无论是Socket的读写还是文件的读写,用户程序进行IO的读写,基本上会用到read&write两大系统调用。可能不同操作系统,名称不完全一样,但是功能是一样的。
read系统调用,并不是把数据直接从物理设备,读数据到内存。write系统调用,也不是直接把数据,写入到物理设备。
read系统调用,是把数据从内核缓冲区复制到进程缓冲区;而write系统调用,是把数据从进程缓冲区复制到内核缓冲区。这个两个系统调用,都不负责数据在内核缓冲区和磁盘之间的交换。底层的读写交换,是由操作系统内核完成的。
以下举个socketio读写的例子
 \
\
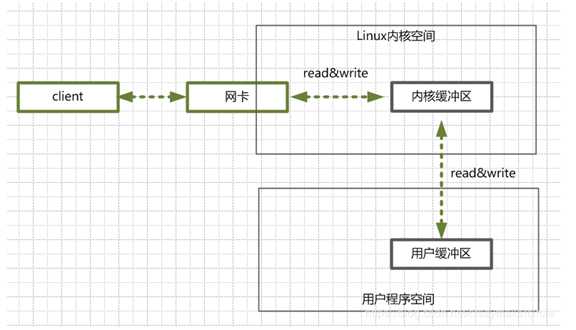
这是一个服务端处理网络请求的过程
1)客户端请求
liunx通过网卡获取到客户端上传的数据,并将其读入内核缓冲区
2)程序获取数据
服务端通过内核缓冲区将数据读到Java进程缓冲区中
3)服务端像客户端返回数据,也是这个流程
目前为止,Java共支持3种网络编程模型:BIO、NIO、AIO,本文只介绍BIO与NIO
Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
在linux中的Java进程中,默认情况下所有的socket都是blocking IO。在阻塞式 I/O 模型中,应用程序在从IO系统调用开始,一直到到系统调用返回,这段时间是阻塞的。返回成功后,应用进程开始处理用户空间的缓存数据。
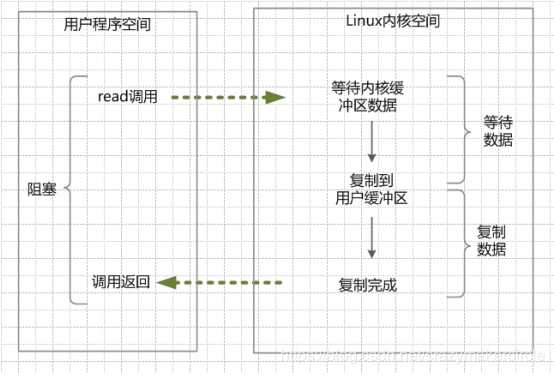
举个例子,发起一个blocking socket的read读操作系统调用,流程大概是这样:
(1)当用户线程调用了read系统调用,内核(kernel)就开始了IO的第一个阶段:准备数据。很多时候,数据在一开始还没有到达(比如,还没有收到一个完整的Socket数据包),这个时候kernel就要等待足够的数据到来。
(2)当kernel一直等到数据准备好了,它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)从开始IO读的read系统调用开始,用户线程就进入阻塞状态。一直到kernel返回结果后,用户线程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在内核进行IO执行的两个阶段,用户线程都被block了。
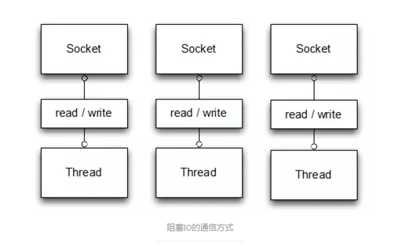
传统阻塞型 I/O(BIO)可以用下图表示(对应程序实现):
1 public class SocketServer { 2 public static void main(String[] args) { 3 try { 4 // 创建服务端socket 5 ServerSocket serverSocket = new ServerSocket(8088); 6 7 // 创建客户端socket 8 //循环监听等待客户端的连接 9 while(true){ 10 // 