其实B-Tree有许多变种,其中最常见的是B+Tree,比如MySQL就普遍使用B+Tree实现其索引结构。B-Tree相比,B+Tree有以下不同点:
下面是一个简单的B+Tree示意
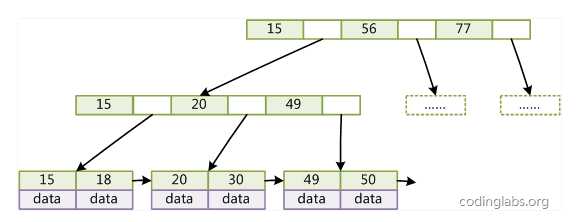
由于并不是所有节点都具有相同的域,因此B+Tree中叶节点和内节点一般大小不同。这点与B-Tree不同,虽然B-Tree中不同节点存放的key和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中B-Tree往往对每个节点申请同等大小的空间。一般来说,B+Tree比B-Tree更适合实现外存储索引结构,具体原因与外存储器原理及计算机存取原理有关,将在下面讨论。
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
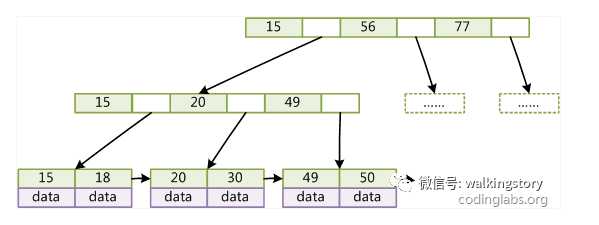
如图所示,在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
这一节对B-Tree和B+Tree进行了一个简单的介绍,下一节结合存储器存取原理介绍为什么目前B+Tree是数据库系统实现索引的首选数据结构。
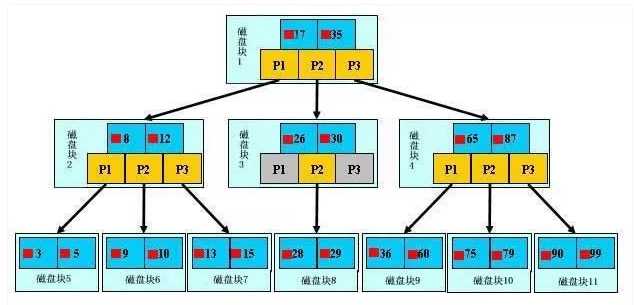
B-树和B+树查找过程基本一致。如上图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
这一章从理论角度讨论了与索引相关的数据结构与算法问题,下一章将讨论B+Tree是如何具体实现为MySQL中索引,同时将结合MyISAM和InnDB存储引擎介绍非聚集索引和聚集索引两种不同的索引实现形式。
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
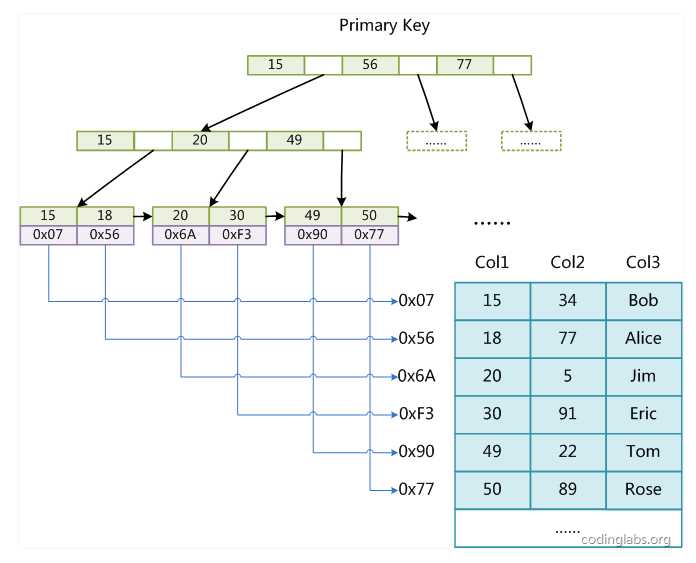
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
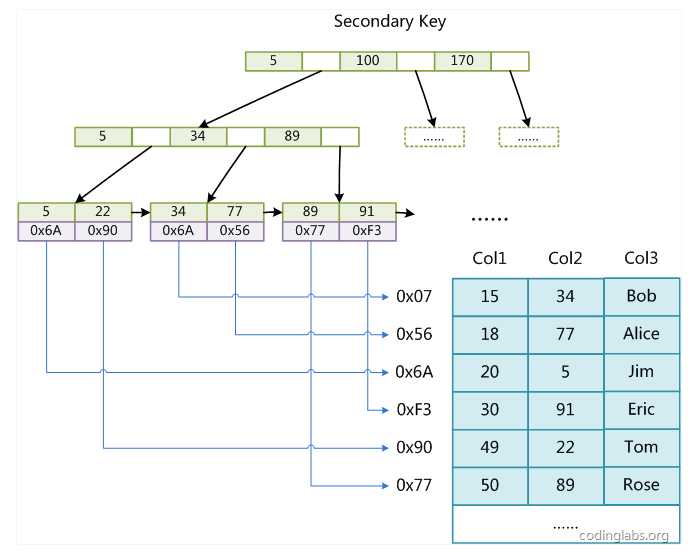
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。 MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
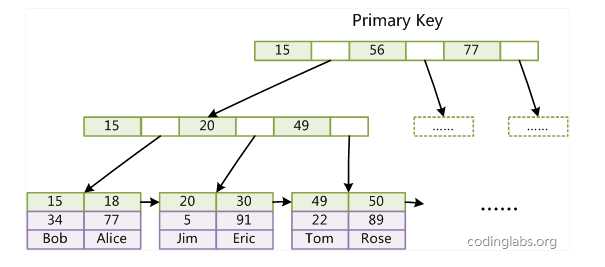
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
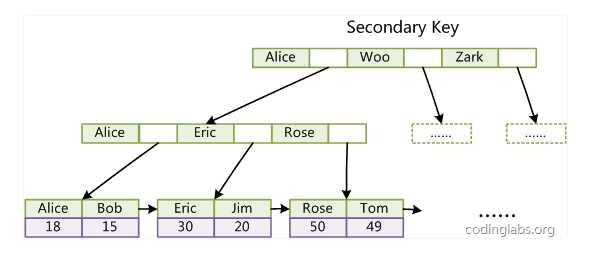
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
首先介绍一下联合索引。联合索引其实很简单,相对于一般索引只有一个字段,联合索引可以为多个字段创建一个索引。它的原理也很简单,比如,我们在(a,b,c)字段上创建一个联合索引,则索引记录会首先按照A字段排序,然后再按照B字段排序然后再是C字段,因此,联合索引的特点就是:
