普通的Hadoop集群,虽然有FsImage,Editslog和SecondaryNameNode机制,来防止Namenode节点宕机或非正常的服务关闭时数据的丢失,但是有一个问题依然存在,那就是身为HDFS文件系统的总入口,
停止了对外的服务。对于客户端来说,系统内部是透明的,当服务宕机后,客户并不懂原由,有可能认为是自己的问题或者我们服务的问题。
为解决服务宕机的问题,引入了HA(high avaliable)机构的Hadoop集群,该集群可以保持服务 7x24 不间断服务。
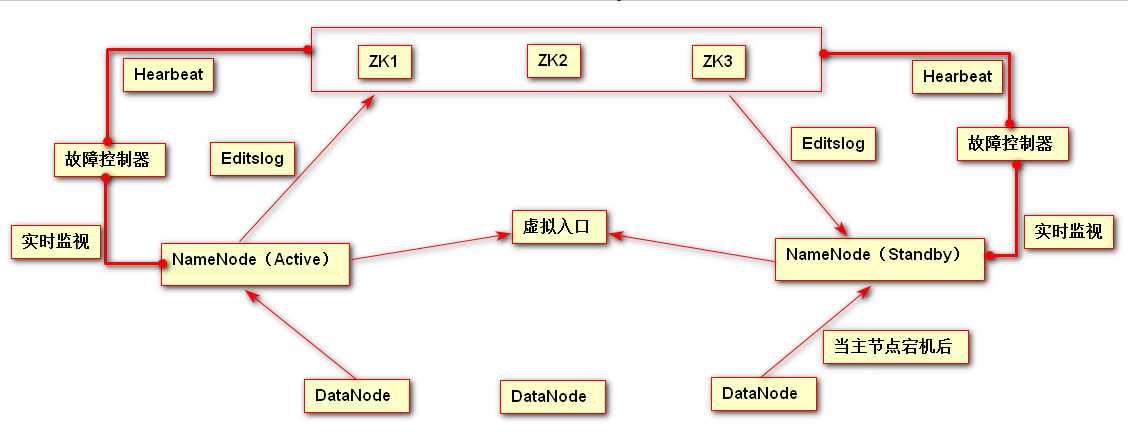
zookeeper原理:zookeeper搭建集群,以选举的方式选择主节点,永远都会有主节点对外服务。 ##要求:zookeeper的节点个数必须为奇数个。 ##选取算法:ZDA算法
zookeeper职责: 1.选主;2.自动故障转移;3.日志同步 journalnode
1.准备工作
环境:VMware 15.0虚拟机;CentOS 6.5 Linux系统
准备好三台虚拟机,并且每台虚拟机都需要做好基础配置,配置如下:ip地址 主机名 主机映射 防火墙 selinux jdk ssh免密码登陆 ,详细配置见我的前一篇博客,链接见下面。
https://www.cnblogs.com/cmxbky1314/p/12096177.html
2.搭建zookeeper集群
①.上传zookeeper的tar包,然后解压缩到 /opt/install (该目录为自己所建,用来安装集群相关的软件)
②.在zookeeper根目录下,创建data文件夹,用来存储数据
③.cd到zookeeper目录下的conf文件夹中,将此文件 zoo_sample.cfg 改名为 zoo.cfg (最好使用cp命令,复制一份),然后修改文件,内容如下:
1 #datadir是刚才创建的data文件夹路径 2 dataDir=/opt/install/zookeeper-3.4.5/data 3 4 #在文件最后添加如下代码 5 server.0=cmx001.ai179.com:2888:3888 6 server.1=cmx002.ai179.com:2888:3888 7 server.2=cmx003.ai179.com:2888:3888
④.然后在创建的data文件夹下,创建myid文件里面写上 编号:0. ###编号需要与上面的配置文件配对
⑤.之后再将配置好的zookeeper 拷贝到其他俩台虚拟机上去,scp -r zookeeper root@hostname:/opt/install/
然后修改每台虚拟机的myid文件
⑥.最后启动zookeeper集群 命令:zookeeper_home/bin/zkServer.sh start,若是启动成功后无问题 第二台虚拟机的状态(bin/zkServer.sh status) 应该为leader,其余俩台为follower
###进入zookeeper客户端命令:bin/zkCli.sh
3.搭建Hadoop集群
借用之前配置好的配置文件,修改如下几个文件,其他文件见上面博客链接
①.core-site.xml
1 <property> 2 <name>fs.default.name</name> 3 <value>hdfs://ns</value> 4 </property> 5 <property> 6 <name>hadoop.tmp.dir</name> 7 <value>/opt/install/hadoop-2.5.2/data/tmp</value> 8 </property> 9 <property> 10 <name>ha.zookeeper.quorum</name> 11 <value>cmx002.ai179.com:2181,cmx003.ai179.com:2181,cmx004.ai179.com:2181</value> 12 </property>
②.hdfs-site.xml
1 <property> 2 <name>dfs.permissions.enabled</name> 3 <value>false</value> 4 </property> 5 <!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --> 6 <property> 7 <name>dfs.nameservices</name> 8 <value>ns</value> 9 </property> 10 <!-- ns下面有两个NameNode,分别是nn1,nn2 --> 11 <property> 12 <name>dfs.ha.namenodes.ns</name> 13 <value>nn1,nn2</value> 14 </property> 15 <!-- nn1的RPC通信地址 --> 16 <property> 17 <name>dfs.namenode.rpc-address.ns.nn1</name> 18 <value>cmx002.ai179.com:8020</value> 19 </property> 20 <!-- nn1的http通信地址 --> 21 <property> 22 <name>dfs.namenode.http-address.ns.nn1</name> 23 <value>cmx002.ai179.com:50070</value> 24 </property> 25 <!