一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
新浪网新闻汽车栏目
2.主题式网络爬虫爬取的内容与数据特征分析
新浪网新闻汽车栏目爬虫+文本分析(结巴+词云)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案主要依靠BeautifulSoup库对新浪网访问并采集,最后以txt格式将数据保存在本地。
技术难点主要包括对页面的分析、对数据的采集和对数据的持久化操作。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
打开新浪网页,通过右击鼠-标查看网页源代码,找到对应要爬取的信息
https://auto.sina.com.cn/包含了汽车的车型、报价、新车、导购等信息。




 2.Htmls页面解析
2.Htmls页面解析





 三、网络爬虫程序设计(60分)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图
车型
1.数据爬取与采集。

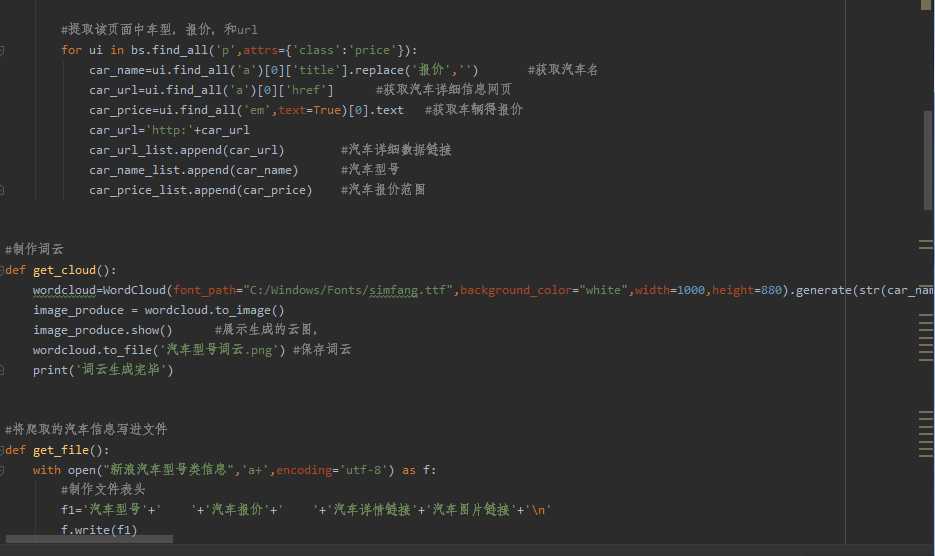
2.对数据进行清洗和处理



车型,3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对主体数据的提取分析,可以清楚地知道车型价位,一目了然。
2.对本次程序设计任务完成的情况做一个简单的小结。
经过这次的学习与作业实践,学到了很多爬虫的知识,不过还是远远不够的。
发现数据可视化和数据清洗真的很重要,对python的兴趣更加浓厚了。
原文:https://www.cnblogs.com/emptycity6/p/12070820.html