Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
天气后报数据的爬取与分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:爬取永春县近一个月来的天气信息
数据特征分析:分析永春县近一个月来的天气状况
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
1.通过开发者工具对查看所要爬取的页面的源码进行分析
2.利用python对页面进行信息爬取
3.进行数据分析
4.得出结论
技术难点:通过源码标签的分析提取出自己需要的数据
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征

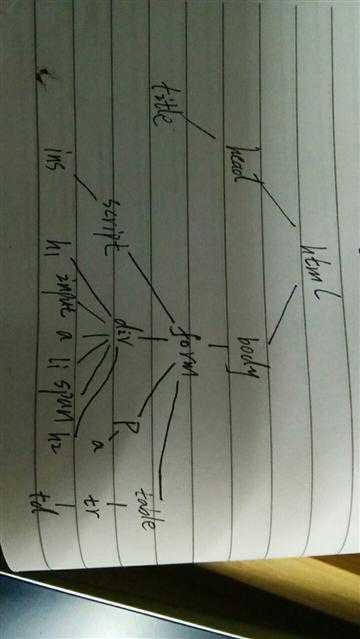
2.Htmls页面解析
具体的天气信息包含在td标签里,td标签包含在tr标签里,所有的tr标签又都包含在table标签里
3.节点(标签)查找方法与遍历方法
查找方法:
遍历方法:下行遍历
树结构:
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
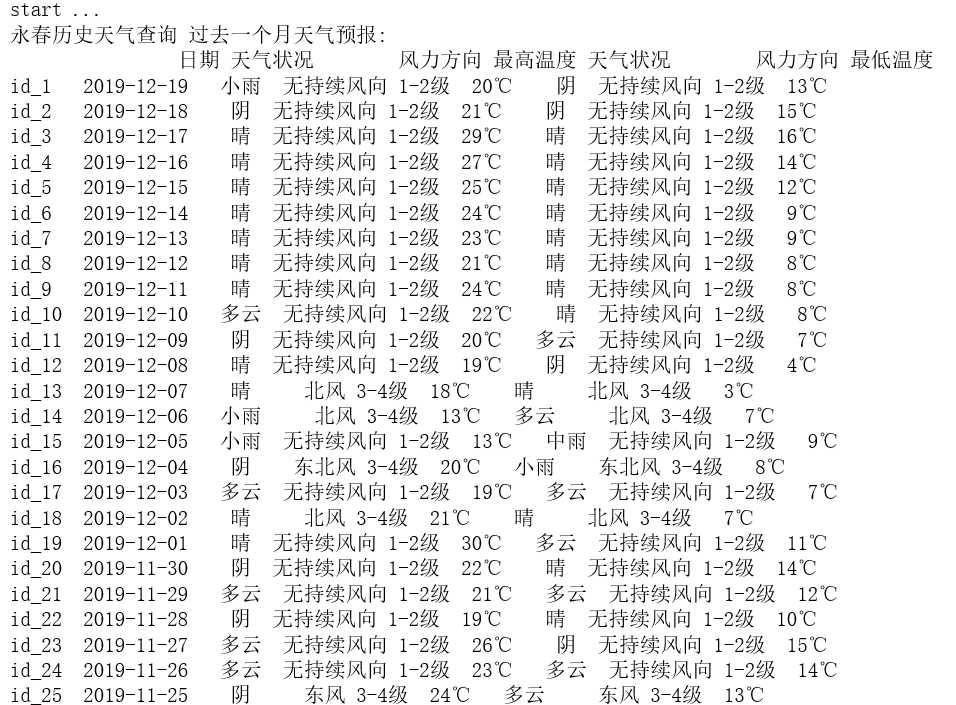
1.数据爬取与采集
import requests, time, re, os from bs4 import BeautifulSoup import numpy as np import pandas as pd class TianQiHouBao(): def __init__(self, ): self.url_base = "http://www.tianqihoubao.com/weather/top/yongchun.html" #页面地址 self.dir_path = "tianqihoubao.txt" self.headers={‘User-Agent‘:‘self-defind-user-agent‘,‘Cookie‘:‘name=self-define-cookies-in header‘}#修改请求头 self.cnt=0#计数器 def download_pages(self): response = requests.get(self.url_base.format(id), headers=self.headers)#使用get方法爬取网页 response.encoding = ‘gb2312‘#修改编码方式 soup = BeautifulSoup(response.text, "html.parser")#把网页解析为BeautifulSoup对象 self.content = soup.find("div", id="content")#使用find()方法提取首个<div>元素,并放到变量self.content里 def get_data(self):#数据的提取 self.title = self.content.find(‘h1‘).text table = self.content.find("table", class_="b") self.data_list = [] for tr in table.find_all("tr")[2:]:#遍历 self.cnt += 1#遍历一次计数器加1 tds = tr.find_all("td") self.data_list.append({ ‘City‘: tds[0].text.strip(), ‘Date‘: tds[1].text.strip(), ‘Day‘: {‘Weather_condition‘:tds[2].text.strip(), ‘Wind_direction‘:tds[3].text.strip(), ‘Max_temperature‘:tds[4].text.strip()}, ‘Night‘: {‘Weather_condition‘:tds[5].text.strip(), ‘Wind_direction‘:tds[6].text.strip(), ‘Min_temperature‘:tds[7].text.strip()}, })#提取标签内的内容 # print(self.title) # print(self.data_list) def output(self): #数据的输出 data = [] for dict in self.data_list: data.append([re.sub(u‘\\(.*?