深度学习技术一直在发展,但是caffe的更新跟不上进度,也许是维护团队的关系:CAFFE团队成员都是业余时间在维护和更新。导致的结果就是很多新的技术在caffe里用不了,比如RNN, LSTM,batch-norm等。当然这些现在也算是旧的东西了,也许caffe已经有了,我已经很久没有关注caffe的新版本了。它的不灵活之处就是新的东西很难自己扩展,只能等版本更新,这就比较尴尬。
因此,只学caffe一个工具看来是不行了,还得学习其它工具。该学什么呢?当然是如日中天的tensorflow了,毕竟它背后的团队很强大,功能也比较齐全,更新也很及时。所谓技多不压身,学了caffe后再学tensorflow,两者结合着用。
关于tensorflow的介绍,此处不再啰嗦。关于gpu的安装与配置,此处也不涉及。
一、安装anaconda
tensorflow是基于python脚本语言的,因此需要安装python, 当然还需要安装numpy、scipy、six、matplotlib等几十个扩展包。如果一个个安装,装到啥时候去?(我曾经光安装scipy就装了一天。。。)
不过现在有了集成环境anaconda,安装就方便了。python的大部分扩展包, 都集成在anaconda里面了,因此只需要装这一个东西就行了。
先到https://www.continuum.io/downloads 下载anaconda, 现在的版本有python2.7版本和python3.5版本,下载好对应版本、对应系统的anaconda,它实际上是一个sh脚本文件,大约300M-400M左右。推荐使用linux版的python 2.7版本,因为tensorflow中的有些东西不支持python3.5(如cPickle)。
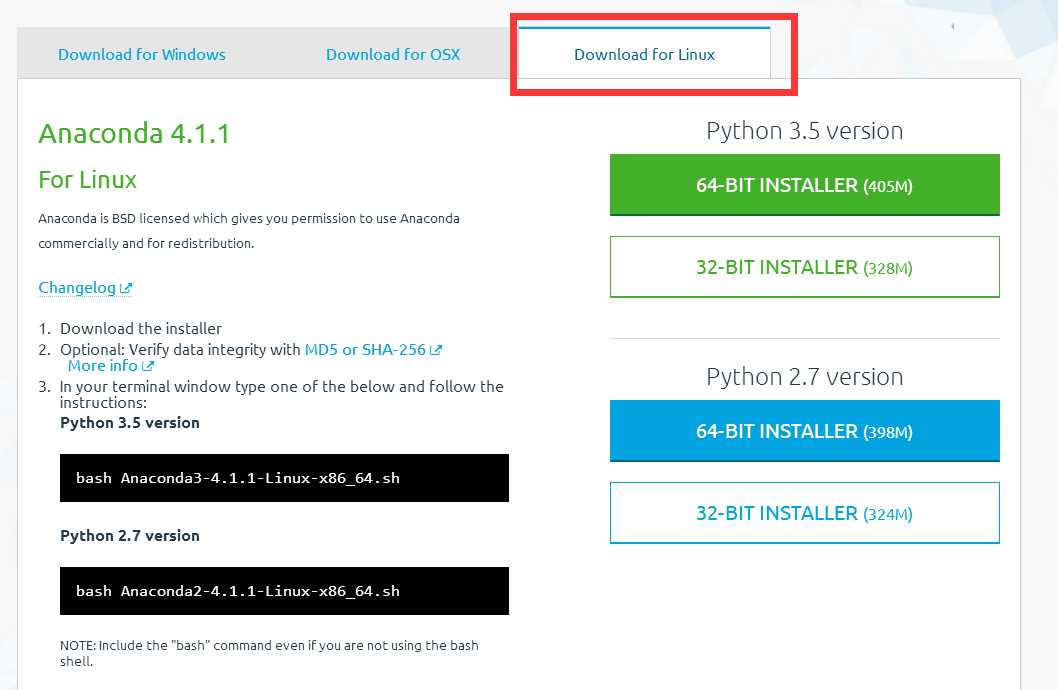
下载成功后,在终端执行(2.7版本):
# bash Anaconda2-4.1.1-Linux-x86_64.sh
或者3.5 版本:
# bash Anaconda3-4.1.1-Linux-x86_64.sh
在安装的过程中,会问你安装路径,直接回车默认就可以了。有个地方问你是否将anaconda安装路径加入到环境变量(.bashrc)中,这个一定要输入yes
安装成功后,会有当前用户根目录下生成一个anaconda2的文件夹,里面就是安装好的内容。在终端可以输入
conda info 来查询安装信息
输入conda list 可以查询你现在安装了哪些库,常用的python, numpy, scipy名列其中。如果你还有什么包没有安装上,可以运行
conda install *** 来进行安装(***代表包名称),如果某个包版本不是最新的,运行 conda update *** 就可以了。
二、安装tensorflow
先在终端执行:
anaconda search -t conda tensorflow
搜索一下有哪些tensorflow安装包,通过查看版本,选择最高的版本安装。比如我看到是0.10.0rc0版本是最高的,如下图:
