爬取泉州地区一居租房的信息
爬取页面+存取数据

#爬取链家html页面 def gethtml(url): #请求头伪装 kv = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36‘} #判断是否异常 try: #timeout设置延时 data = requests.get(url, headers=kv, timeout=10) #判断页面是否爬取成功 data.raise_for_status() # 使用HTML页面内容中分析出的响应内容编码方式 data.encoding = data.apparent_encoding #返回页面内容 return data.text except: #如果爬取失败,返回“爬取失败” return "爬取失败"
#获取房屋地点 def gethouse(pages): house = [] for page in range(1, pages+1): #获取信息的目标url url = ‘https://quanzhou.lianjia.com/zufang/pg{}10‘.format(page) html = gethtml(url) #页面格式化 soup = BeautifulSoup(html, ‘html.parser‘) ptag = soup.find_all("p", attrs="content__list--item--des") for tag in ptag: hous = tag.find_all(‘a‘)[2].text house.append(hous) return house
ptag = soup.find_all("p", attrs="content__list--item--title twoline") for tag in ptag: url = ‘https://quanzhou.lianjia.com‘ + tag.a.attrs[‘href‘] urls.append(url) return urls
span = soup.find_all(‘span‘, attrs=‘content__list--item-price‘) for tag in span: price = tag.find_all(‘em‘)[0].contents prices.append(int(price[0])) return prices

#读取文件 def read_file(): lines = [] #读出编码格式为utf-8 f = open(r"C:\lianjia\quanzhou.txt", "r", encoding=‘utf-8‘) #读取一行 line = f.readline() #循环 while line: print(line, end="") line = f.readline() lines.append(line) f.close() sorted(lines) return lines
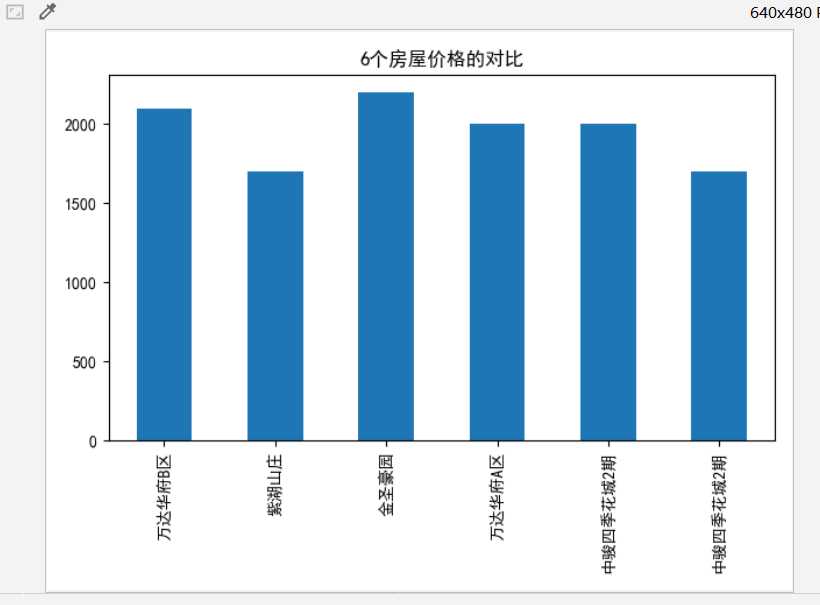
# 获取房屋列表 houselist = gethouse(3) # 获取房屋价格列表 pricelist = getprice(3) plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签 plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号 s = pd.Series(pricelist[0:6],houselist[0:6]) # 设置图表标题 s.plot(kind=‘bar‘, title=‘6个房屋价格的对比‘) # 输出图片 plt.show()
# 数据持久化存入new_move_list.txt def saveData(houselist, urllist, pricelist): try: # 创建新文件夹 os.mkdir("C:\lianjia") print("创建文件夹成功") except: # 如果文件夹存在则提示 "文件夹已存在" # 在新目录下创建文件用于存储爬取到的数据 #写入格式为utf-8 with open("C:\\lianjia\\quanzhou.txt", "w", encoding=‘utf-8‘) as f: #填入标题名称 title = ‘房屋地点‘ + ‘ ‘ + ‘月租金‘ + ‘ ‘ + ‘链接‘ + ‘\n‘ f.write(title) for i in range(len(houselist)): info = houselist[i] + ‘ ‘ + str(pricelist[i]) + ‘ ‘ + urllist[i] + ‘\n‘ f.write(info) print("存储成功")