\\)‘,‘‘,dict[‘Date‘]), dict[‘Day‘][‘Weather_condition‘], dict[‘Day‘][‘Wind_direction‘], dict[‘Day‘][‘Max_temperature‘], dict[‘Night‘][‘Weather_condition‘], dict[‘Night‘][‘Wind_direction‘], dict[‘Night‘][‘Min_temperature‘] ]) df = pd.DataFrame( data=np.array(data), columns=[‘日期‘,‘天气状况‘, ‘风力方向‘, ‘最高温度‘, ‘天气状况‘, ‘风力方向‘, ‘最低温度‘], index=[f"id_{i+1}" for i in range(len(data))], ) df.to_excel(‘{}.xls‘.format(self.title), na_rep=True)#把信息存储到excel中 print("{}:\n {}\n".format(self.title, df.to_string())) def main(self):#主函数 print("start ...") self.download_pages() self.get_data() self.output() print("*********") print("Total:{}".format(self.cnt)) print("End Project!!!") if __name__=="__main__": TianQiHouBao().main()
输出结果:
2.对数据进行清洗和处理
1.导入数据集
import pandas as pd titanic=pd.DataFrame(pd.read_excel(‘永春历史天气查询 过去一个月天气预报.xls‘))#导入数据集 titanic
输出结果:

2.删除无效列:
import pandas as pd titanic.drop(‘Unnamed: 0‘,axis=1,inplace=True) #删除列Unnamed:0 titanic.head()
输出结果:
3.重复值处理
titanic.duplicated()#重复值处理
输出结果:

4.后面好像也没有什么空值、空格值跟异常值需要处理
3.文本分析(可选):jieba分词、wordcloud可视化
无
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
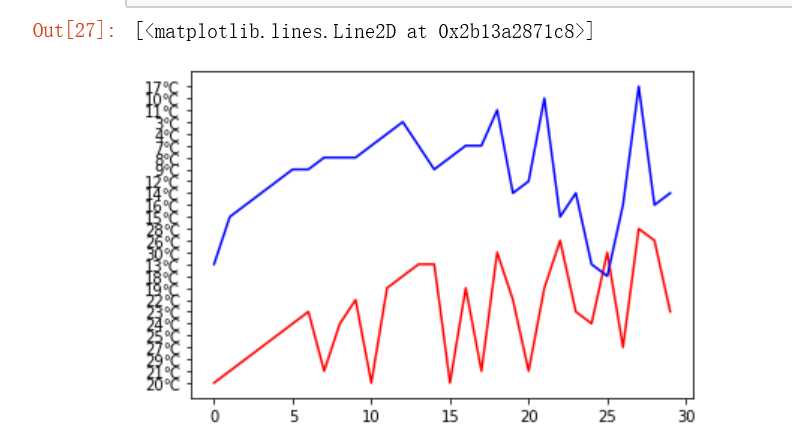
数据分析:可以直观的看出近一个月以来每天最高温度与最低温度的差值,最近一个月达到的最低温度为3摄氏度,最高达到了30摄氏度
数据可视化:
from matplotlib import pyplot as plt plt.plot(titanic.最高温度,‘r‘) plt.plot(titanic.最低温度,‘b‘)
输出结果:
5.数据持久化

6.附完整程序代码
import requests, time, re, os from bs4 import BeautifulSoup import numpy as np import pandas as pd class TianQiHouBao(): def __init__(self, ): self.url_base = "http://www.tianqihoubao.com/weather/top/yongchun.html" #页面地址 self.dir_path = "tianqihoubao.txt" self.headers={‘User-Agent‘:‘self-defind-user-agent‘,‘Cookie‘:‘name=self-define-cookies-in header‘}#修改请求头 self.cnt=0#计数器 def download_pages(self): response = requests.get(self.url_base.format(id), headers=self.headers)#使用get方法爬取网页 response.encoding = ‘gb2312‘#修改编码方式 soup = BeautifulSoup(response.text, "html.parser")#把网页解析为BeautifulSoup对象 self.content = soup.find("div", id="content")#使用find()方法提取首个<div>元素,并放到变量self.content里 def