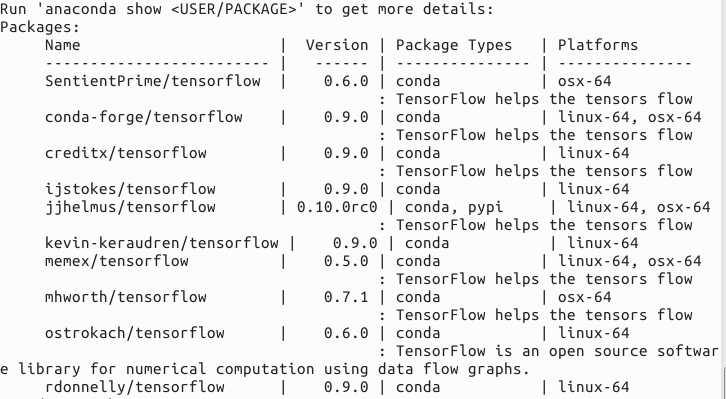
因此,执行下面代码来查看详细信息:
anaconda show jjhelmus/tensorflow
它就会告诉你,怎么来安装这个包,在终端执行:
conda install --channel https://conda.anaconda.org/jjhelmus tensorflow
然后输入"y",进行安装。
三、调试
安装成功与否,我们可以测试一下。
在终端输入python,进入python编译环境,然后输入:
import tensorflow as tf
引包tensorflow包,如果没有报错,则安装成功,否则就有问题。
然后可以输入
tf.__version__ tf.__path__
查看tensorflow的安装版本和安装路径(左右各两根下横线)。
二、tensorflow学习笔记二:入门基础
TensorFlow用张量这种数据结构来表示所有的数据。用一阶张量来表示向量,如:v = [1.2, 2.3, 3.5] ,如二阶张量表示矩阵,如:m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]],可以看成是方括号嵌套的层数。
1、编辑器
编写tensorflow代码,实际上就是编写py文件,最好找一个好用的编辑器,如果你用vim或gedit比较顺手,那也可以的啦。我们既然已经安装了anaconda,那么它里面自带一个还算不错的编辑器,名叫spyder,用起来和matlab差不多,还可以在右上角查看变量的值。因此我一直使用这个编辑器。它的启动方式也很简单,直接在终端输入spyder就行了。
2、常量
我们一般引入tensorflow都用语句
import tensorflow as tf
因此,以后文章中我就直接用tf来表示tensorflow了。
在tf中,常量的定义用语句:
a=tf.constant(10)
这就定义了一个值为10的常量a
3、变量
变量用Variable来定义, 并且必须初始化,如:
x=tf.Variable(tf.ones([3,3])) y=tf.Variable(tf.zeros([3,3]))
分别定义了一个3x3的全1矩阵x,和一个3x3的全0矩阵y,0和1的值就是初始化。
变量定义完后,还必须显式的执行一下初始化操作,即需要在后面加上一句:
init=tf.global_variables_initializer()
这句可不要忘了,否则会出错。
例:自定义一个拉普拉斯的W变量:
import tensorflow as tf import numpy as np x=np.array([[1,1,1],[1,-8,1],[1,1,1]]) w=tf.Variable(initial_value=x) sess=tf.Session() sess.run(tf.global_variables_initializer()) print(sess.run(w))
4、占位符
变量在定义时要初始化,但是如果有些变量刚开始我们并不知道它们的值,无法初始化,那怎么办呢?