监听客户端 11 Socket socket = serverSocket.accept(); 12 //每连接一个客户端,便启用一个线程去读写数据 13 ServerRevice serverRevice = new ServerRevice(socket); 14 Thread thread = new Thread(serverRevice); 15 thread.start(); 16 } 17 } catch (Exception e) { 18 e.printStackTrace(); 19 } 20 } 21 }
特点如下:
每个请求都有独立的线程完成数据 Read,业务处理,数据 Write 的完整操作问题。
连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费。
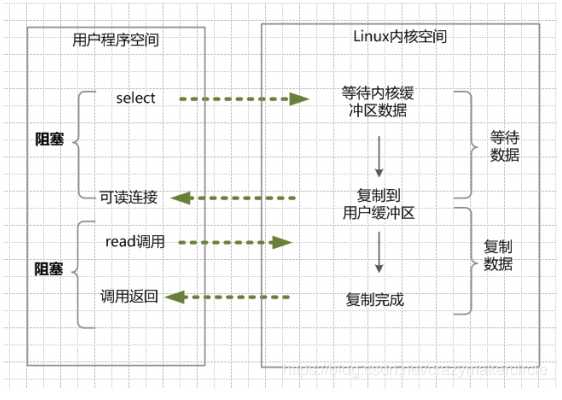
在这种模式中,首先不是进行read系统调动,而是进行select/epoll系统调用。当然,这里有一个前提,需要将目标网络连接,提前注册到select/epoll的可查询socket列表中。然后,才可以开启整个的IO多路复用模型的读流程。
(1)进行select/epoll系统调用,查询可以读的连接。kernel会查询所有select的可查询socket列表,当任何一个socket中的数据准备好了,select就会返回。
当用户进程调用了select,那么整个线程会被block(阻塞掉)。
(2)用户线程获得了目标连接后,发起read系统调用,用户线程阻塞。内核开始复制数据。它就会将数据从kernel内核缓冲区,拷贝到用户缓冲区(用户内存),然后kernel返回结果。
(3)用户线程才解除block的状态,用户线程终于真正读取到数据,继续执行
以下根据图,作一个简单的代码实现例子
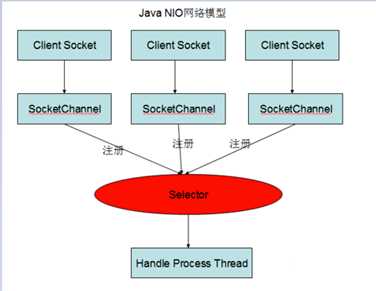
代码示例
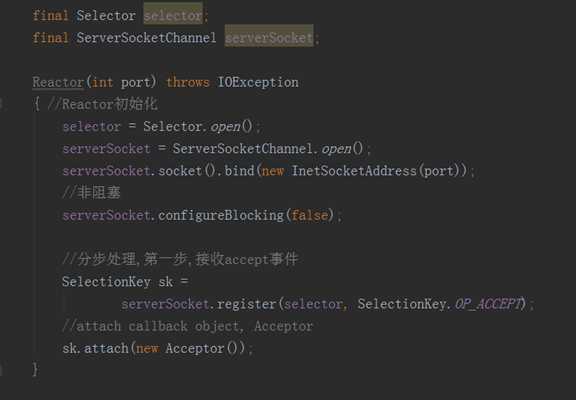
“Scalable IO in Java”,实现了一个单线程Reactor的参考代码,Reactor的代码如下:
Reactor
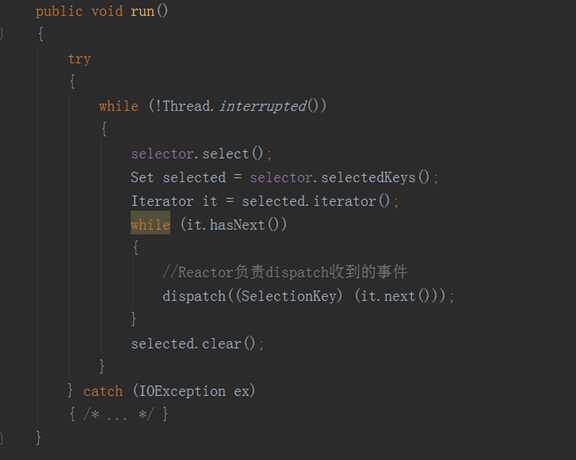
run()方法使用selcet()方法,循环遍历是否有准备就绪的连接
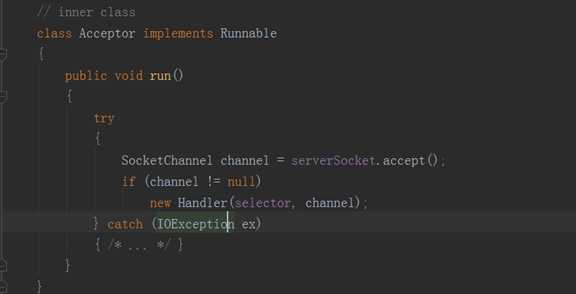
Acceptor
Handler:将连接注册到selector选择器中
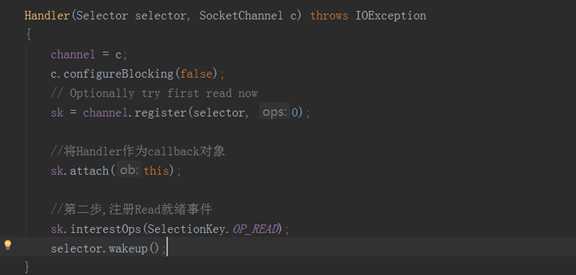
多路复用IO的优点:
每次获取数据前。先使用select()方法,它可以同时处理成千上万个连接(connection)。与一条线程维护一个连接相比,I/O多路复用技术的最大优势是:系统不必创建线程,也不必维护这些线程,从而大大减小了系统的开销。
原文:https://www.cnblogs.com/MacrossFT/p/12110817.html