关注解状态而不是路径代价的问题(N皇后),找目标,纯粹最优化的问题。
从单个当前结点出发,通常只移动到他的临近状态而不保留搜索路径。
不断向值增加的方向持续移动,直到达到一个“峰顶”。
使用内存少,速度快。
局部最优,在局部极大值、山脊、高原的情况下将陷入困境;
成功与否严重依赖与状态空间的地形图形状。
随机爬山法
在上山移动中随机的选择下一步,每种走法被选中的概率随上山移动的陡峭程度不同而不同。
收敛速度慢,但在某些地形图上能找到更好的解。
首选爬山法
随机的生成后继结点,直到生成一个优于当前结点的后继。
适用于后继结点很多的情况。
随机重启爬山法
不断随机生成初始状态来引导爬山法的搜索,直到成功找到目标状态。
完备概率接近1。
选择随机移动,允许算法向最坏的方向移动以摆脱局部最大值,但随着状态“变坏”与时间的推移,接受“坏移动”的概率下降。
| 物理退火 | 退火算法 |
|---|---|
| 物体内部状态 | 问题解空间 |
| 状态能量 | 解的质量 |
| 温度 | 控制参数 |
| 加热(溶解)过程 | 设定初始控制参数 |
| 退火冷却过程 | 控制参数的修改 |
| 状态转移 | 解在领域中变化 |
| 能量最低状态 | 最优解 |
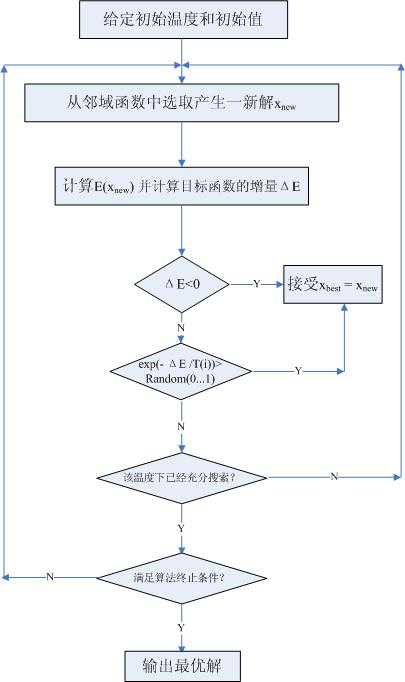
如果时间下降得足够的慢,那么模拟退火算法找到一个全局最优值的概率接近于1
从k个随机生成的状态开始,每一步全部k个状态的所有后继会被随机生成。如果其中一个是目标状态,算法停止。否则,从后继中选择k个最佳的后继。重复这个过程。
有用的信息在并行的搜索线程间传递。
状态缺乏多样性,可能聚集到状态空间的一小块区域内,使搜索代价比爬山法还高。
