pandas功能用法汇总#非常重要#
一.series
1.特点
#有索引索引可以更改且索引可以是字符串
#具有相同索引的series可以进行运算操作
#具有相同标签的series和dataframe可以进行操作
2.创建
import pandas as pd
s = pd.Series([1,2,3,4,5])
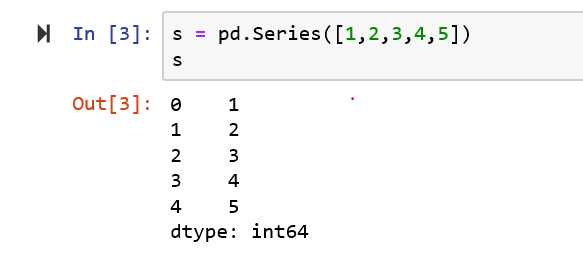
s = pd.Series([1,2,3,4,5],index=list(‘abcdf‘))

3.计算
#数组,series有矢量的特征,可以与标量进行计算,本质上是值和标签
#进行计算,常用布尔计算
#计算--series value 属性和标量
s1=pd.Series({‘北京‘:‘023‘,‘杭州‘:‘234‘,‘沈阳‘:‘123‘})
s2=pd.Series({‘北京‘:‘023‘,‘杭州‘:‘234‘,‘沈阳‘:‘123‘})
print(s1*2+s2)
二.dataframe
1.csv中获取
pd.read_csv(‘.csv‘)
2.切片
data.loc 闭区间切片 使用标签
data.iloc 左闭右开切片 使用物理位置
data.head(10)取前10行数据
#loc应用
print(data.loc[:3,[‘position‘,‘AQI‘]])
print(data.loc)#行数据 物理位置
demo=data.head(5)#切片前提,字符串有序
damo.index=list(‘abcde‘)
demo.loc[‘a‘:‘c‘]
#iloc应用
data.iloc[0:3]#前闭后开/列只能用物理位置
demo.ix[]#可以跟位置和标签
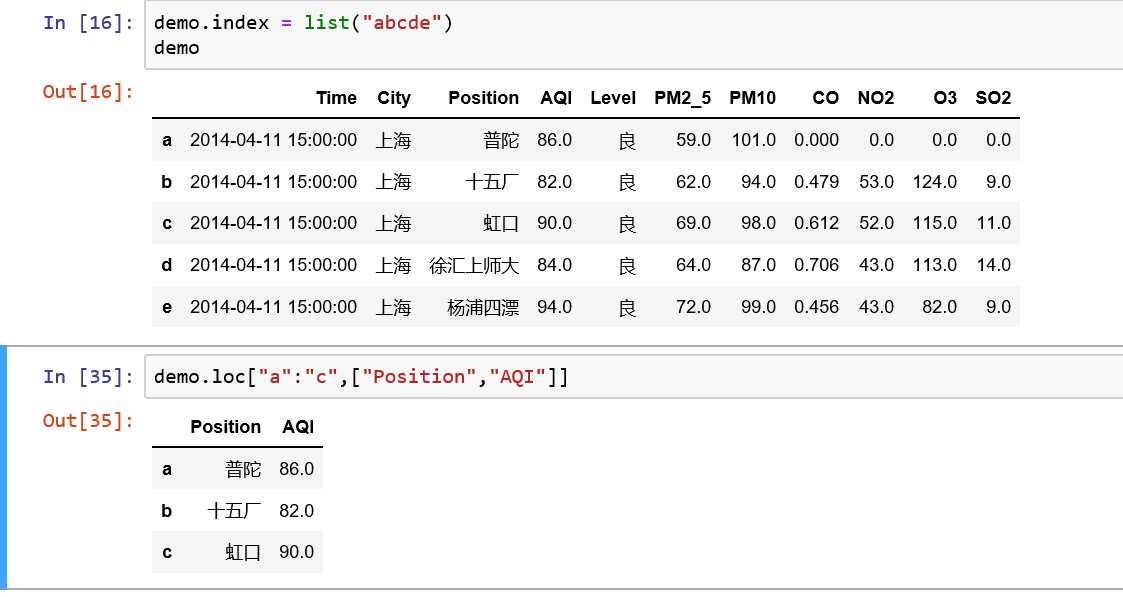
3.增加列和行
增加列可以加入一个标签相同的series
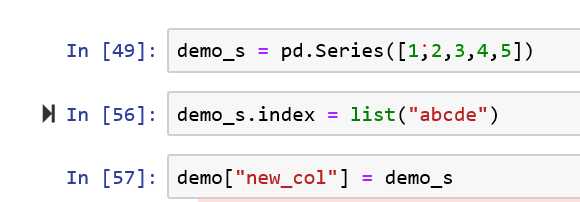
添加行concat
4.与或非运算
demo[(demo.district==‘朝阳‘) & (demo[‘total price‘]>400)]#与操作
demo[(demo.district==‘朝阳‘) | (demo[‘total price‘]>400)]#或操作
demo[~ demo.Distrct= ‘朝阳‘]#非操作
5.计算
缺失值可以fillna/dropna/布尔索引
dataframe.count()计算列中一共多少行
dataframe.value_counts()#分组去重
原文:https://www.cnblogs.com/LuciferRex/p/12080933.html