那就用占位符来占个位置,如:
x = tf.placeholder(tf.float32, [None, 784])
指定这个变量的类型和shape,以后再用feed的方式来输入值。
5、图(graph)
如果把下面的python语句改在tf语句,该怎么写呢:
x=3 y=2 z=x+y print(z)
定义两个变量,并将两个数相加,输出结果。如果在tf中直接像上面这样写,那就错了。x,y,z分别是三个tensor对象,对象间的运算称之为操作(op), tf不会去一条条地执行各个操作,而是把所有的操作都放入到一个图(graph)中,图中的每一个结点就是一个操作。然后行将整个graph 的计算过程交给一个 TensorFlow 的Session, 此 Session 可以运行整个计算过程,比起操作(operations)一条一条的执行效率高的多。
执行代码如下:
import tensorflow as tf x = tf.Variable(3) y = tf.Variable(5) z=x+y init =tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(z))
其中sess.run()即是执行,注意要先执行变量初始化操作,再执行运算操作。
Session需要先创建,使用完后还需要释放。因此我们使用with...as..语句,让系统自动释放。
例子1:hello world
import tensorflow as tf
word=tf.constant(‘hello,world!‘)
with tf.Session() as sess:
print(sess.run(word))
例子2:加法和乘法
import tensorflow as tf
a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
add = tf.add(a, b)
mul = tf.mul(a, b)
with tf.Session() as sess:
print(‘a+b=‘,sess.run(add, feed_dict={a: 2, b: 3}))
print(‘a*b=‘,sess.run(mul, feed_dict={a: 2, b: 3}))
此处使用feed_dict以字典的方式对多个变量输入值。
例子3: 矩阵乘法
import tensorflow as tf
a=tf.Variable(tf.ones([3,2]))
b=tf.Variable(tf.ones([2,3]))
product=tf.matmul(5*a,4*b)
init=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print(sess.run(product))
其中
product=tf.matmul(5*a,4*b)
也可以改成
product=tf.matmul(tf.mul(5.0,a),tf.mul(4.0,b))
定义变量时,没有指定数据类型,则默认为float32,因此是5.0而不是5
三、tensorflow学习笔记三:实例数据下载与读取
一、mnist数据
深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集。
tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们直接调用就可以了,代码如下:
import tensorflow.examples.tutorials.mnist.input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
执行完成后,会在当前目录下新建一个文件夹MNIST_data, 下载的数据将放入这个文件夹内。下载的四个文件为:
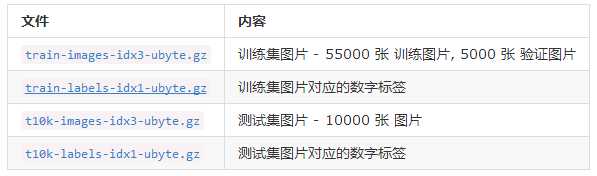
input_data文件会调用一个maybe_download函数,确保数据下载成功。这个函数还会判断数据是否已经下载,如果已经下载好了,就不再重复下载。
下载下来的数据集被分三个子集:5.5W行的训练数据集(mnist.train),5千行的验证数据集(mnist.validation)和1W行的测试数据集(mnist.test)。因为每张图片为28x28的黑白图片,所以每行为784维的向量。
每个子集都由两部分组成:图片部分(images)和标签部分(labels), 我们可以用下面的代码来查看 :
print mnist.train.images.shape print mnist.train.labels.shape print mnist.validation.images.shape print mnist.validation.labels.shape print mnist.test.images.shape print mnist.test.labels.shape
如果想在spyder编辑器中查看具体数值,可以将这些数据提取为变量来查看,如:
val_data=mnist.validation.images
val_label=mnist.validation.labels
二、CSV数据
除了mnist手写字体图片数据,tf还提供了几个csv的数据供大家练习,存放路径为:
/home/xxx/anaconda3/lib/python3.5/site-packages/tensorflow/contrib/learn/python/learn/datasets/data/text_train.csv
如果要将这些数据读出来,可用代码:
import tensorflow.contrib.learn.python.learn.datasets.base as base iris_data,iris_label=base.load_iris() house_data,house_label=base.load_boston()
前者为iris鸢尾花卉数据集,后者为波士顿房价数据。
三、cifar10数据
tf提供了cifar10数据的下载和读取的函数,我们直接调用就可以了。执行下列代码:
import tensorflow.models.image.cifar10.cifar10 as cifar10 cifar10.maybe_download_and_extract() images, labels = cifar10.distorted_inputs() print images print labels
就可以将cifar10下载并读取出来。
四、tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
刚开始学习tf时,我们从简单的地方开始。卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始。
