实验楼平台上的实验环境及版本:java8,python2.7,scala2.11.8,hadoop2.7.3,spark2.4.4
Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。例如一次排序测试中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。Spark 集群目前最大的可以达到 8000 节点,处理的数据达到 PB 级别,在互联网企业中应用非常广泛。
Hadoop 的核心是分布式文件系统 HDFS 和计算框架 MapReduces。Spark 可以替代 MapReduce,并且兼容 HDFS、Hive 等分布式存储层,良好的融入 Hadoop 的生态系统。
Spark 执行的特点
中间结果输出:Spark 将执行工作流抽象为通用的有向无环图执行计划(DAG),可以将多 Stage 的任务串联或者并行执行。
数据格式和内存布局:Spark 抽象出分布式内存存储结构弹性分布式数据集 RDD,能够控制数据在不同节点的分区,用户可以自定义分区策略。
任务调度的开销:Spark 采用了事件驱动的类库 AKKA 来启动任务,通过线程池的复用线程来避免系统启动和切换开销。
Spark 的优势
速度快,运行工作负载快 100 倍。Apache Spark 使用最先进的 DAG 调度器、查询优化器和物理执行引擎,实现了批处理和流数据的高性能。
易于使用,支持用 Java、Scala、Python、R 和 SQL 快速编写应用程序。Spark 提供了超过 80 个算子,可以轻松构建并行应用程序。您可以从 Scala、Python、R 和 SQL shell 中交互式地使用它。
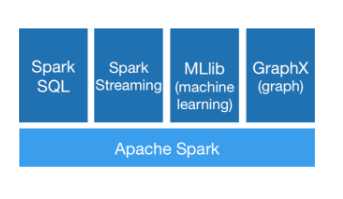
普遍性,结合 SQL、流处理和复杂分析。Spark 提供了大量的库,包括 SQL 和 DataFrames、用于机器学习的 MLlib、GraphX 和 Spark 流。您可以在同一个应用程序中无缝地组合这些库。
各种环境都可以运行,Spark 在 Hadoop、Apache Mesos、Kubernetes、单机或云主机中运行。它可以访问不同的数据源。您可以使用它的独立集群模式在 EC2、Hadoop YARN、Mesos 或 Kubernetes 上运行 Spark。访问 HDFS、Apache Cassandra、Apache HBase、Apache Hive 和数百个其他数据源中的数据。
Spark 生态系统 BDAS
目前,Spark 已经发展成为包含众多子项目的大数据计算平台。BDAS 是伯克利大学提出的基于 Spark 的数据分析栈(BDAS)。其核心框架是 Spark,同时涵盖支持结构化数据 SQL 查询与分析的查询引擎 Spark SQL,提供机器学习功能的系统 MLBase 及底层的分布式机器学习库 MLlib,并行图计算框架 GraphX,流计算框架 Spark Streaming,近似查询引擎 BlinkDB,内存分布式文件系统 Tachyon,资源管理框架 Mesos 等子项目。这些子项目在 Spark 上层提供了更高层、更丰富的计算范式。
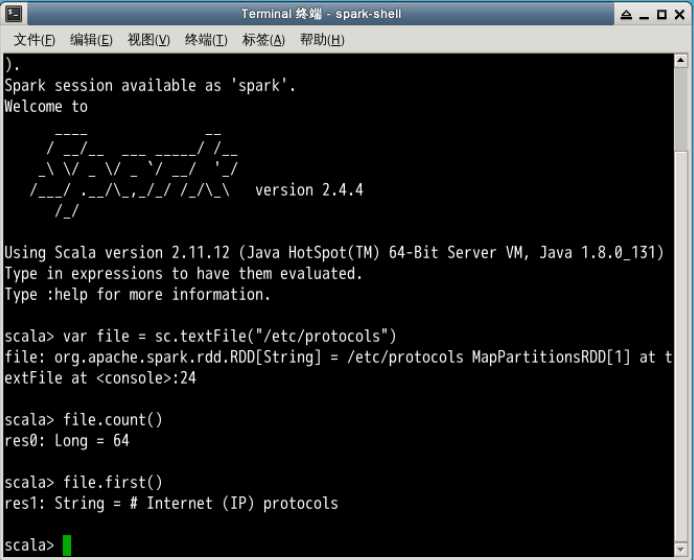
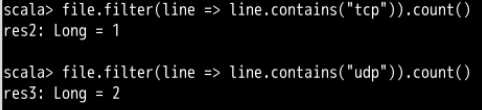
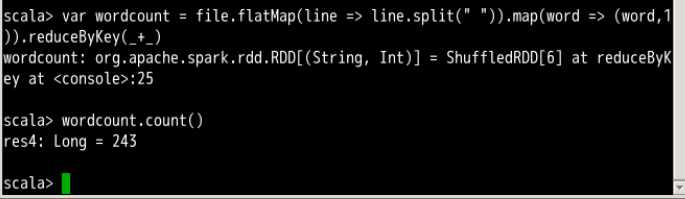
Pyspark
相当于是一个用python来操纵spark的一个sparkshell
mapReduce
该睡觉了,明晚继续学
原文:https://www.cnblogs.com/ltl0501/p/12099459.html