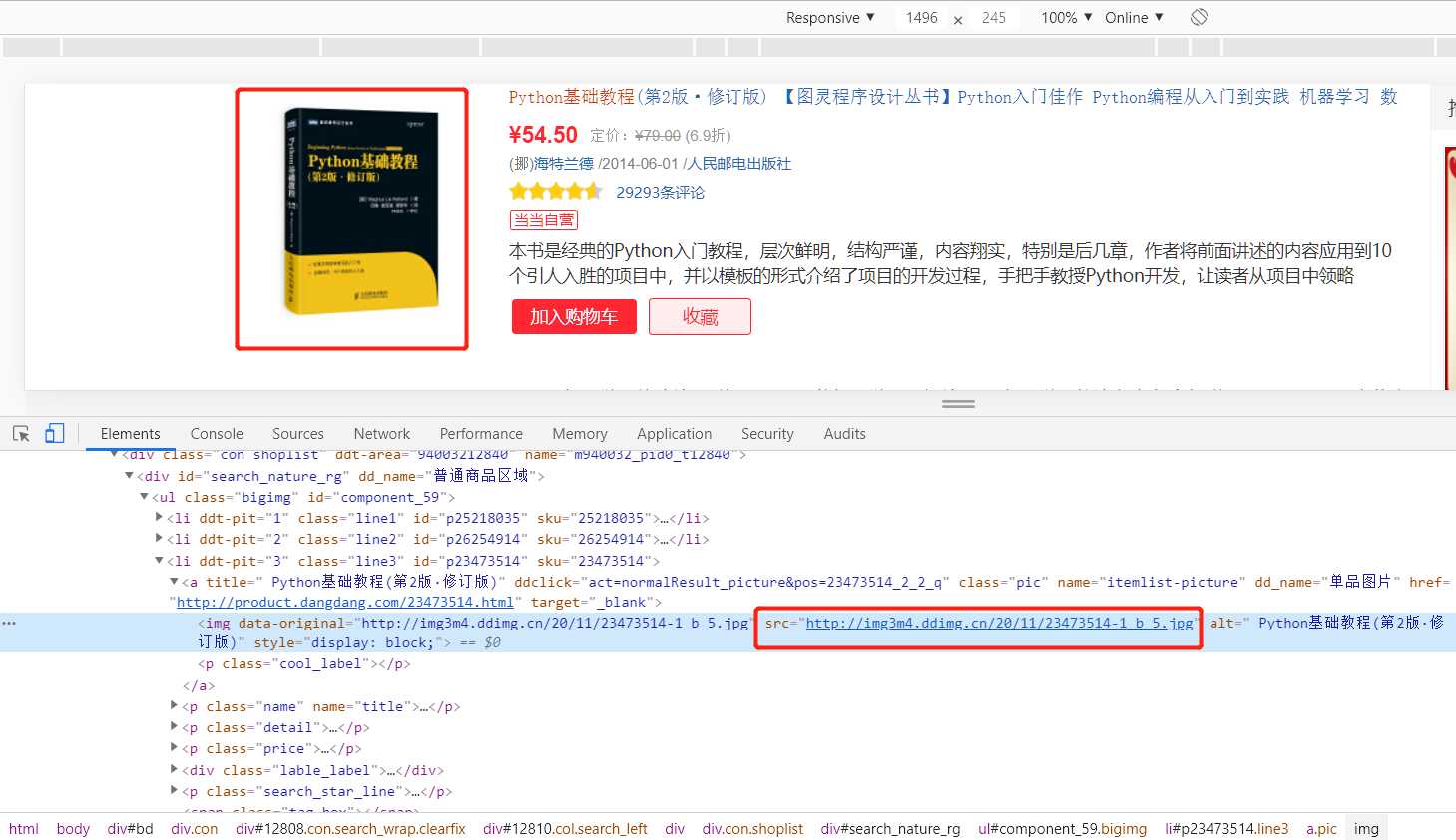
1.分析网页代码,获取图片下载连接:http://img3m4.ddimg.cn/20/11/23473514-1_b_5.jpg
2. python实现代码

1 import os 2 import re 3 import requests 4 import time 5 6 # 图片来源url 7 url=‘http://search.dangdang.com/?key=python&act=input‘ 8 9 # 构建请求头 10 headers = { 11 ‘User-Agent‘:‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Mobile Safari/537.36‘ 12 } 13 14 # 获取网页HTML代码 15 response = requests.get(url=url,headers=headers) 16 html = response.text 17 # print(html) 18 19 # 抓取图片名称 20 pic_name = re.findall(‘<a title=" (.*?)" ddclick‘,html) 21 # print(pic_name) 22 23 # 抓取图片url 24 pic_url = re.findall("<img src=‘(.*?)‘ alt",html) 25 pic_url2 = re.findall("<img data-original=‘(.*?)‘ src",html) 26 pic_url.extend(pic_url2) # 把两个list合并起来 27 28 # 创建文件夹 29 base_path = os.getcwd()#获取当前文件的绝对路劲 30 file_name = r‘爬图片‘#存放图片的文件夹名称 31 path = os.path.join(base_path,file_name) 32 if os.path.exists(path):#判断文件夹是否存在,不存在则创建一个名为file_name的文件夹 33 pass 34 else: 35 os.mkdir(path) 36 37 # 把图片保存起来 38 for i in range(len(pic_url)): 39 rsp = requests.get(pic_url[i]) 40 41 # 创建图片名称 42 img = pic_name[i]+‘.jpg‘ 43 img_name = os.path.join(path,img) 44 45 with open(img_name,‘wb‘)as f: 46 f.write(rsp.content) 47 time.sleep(1) 48 print("正在下载第{}张图片".format(i))
原文:https://www.cnblogs.com/qihuang94/p/12067722.html
