TCP的拥塞控制
什么是拥塞控制
所谓拥塞控制就是防止过多的数据注入网络中,这样就可以使网络中的路由器和链路不致过载。当出现网络拥塞时,会造成分组的丢失,但参与通信的端点并不能了解到拥塞发生的细节,对其来说,拥塞往往表现为通信时延的增加。
为什么需要拥塞控制
一旦网络发生拥塞,分组所经历的时延会变大,分组丢失的可能性会变大,发送端需要重传的分组会变多,这只会导致更多的分组注入到网络中,而网络越来越拥塞,形成恶性循环。因此,为了处理网络拥塞,需要一些机制以在面临网络拥塞时遏制发送方发送分组的速率。
开环控制和闭环控制
开环控制:开环控制方法就是在设计网络时事先将有关发生拥塞的因素考虑周到,力求网络在工作时不产生拥塞。
闭环控制:闭环控制方法是基于反馈环路的概念。属于闭环控制的有以下几种措施:
1. 监测网络系统以便检测到拥塞在何时、何处发生。
2. 将拥塞发生的信息传送到可采取行动的地方。
3. 调整网络系统的运行以解决出现的问题。
拥塞控制
TCP使用的是基于窗口的方法进行拥塞控制。这是一种闭环控制方法。
方法:发送方在确定发送分组/报文段的速率时,既要根据接收方的接受能力,又要从全局考虑防止网络发生拥塞。因此,TCP 协议要求发送方维持以下两个窗口:
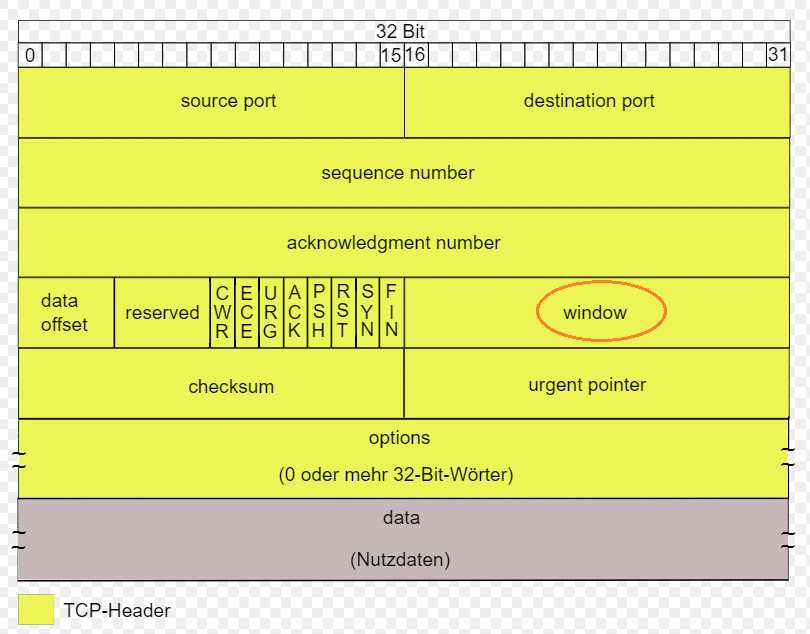
1. 接收窗口 rwnd,接收方根据目前接收缓存大小所许诺的最新的窗口值,反应了接收方的容量。由接收方根据其在TCP报文的首部的窗口字段通知发送发。
2. 拥塞窗口 cwnd,发送方根据自己估算的网络拥塞程度而设置的窗口值,反映了网络的当前容量。只要网络没用拥塞,拥塞窗口就会再增大一些,以便把更多的分组发送出去,这样就可以提高网络的利用率;但是只要网络出现拥塞,拥塞窗口就会减小一些,以减少注入到网络中的分组数, 以便缓解网络出现的拥塞。
发送窗口的上限值等于当前 接收窗口 rwnd 和 拥塞窗口 cwnd 中的较小的一个。
TCP拥塞控制算法
四种(RFC 5681)拥塞控制算法:
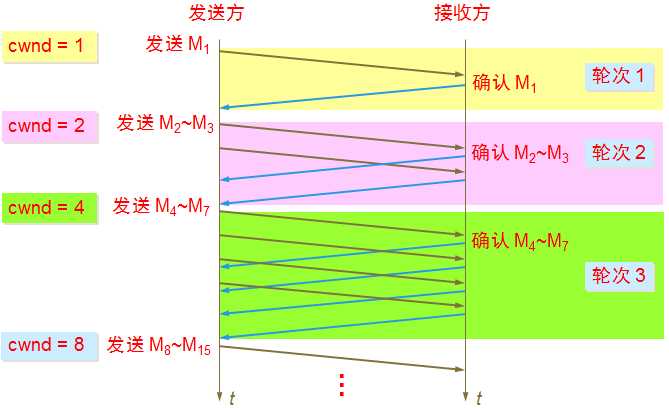
慢开始(slow-start)
拥塞避免(congestion avoidance)
快重传(fast retransmit)
快恢复(fast recovery)
慢开始(slow-start) 和 拥塞避免(congestion avoidance)
慢开始的目的是:防止一开始速率过快,导致耗尽中间路由器存储空间,从而严重降低TCP连接的吞吐量。