从k个随机生成的状态开始,作为初始种群,其中每个状态叫做个体,对每个状态进行编码。根据适应度函数的值决定每个个体被选中的概率。选择k个状态作为父状态,每两个父状态交叉生成两个子状态。最后对子状态进行变异操作。重复直到得到目标解。
染色体编码
二进制编码、格雷码等
种群初始化
适应度函数
演化过程中进行选择的唯一依据。对于好的状态,适应度函数返回较高的值。
遗传操作
选择
样本被选择繁衍后代的概率正比于它的适应度函数值
交叉
发生交叉操作的概率需要预先设定,交叉位置随机产生
变异
发生突变操作的概率需要预先设定,通常远小于交叉概率
算法参数
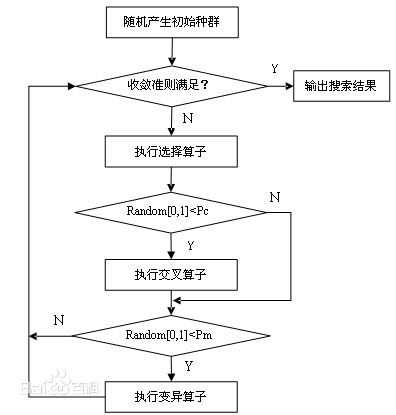
优胜劣汰的选择机制使得适应值大的解有较高的存活率,这是遗传算法与一般搜索算法的主要区别之一。
为一些难以找到传统数学模型的难题指出了一个解决办法。
不确定的环境,执行一个动作后状态的变化是不确定的。
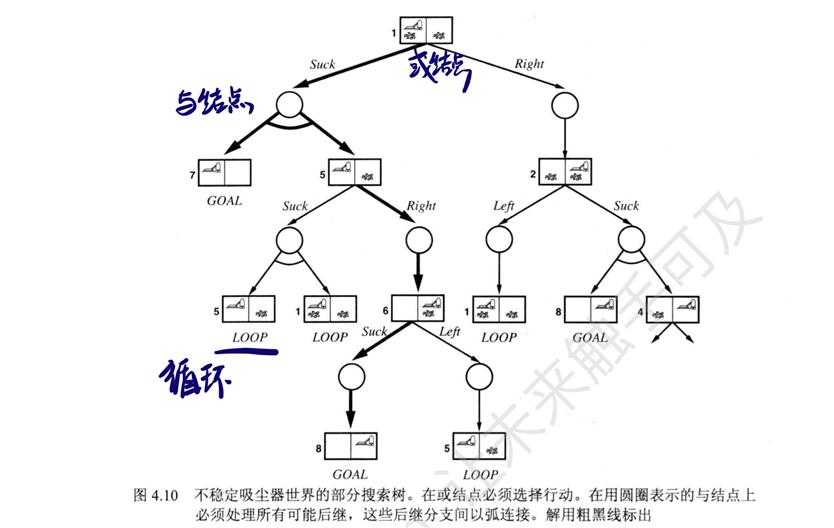
与或搜索问题的解是一颗子树(图中用粗线标出)。每个叶子上都有目标结点;在或节点上规范了一个行动;与结点上包含所有可能的后果。
深度优先递归算法
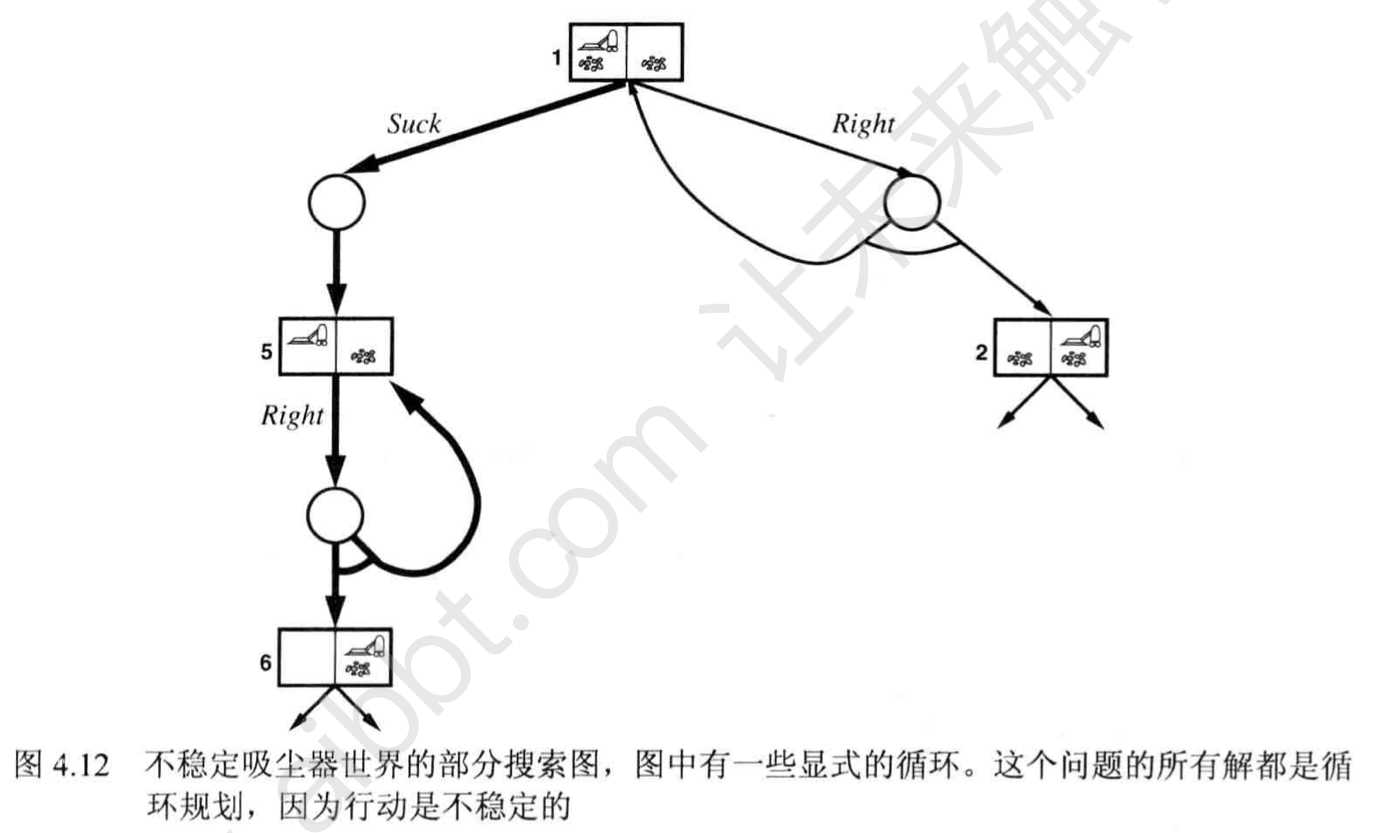
关键:环的处理
如果当前状态与从根节点出发的路径上的状态相同,那么返回失败。
这样每条路都必定到达目标、重复状态或死胡同,这样就可以保证算法可以在有限的状态空间终止。
宽度优先
最佳优先
启发式函数概念必须修改为评估可能的解,而不是一个序列。
语法表示为
\[
[Suck,L_1:Right,if \ State=5\ then\ L_1\ else\ Suck]
\]
或
\[
[while\ State=5\ do\ Right]
\]
对于循环解,根据具体问题,决定不断尝试或尝试一定次数后放弃谁更合理。
