列表推导是一种构建列表(list)的快捷方式
#列表推导 symbols = ‘!@#$%‘ codes = [ord(symbol) for symbol in symbols] #ord()Python内置函数,将字符变成Unicode码位,返回值为对应十进制 print(codes)
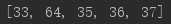
列表推导同filter()和map()比较
"""
1.fitter()函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
语法:
filter(function, iterable)
参数:
function -- 判断函数
iterable -- 可迭代对象
2.map()函数会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法:
map(function, iterable, ...)
参数:
function -- 函数
iterable -- 一个或多个序列
3.lambda函数是一个简短的匿名函数,可以接收任意数量的参数,但只能包含一个表达式。
语法:
lambda 参数:表达式
"""
symbols = ‘!@#$%‘ codes = [ord(symbol) for symbol in symbols if ord(symbol) > 50] print(codes) codes = list(filter(lambda c: c > 50, map(ord, symbols))) print(codes)

笛卡尔积:用列表推导可以生成两个或以上的可迭代类型的笛卡儿积。笛卡儿积是一个列表,列表里的元素是由输入的可迭代类型的元素对构成的元组,因此笛卡儿积列表的长度等于输入变量的长度的乘积
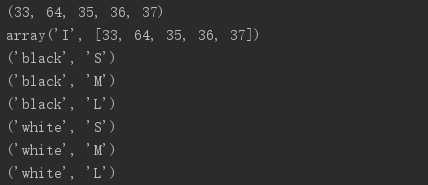
colors = [‘black‘, ‘white‘] sizes = [‘S‘, ‘M‘, ‘L‘] tshirt = [(color, size) for color in colors for size in sizes] print(tshirt) tshirt = [ ] for color in colors: for size in sizes: tshirt.append((color, size)) print(tshirt) tshirts = [(color, size) for size in sizes for color in colors] print(tshirts)

虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。这是因为生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。前面那种方式显然能够节省内存。生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
#用生成器表达式初始化元组和数组 symbols = ‘!@#$%‘ codes = tuple(ord(symbol) for symbol in symbols) print(codes) import array arr = array.array(‘I‘, (ord(symbol) for symbol in symbols)) print(arr) #使用生成器表达式计算笛卡尔积 colors = [‘black‘, ‘white‘] sizes = [‘S‘, ‘M‘, ‘L‘] # ‘%s‘%表示格式化一个对象为字符 for tshirt in (‘%s %s‘ % (c, s) for c in colors for s in sizes): print(tshirt)
—————————————————————————————————————————————————————————
原文:https://www.cnblogs.com/er-gou-zi/p/12088017.html