拥塞避免的目的是:当拥塞发生时,降低网络的传输速率。这可以通过调用慢启动的动作来降低网络的传输速率。所以在实际中这两个算法通常在一起实现。
初始拥塞窗口cwnd设置:新的RFC 5681 把初始拥塞窗口cwnd设置为不超过2至4 个MSS (Maximum Segment Size) 的数值。
拥塞窗口cwnd控制方法:在每收到一个对新的报文段的确认后,可以把拥塞窗口增加最多一个SMSS 的数值。
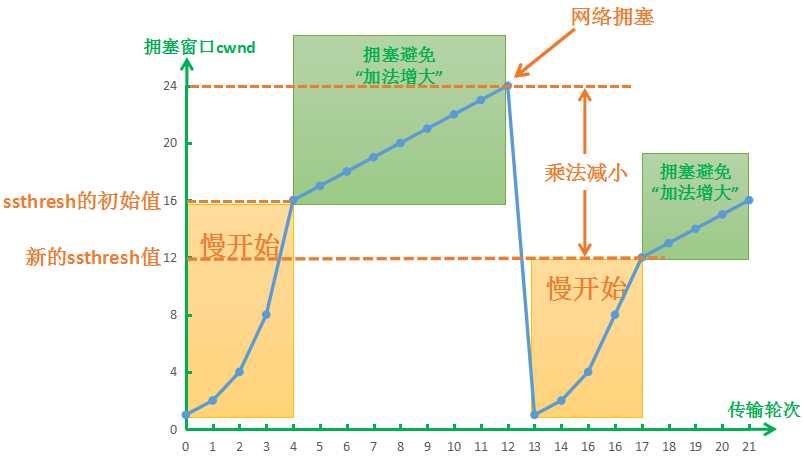
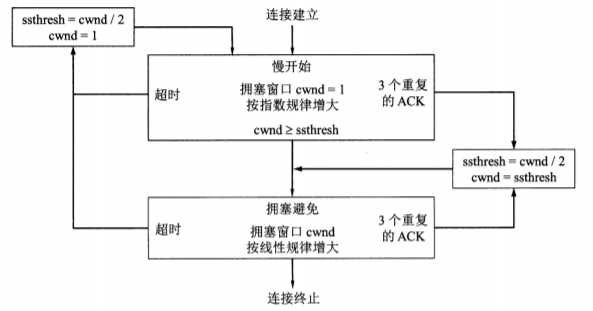
使用慢开始算法后,每经过一个传输轮次(往返时延RTT),拥塞窗口 cwnd 就会增加增加一倍,即:慢开始算法时,cwnd 的大小成指数形式的增长。这样慢开始一直把拥塞窗口 cnwd 增大到一个规定的慢开始门限 ssthresh (阈值),然后开始使用拥塞避免算法。
慢开始门限ssthresh(阈值):使拥塞窗口 cwnd 缓慢增长,以防止过早引起网络拥塞。
拥塞避免算法:让拥塞窗口 cwnd 缓慢地增大,即每经过一个往返时间 RTT 就把发送方的拥塞窗口 cwnd 增加一个MSS的大小, 而不是加倍,使拥塞窗口 cwnd 按线性规律缓慢增长(即:加法增大),当出现一次超时 (网络拥塞) 时,则设置慢开始门限 ssthresh 等于当前 cwnd 值的一半(即:乘法减少),把 cwnd 从新设置成初始值,再执行慢开始算法。这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生路由器有足够的时间把队列中积压的分组处理完毕。
上述过程可归纳如下:
- 当 cwnd < ssthresh 时,使用慢开始算法,cwnd 的大小成指数形式的增长。
- 当 cwnd >= ssthresh 时,使用拥塞避免算法,cwnd 的大小成线性增长。
- 当出现网络拥塞时,设置 ssthresh 为当前 cwnd 的一半,同时把 cwnd 重新设置成初始值,然后从新执行慢开始算法
拥塞避免并没有真正避免拥塞,即利用以上措施不可能避免拥塞,拥塞避免旨在在拥塞避免阶段把拥塞窗口控制为按线性规律增长,使网络比较不易发生拥塞。
快重传(fast retransmit) 和 快恢复(fast recovery)
快重传和快恢复是对慢开始和拥塞避免算法的改进。
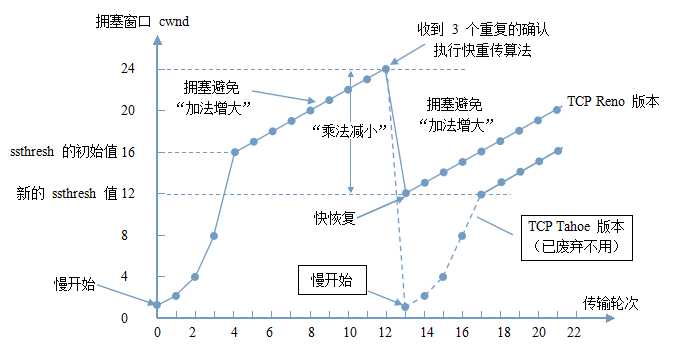