get_data(self):#数据的提取 self.title = self.content.find(‘h1‘).text table = self.content.find("table", class_="b") self.data_list = [] for tr in table.find_all("tr")[2:]:#遍历 self.cnt += 1#遍历一次计数器加1 tds = tr.find_all("td") self.data_list.append({ ‘City‘: tds[0].text.strip(), ‘Date‘: tds[1].text.strip(), ‘Day‘: {‘Weather_condition‘:tds[2].text.strip(), ‘Wind_direction‘:tds[3].text.strip(), ‘Max_temperature‘:tds[4].text.strip()}, ‘Night‘: {‘Weather_condition‘:tds[5].text.strip(), ‘Wind_direction‘:tds[6].text.strip(), ‘Min_temperature‘:tds[7].text.strip()}, })#提取标签内的内容 # print(self.title) # print(self.data_list) def output(self): #数据的输出 data = [] for dict in self.data_list: data.append([re.sub(u‘\\(.*?\\)‘,‘‘,dict[‘Date‘]), dict[‘Day‘][‘Weather_condition‘], dict[‘Day‘][‘Wind_direction‘], dict[‘Day‘][‘Max_temperature‘], dict[‘Night‘][‘Weather_condition‘], dict[‘Night‘][‘Wind_direction‘], dict[‘Night‘][‘Min_temperature‘] ]) df = pd.DataFrame( data=np.array(data), columns=[‘日期‘,‘天气状况‘, ‘风力方向‘, ‘最高温度‘, ‘天气状况‘, ‘风力方向‘, ‘最低温度‘], index=[f"id_{i+1}" for i in range(len(data))], ) df.to_excel(‘{}.xls‘.format(self.title), na_rep=True)#把信息存储到excel中 print("{}:\n {}\n".format(self.title, df.to_string())) def main(self):#主函数 print("start ...") self.download_pages() self.get_data() self.output() print("*********") print("Total:{}".format(self.cnt)) print("End Project!!!") if __name__=="__main__": TianQiHouBao().main() import pandas as pd titanic=pd.DataFrame(pd.read_excel(‘永春历史天气查询 过去一个月天气预报.xls‘))#导入数据集 titanic import pandas as pd titanic.drop(‘Unnamed: 0‘,axis=1,inplace=True) #删除列Unnamed:0 titanic.head() #数据可视化 from matplotlib import pyplot as plt plt.plot(titanic.最高温度,‘r‘) plt.plot(titanic.最低温度,‘b‘)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对数据的分析,可以清晰的知道近一个月以来永春县的最高温度为30°C,最低温度为3°C,以及这个月以来温度的变化情况,一天中的温度差最高达到了15°C
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次的爬虫设计,使我对python网络爬虫有了更深一步的理解,可以通过源码的分析爬取一些简单的网页内容,这对我以后的毕业设计有很大的帮助。
原文:https://www.cnblogs.com/zero1314/p/12070759.html