首先出场的是:data-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<!--数据库-->
<dataSource name="test" type="JdbcDataSource" driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/test" user="root" password="password"/>
<document name="user">
<!--用户表-->
<entity dataSource="test" name="user" pk="id" query="select * from user">
<field column="id" name="id"/>
<field column="title" name="title"/>
</entity>
<!--如果要添加同一个数据库下的其他操作的话按照这个格式即可-->
<entity dataSource="test" name="xxxx" pk="xxxx" query="xxxxxx">
<field column="xxxx" name="xxx"/>
<field column="xxxxxx" name="xxxxx"/>
</entity>
</document>
</dataConfig>踩坑点:
- dataSource标签中的name必须和下面entity标签中的dataSource属性对应
- 一个dataSource下面只能有一个document但是可以有多个entity
- entity在配置的时候记得配置上主键(PK)
- entity中的每一个column都记得在schema.xml中配置
紧接着:schema.xml
<!-- 对数据库中的字段进行配置 -->
<field name="title" type="text_iksyn" indexed="true" stored="true" />
<!-- 同义词&IK分词 -->
<field name ="text" type ="text_iksyn" indexed ="true" stored ="false" multiValued ="true"/>
<fieldType name="text_iksyn" class="solr.TextField">
<analyzer type="index" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" isMaxWordLength="false" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>踩坑点:
- 对数据库中的字段配置真的是很有必要的!!!并且如果你想要后面的某个属性进行分词的话一定要指定他的type和后面配置的ik分词器中的一样!!!!!
- IK分词的时候注意上面的class一定不要错,不然到时候Reload的时候必报错
- index和query两个最好都配置上
- 注意在配置同义词的时候这个synonyms一定要对应好同义词词典
LowerCaseFilterFactory是一个配置不区分大小写的,可有可无
配置完这两个之后可以顺便把同义词词典给弄一下,见下面两幅图:
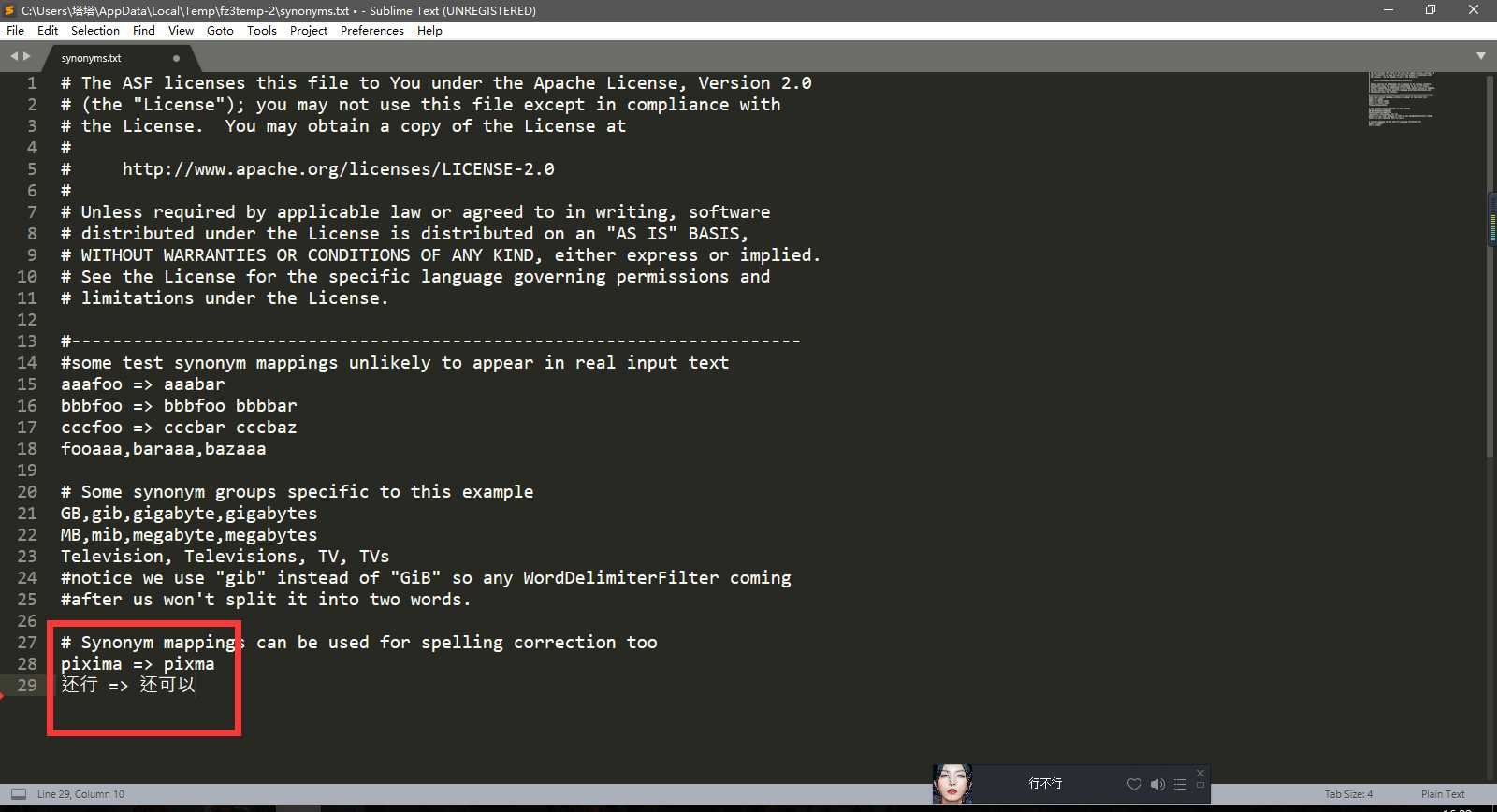
踩坑点:
保存的时候务必是utf-8,不然你会发现白弄了
可以用=>来进行配置,但是这样的话只能是左边等同于右边,比如输入还行会出来还可以,但是输入还可以那么还是还可以(这不是绕口令)
可以用英文的逗号进行分割,切记英文逗号!这样的配置可以等价替换
最后就是solrconfig.xml啦
<!-- 随便找个地方加上就好 -->
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler" >
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>截至到此差不多就可以啦,可别说你不知道ik该放在什么目录!好吧,起始刚开始我也不知道(/▽\=)
将IK的jar包放到/usr/solr/solr-5.5.5/server/solr-webapp/webapp/WEB-INF/lib目录下
将ext.dic、IKAnalyzer.cfg.xml、stopword.dic复制到/usr/solr/solr-5.5.5/server/solr-webapp/webapp/WEB-INF/classes目录下(classes自行创建)
IKAnalyzer.cfg.xml中的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>踩坑点:
扩展词词典和停用词词典一定要是utf-8格式的!
在刚下载下来的ext.dic配置扩展词词典的那句话是被注释掉的!千万记得去看一眼,一眼就好!
q(≧▽≦q)这下真的就结束啦!感谢观看!欢迎指正!
原文:https://www.cnblogs.com/starcoder/p/12108130.html