快重传(Fast retransmit)是对TCP发送方降低等待重发丢失分段用时的一种改进。TCP发送方在每发送一个分组时会启动一个超时计时器,如果相应的分组确认没在特定时间内被送回,发送方就假设这个分段在网络上丢失了,需要重发。这也是TCP用来估计RTT的测量方法。重复确认就是这个阶段的基础,其基于以下过程:如果接收方接收到一个数据分组,就会将该分组的序列号加上数据字节长的值,作为分段确认的确认号,发送回发送方,表示期望发送方发送下一个序列号的分段。但是如果接收方提前收到更下一个序列号的分组——或者说接收到无序到达的分组,即之前期望确认号对应的分段出现接收丢失——接收方需要立即使用之前的确认号发送分组确认。此时如果发送方收到接收方相同确认号的分组确认超过1次,并且该对应序列号的分组超时计时器仍没超时的话,则这就是出现重复确认,需要进入快速重传。
快重传就是基于以下机制:如果假设重复阈值为3,当发送方收到4次相同确认号的分组确认(第1次收到确认期望序列号,加3次重复的期望序列号确认)时,则可以认为继续发送更高序列号的分段将会被接受方丢弃,而且会无法有序送达。发送方应该忽略超时计时器的等待重发,立即重发重复分段确认中确认号对应序列号的分组。
快恢复算法原理:当发送端收到连续的相同确认号的分组确认 3 次时,就执行”乘法减小“算法,把慢开始门限ssthresh 设置为出现拥塞时 cwnd 大小的一半,与慢开始不同之处是快恢复算法把 cwnd 的值设置为慢开始门限ssthread 变更后的值,然后开始执行拥塞避免算法(”加法增大“),使拥塞窗口缓慢地线性增大(即:跳过慢开始阶段)。
上述过程可归纳如下:
- 当 cwnd < ssthresh 时,使用慢开始算法,cwnd 的大小成指数形式的增长。
- 当 cwnd >= ssthresh 时,使用拥塞避免算法,cwnd 的大小成线性增长。
- 当出现网络拥塞时,设置 ssthresh 为当前 cwnd 的一半,然后把 cwnd 的值设置成 ssthresh 的值,再执行拥塞避免算法。
快恢复算法的执行过程:
总之,上述过程可归纳为如下流程:
注:图片来自网络。
参考资料:https://zh.wikipedia.org/wiki/TCP%E6%8B%A5%E5%A1%9E%E6%8E%A7%E5%88%B6
深入理解TCP协议及其源代码
原文:https://www.cnblogs.com/LiScott/p/12104317.html