-- nn2的RPC通信地址 --> 26 <property> 27 <name>dfs.namenode.rpc-address.ns.nn2</name> 28 <value>cmx003.ai179.com:8020</value> 29 </property> 30 <!-- nn2的http通信地址 --> 31 <property> 32 <name>dfs.namenode.http-address.ns.nn2</name> 33 <value>cmx003.ai179.com:50070</value> 34 </property> 35 36 <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> 37 <property> 38 <name>dfs.namenode.shared.edits.dir</name> 39 <value>qjournal://cmx002.ai179.com:8485;cmx003.ai179.com:8485;cmx004.ai179.com:8485/ns</value> 40 </property> 41 <!-- 指定JournalNode在本地磁盘存放数据的位置 --> 42 <property> 43 <name>dfs.journalnode.edits.dir</name> 44 <value>/opt/install/hadoop-2.5.2/journal</value> 45 </property> 46 <!-- 开启NameNode故障时自动切换 --> 47 <property> 48 <name>dfs.ha.automatic-failover.enabled</name> 49 <value>true</value> 50 </property> 51 <!-- 配置失败自动切换实现方式 --> 52 <property> 53 <name>dfs.client.failover.proxy.provider.ns</name> 54 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 55 </property> 56 <!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 --> 57 <property> 58 <name>dfs.ha.fencing.methods</name> 59 <value>sshfence</value> 60 </property> 61 <!-- 使用隔离机制时需要ssh免登陆 --> 62 <property> 63 <name>dfs.ha.fencing.ssh.private-key-files</name> 64 <value>/root/.ssh/id_rsa</value> 65 </property>
4.初次启动
1.保证每一台虚拟机的zookeeper都启动成功,且检测无问题
2.安装如下操作:
1 在某一个namenode节点执行如下命令,创建命名空间 2 bin/hdfs zkfc -formatZK 3 4 在每个journalnode节点用如下命令启动journalnode 5 sbin/hadoop-daemon.sh start journalnode 6 7 在主namenode节点格式化namenode和journalnode目录 8 bin/hdfs namenode -format ns 9 10 在主namenode节点启动namenode进程 11 sbin/hadoop-daemon.sh start namenode 12 13 在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程! 14 15 bin/hdfs namenode -bootstrapStandby 16 sbin/hadoop-daemon.sh start namenode 17 18 在两个namenode节点都执行以下命令 19 sbin/hadoop-daemon.sh start zkfc 20 21 在所有datanode节点都执行以下命令启动datanode 22 sbin/hadoop-daemon.sh start datanode
###
配置好以后,依然可以用 sbin/start-dfs.sh sbin/stop-dfs.sh 启动和停止
5.检测集群
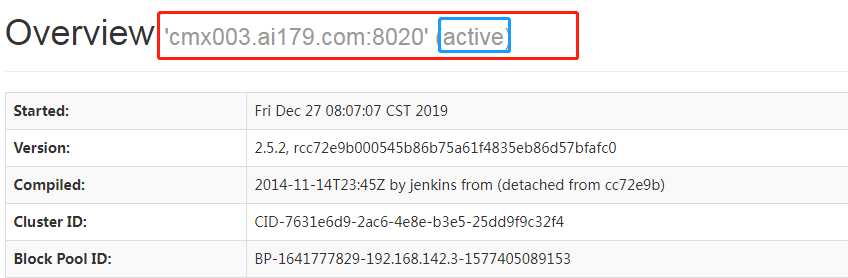
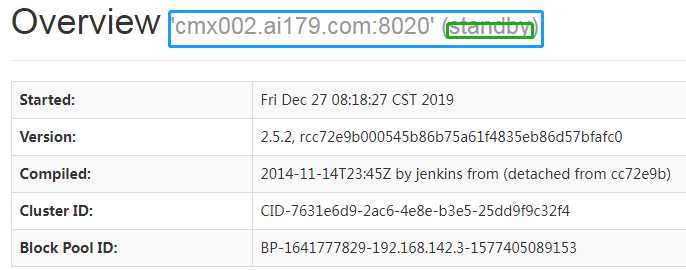
在Windows下的hosts文件做好映射,然后访问http://cmx003.ai179.com:50070;http://cmx002.ai179.com:50070。###注:我这个是删除namenode后的测试结果
你可以用jps,查看namenode的进程pid,将其杀死,然后再通过命令sbin/hadoop-daemon.sh start namenode 启动它,你会发现该节点有主节点,变为了备节点,就是下面的结果。
结果如下:
原文:https://www.cnblogs.com/cmxbky1314/p/12115756.html