import requests, re, os import pandas as pd from bs4 import BeautifulSoup import matplotlib.pyplot as plt import pandas as pd #爬取链家html页面 def gethtml(url): #请求头伪装 kv = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36‘} #判断是否异常 try: #timeout设置延时 data = requests.get(url, headers=kv, timeout=10) #判断页面是否爬取成功 data.raise_for_status() # 使用HTML页面内容中分析出的响应内容编码方式 data.encoding = data.apparent_encoding #返回页面内容 return data.text except: #如果爬取失败,返回“爬取失败” return "爬取失败" #获取房屋地点 def gethouse(pages): house = [] for page in range(1, pages+1): #获取信息的目标url url = ‘https://quanzhou.lianjia.com/zufang/pg{}10‘.format(page) html = gethtml(url) #页面格式化 soup = BeautifulSoup(html, ‘html.parser‘) ptag = soup.find_all("p", attrs="content__list--item--des") for tag in ptag: hous = tag.find_all(‘a‘)[2].text house.append(hous) return house #获取房屋页面链接 def geturl(pages): urls = [] for page in range(1, pages+1): #获取信息的目标url url = ‘https://quanzhou.lianjia.com/zufang/pg{}10‘.format(page) html = gethtml(url) #页面格式化 soup = BeautifulSoup(html, ‘html.parser‘) ptag = soup.find_all("p", attrs="content__list--item--title twoline") for tag in ptag: url = ‘https://quanzhou.lianjia.com‘ + tag.a.attrs[‘href‘] urls.append(url) return urls # 获取房屋价格 def getprice(pages): prices = [] for page in range(1, pages + 1): # 获取信息的目标url url = ‘https://quanzhou.lianjia.com/zufang/pg{}10‘.format(page) html = gethtml(url) # 页面格式化 soup = BeautifulSoup(html, ‘html.parser‘) span = soup.find_all(‘span‘, attrs=‘content__list--item-price‘) for tag in span: price = tag.find_all(‘em‘)[0].contents prices.append(int(price[0])) return prices # 数据持久化存入new_move_list.txt def saveData(houselist, urllist, pricelist): try: # 创建新文件夹 os.mkdir("C:\lianjia") print("创建文件夹成功") except: # 如果文件夹存在则提示 "文件夹已存在" # 在新目录下创建文件用于存储爬取到的数据 #写入格式为utf-8 with open("C:\\lianjia\\quanzhou.txt", "w", encoding=‘utf-8‘) as f: #填入标题名称 title = ‘房屋地点‘ + ‘ ‘ + ‘月租金‘ + ‘ ‘ + ‘链接‘ + ‘\n‘ f.write(title) for i in range(len(houselist)): info = houselist[i] + ‘ ‘ + str(pricelist[i]) + ‘ ‘ + urllist[i] + ‘\n‘ f.write(info) print("存储成功") #读取文件 def read_file(): lines = [] #读出编码格式为utf-8 f = open(r"C:\lianjia\quanzhou.txt", "r", encoding=‘utf-8‘) #读取一行 line = f.readline() #循环 while line: print(line, end="") line = f.readline() lines.append(line) f.close() sorted(lines) return lines def main(): # 自定义爬取页数 pages = 3 #获取房屋链接列表 urllist = geturl(pages) #获取房屋列表 houselist = gethouse(pages) #获取房屋价格列表 pricelist = getprice(pages) #保存数据 saveData(houselist, urllist, pricelist) #读取数据 read_file() if __name__ == ‘__main__‘: main() #图形化界面 # 获取房屋列表 houselist = gethouse(3) # 获取房屋价格列表 pricelist = getprice(3) plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签 plt.rcParams[‘axes.unicode_minus‘] = False # 用来正常显示负号 s = pd.Series(pricelist[0:6],houselist[0:6]) # 设置图表标题 s.plot(kind=‘bar‘, title=‘6个房屋价格的对比‘) # 输出图片 plt.show()
原文:https://www.cnblogs.com/cw111/p/12072399.html