HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导入的效率的一种可行方案,那就是使用Mapper类先进行数据清洗,再在APP中批量导入,废话不多说,我们直接开始吧!
首先我们准备好一份csv文件学生表,其中包含的是学生信息,具体信息如下:

对于此文件来说,每一行有四个字段,第一个代表rowkey,第二个代表name,第三个代表course,第四个代表score
接着,我们在hbase shell中建立一张学生表,之后数据将会直接导入至这张表中去:
hbase shell
> create_namespace ‘ns1‘
> create ‘ns1:student‘, ‘info‘
HfileMapper类:
package bulkload; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class HfileMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] strs = line.split(","); //首先获取到学生的学号 String id = strs[0]; ImmutableBytesWritable rowKey = new ImmutableBytesWritable(Bytes.toBytes(id)); //然后新建一个Put对象并分别获取到name,course以及score字段 Put put = new Put(Bytes.toBytes(id)); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(strs[1])); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("course"), Bytes.toBytes(strs[2])); put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("score"), Bytes.toBytes(strs[3])); // context.write(rowKey,put); } }
HfileApp类:
package bulkload; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class HfileApp { public static void main(String[] args) throws Exception { //这里也必须写成Hbase的Configuration Configuration conf = HBaseConfiguration.create(); conf.set("fs.defaultFS","file:///"); System.setProperty("HADOOP_USER_NAME","root"); Job job = Job.getInstance(conf); //设置作业名称以及各个class对象 job.setJobName("bulkload"); job.setJarByClass(HfileApp.class); job.setMapperClass(HfileMapper.class); job.setOutputFormatClass(HFileOutputFormat2.class); //设置Mapper的输出KV job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); FileInputFormat.addInputPath(job,new Path("d:/student.csv")); HFileOutputFormat2.setOutputPath(job,new Path("hdfs://mycluster/hfile")); //由于Hbase是有特定结构的,不像Hive那样可以很轻松地load data,因此需要指定表进行生成 Connection conn = ConnectionFactory.createConnection(conf); HFileOutputFormat2.configureIncrementalLoad(job,conn.getTable(TableName.valueOf("ns1:student")), conn.getRegionLocator(TableName.valueOf("ns1:student"))); boolean b = job.waitForCompletion(true); //开始进行bulk load批量导入程序 if(b){ LoadIncrementalHFiles incr = new LoadIncrementalHFiles(conf); incr.doBulkLoad(new Path("hdfs://mycluster/hfile"),conn.getAdmin(),conn.getTable(TableName.valueOf("ns1:student")), conn.getRegionLocator(TableName.valueOf("ns1:student"))); } conn.close(); } }
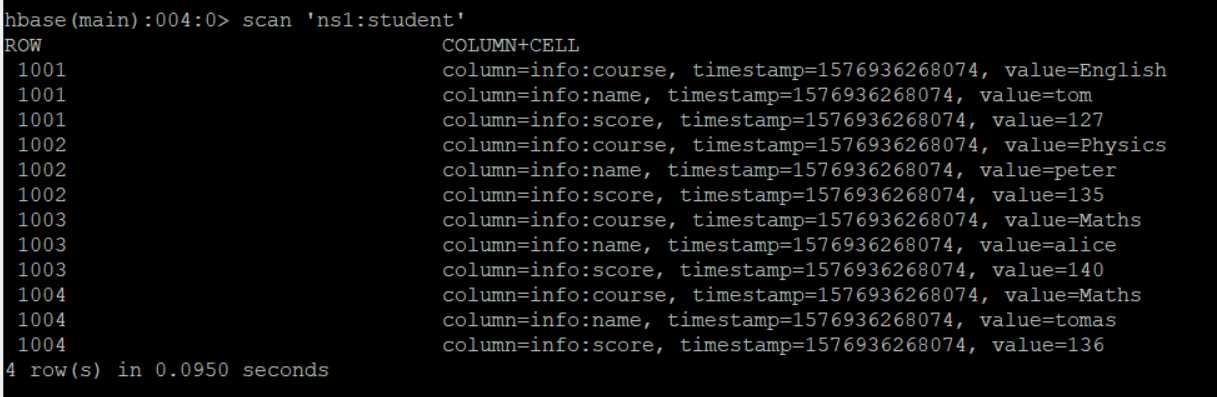
去HBase中查看学生表信息,成功插入!!!
原文:https://www.cnblogs.com/w950219/p/12078451.html