。
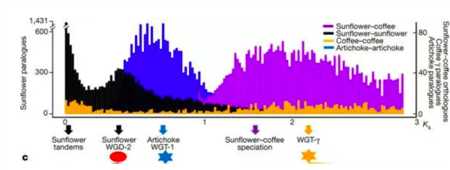
这个明显的痕迹就是向日葵独有的全基因组二倍化事件WGD-2留下的痕迹,当然其实还有很多,眼力好的同学可以自己连连看一下。那么前两次WGT留下的痕迹呢?全基因组加倍事件可以一次性增加一个物种所有的基因拷贝,在自然选择的作用下,倍增后的基因经历不同的命运:部分拷贝丢失,失去功能(假基因化);部分拷贝获得新的功能(新功能化);或者各自行使祖先基因的部分功能(亚功能化)
-
同义突变率ks
这是比较流行的方法。这种方法的背景是认为Ks值在某种程度上反映了同源基因的产生时间。而全基因组加倍事件会产生大量的同源基因,反映在Ks值上便是会有大量的Ks值接近的同源基因对的产生,这样通过绘制Ks值的分布图便可以发现明显的Ks值峰,而这些峰也就对应了全基因组加倍事件。这种方法是基于两点假设:1.基因的突变频率是稳定的;2.同义突变(Ks)不会影响物种适应性,因为并不会造成氨基酸序列的变化。
举个简单的例子,如果我们要进行人口调查,研究哪一年是生育高峰,我们不需要回去查医院的出生记录(或者根本没有),只需要调查现在的人口年龄构成,就可以看出哪个年龄是有一个高峰,那么那个年龄的人出生的年份,就是生育高峰。甚至,假如被调查的人都忘记了自己的年龄(一个很大的假如,可以认为是集体失忆造成的),我们都可以通过脸上的皱纹、头发的稀疏等外部特征来推断被调查人的年龄。如果是这样的话,我们同样是基于两点假设:1.皱纹的增长,头发的脱落是稳定的;2.皱纹和头发并不会影响死亡率。
言归正传,要进行Ks分析,首先要找到同源基因对,在不同的物种里面(比如向日葵-咖啡),是找最近的直系同源基因(ortholog),而在基因组内部(比如向日葵-向日葵),则是找最近的旁系同源基因(paralog)。通过计算这些基因的Ks值,我们就可以绘制出不同Ks值基因数量的分布图。