信念状态
包含物理状态中每个可能的集合,假定N个物理状态,最多有\(2^N\)个信念状态
初始状态
所有物理状态的集合
行动
非法行动对环境无影响时

有影响时,可能取交集。
//吸尘器世界中,每个状态都有相同的合法行动,两种方法都有相同结果。
转移模型
对于确定行动

对于不确定行动

目标测试
信念状态中的所有物理状态都满足目标状态
路径开销
假定所有状态下一个行动的开销相同
检测状态是否重复。
如果一个行动序列是信念状态b的解,那么它也是b的任何子集的解。所以如果已经生成子集,那么可以丢弃到元集合的解。当原集合有解,那么他也是他的任何子集的解。
每个信念状态的大小。
通过用更紧凑的方式表示信念状态,或增量式信念状态搜索(首先找出适合状态1的解,看他是否也满足2;不满足则回溯找出状态1的另一种解,然后继续...)
预测阶段
给定信念状态b和行动a,预测信念状态
观察预测阶段
确定预测信念状态中可观察到的感知信息o
更新阶段
根据每个可能的感知信息得到信念状态
形式化,搜索算法,执行解行动
解是一个条件规划不是一个序列 if-then-else
Agent在完成行动和接收感知信息时维护自身的信念状态
未知环境。
不知道在当前状态下采取行动后的对应状态,只能通过执行行动后再观察来确定。
脱机搜索算法:在行动之间计算好完整的解决方案。
联机搜索算法:行动,观察环境,下一步行动。
竞争比=实际代价/最小代价。
竞争比越小越好。
竞争比可以是无穷大,比如达到某些状态后无法达到目标状态(活动不可逆)。
可安全探索的状态空间:每个可达到的状态出发都有达到目标状态的行动,如迷宫问题,八数码问题。
欢迎指正与补充,感谢点赞o( ̄▽ ̄)d
原文:https://www.cnblogs.com/Gru-blog/p/12098932.html