| A | B | C | | 1 | 2 | 3 | | 1 | 4 | 2 | | 1 | 1 | 4 | | 2 | 3 | 5 | | 2 | 4 | 4 | | 2 | 4 | 6 | | 2 | 5 | 5 |
其实联合索引的查找就跟查字典是一样的,先根据第一个字母查,然后再根据第二个字母查,或者只根据第一个字母查,但是不能跳过第一个字母从第二个字母开始查。这就是所谓的最左前缀原理。
我们再来详细介绍一下联合索引的查询。还是上面例子,我们在(a,b,c)字段上建了一个联合索引,所以这个索引是先按a 再按b 再按c进行排列的,所以:
以下的查询方式都可以用到索引
select * from table where a=1; select * from table where a=1 and b=2; select * from table where a=1 and b=2 and c=3;
上面三个查询按照 (a ), (a,b ),(a,b,c )的顺序都可以利用到索引,这就是最左前缀匹配。
如果查询语句是:
select * from table where a=1 and c=3; 那么只会用到索引a。
如果查询语句是:
select * from table where b=2 and c=3; 因为没有用到最左前缀a,所以这个查询是用户到索引的。
如果用到了最左前缀,但是顺序颠倒会用到索引码?
select * from table where b=2 and a=1; select * from table where b=2 and a=1 and c=3;
如果用到了最左前缀而只是颠倒了顺序,也是可以用到索引的,因为mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。但我们还是最好按照索引顺序来查询,这样查询优化器就不用重新编译了。
除了联合索引之外,对mysql来说其实还有一种前缀索引。前缀索引就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。
一般来说以下情况可以使用前缀索引:
一些文章中也提到:
MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:MySQL 不能在 ORDER BY 或 GROUP BY 中使用前缀索引,也不能把它们用作覆盖索引(Covering Index)。
SELECT * FROMhoudunwangWHEREunameLIKE‘后盾%‘ -- 走索引 SELECT * FROMhoudunwangWHEREunameLIKE "%后盾%" -- 不走索引
字符串与数字比较不使用索引;
CREATE TABLEa(achar(10)); EXPLAIN SELECT * FROMaWHEREa="1" – 走索引 EXPLAIN SELECT * FROM a WHERE a=1 – 不走索引
正则表达式不使用索引,这应该很好理解,所以为什么在SQL中很难看到regexp关键字的原因
原文:https://www.cnblogs.com/silver-aircraft/p/12074522.html