神经网络没有卷积功能,只有简单的三层:输入层,隐藏层和输出层。
数据从输入层输入,在隐藏层进行加权变换,最后在输出层进行输出。输出的时候,我们可以使用softmax回归,输出属于每个类别的概率值。借用极客学院的图表示如下:
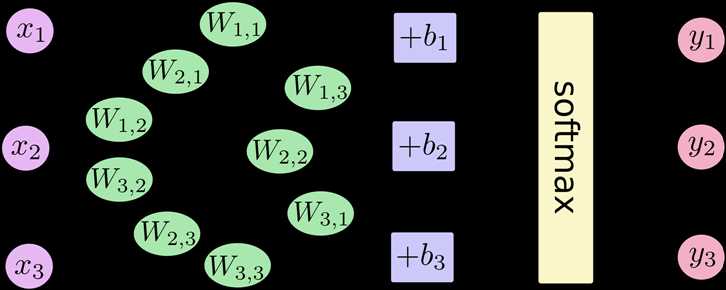
其中,x1,x2,x3为输入数据,经过运算后,得到三个数据属于某个类别的概率值y1,y2,y3. 用简单的公式表示如下:
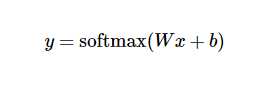
在训练过程中,我们将真实的结果和预测的结果相比(交叉熵比较法),会得到一个残差。公式如下:
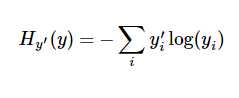
y 是我们预测的概率值, y‘ 是实际的值。这个残差越小越好,我们可以使用梯度下降法,不停地改变W和b的值,使得残差逐渐变小,最后收敛到最小值。这样训练就完成了,我们就得到了一个模型(W和b的最优化值)。
完整代码如下:
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
y_actual = tf.placeholder(tf.float32, shape=[None, 10])
W = tf.Variable(tf.zeros([784,10])) #初始化权值W
b = tf.Variable(tf.zeros([10])) #初始化偏置项b
y_predict = tf.nn.softmax(tf.matmul(x,W) + b) #加权变换并进行softmax回归,得到预测概率
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_actual*tf.log(y_predict),reduction_indies=1)) #求交叉熵
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) #用梯度下降法使得残差最小
correct_prediction = tf.equal(tf.argmax(y_predict,1), tf.argmax(y_actual,1)) #在测试阶段,测试准确度计算
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #多个批次的准确度均值
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
for i in range(1000): #训练阶段,迭代1000次
batch_xs, batch_ys = mnist.train.next_batch(100) #按批次训练,每批100行数据
sess.run(train_step, feed_dict={x: batch_xs, y_actual: batch_ys}) #执行训练
if(i%100==0): #每训练100次,测试一次
print "accuracy:",sess.run(accuracy, feed_dict={x: mnist.test.images, y_actual: mnist.test.labels})
每训练100次,测试一次,随着训练次数的增加,测试精度也在增加。训练结束后,1W行数据测试的平均精度为91%左右,不是太高,肯定没有CNN高。
五、tensorflow学习笔记五:mnist实例--卷积神经网络(CNN)
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的。但是CNN层数要多一些,网络模型需要自己来构建。
程序比较复杂,我就分成几个部分来叙述。
首先,下载并加载数据:
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #下载并加载mnist数据
x = tf.placeholder(tf.float32, [None, 784]) #输入的数据占位符
y_actual = tf.placeholder(tf.float32, shape=[None, 10]) #输入的标签占位符
定义四个函数,分别用于初始化权值W,初始化偏置项b, 构建卷积层和构建池化层。
#定义一个函数,用于初始化所有的权值 W def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) #定义一个函数,用于初始化所有的偏置项 b def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) #定义一个函数,用于构建卷积层 def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME‘) #定义一个函数,用于构建池化层 def max_pool(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding=‘SAME‘)
接下来构建网络。整个网络由两个卷积层(包含激活层和池化层),一个全连接层,一个dropout层和一个softmax层组成。
#构建网络
x_image = tf.reshape(x, [-1,28,28,1]) #转换输入数据shape,以便于用于网络中
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #第一个卷积层
h_pool1 = max_pool(h_conv1) #第一个池化层
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) #第二个卷积层
h_pool2 = max_pool(h_conv2) #第二个池化层
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) #reshape成向量
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) #第一个全连接层
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) #dropout层
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_predict=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #softmax层
网络构建好后,就可以开始训练了。
cross_entropy = -tf.reduce_sum(y_actual*tf.log(y_predict)) #交叉熵
train_step = tf.train.GradientDescentOptimizer(1e-3).minimize(cross_entropy) #梯度下降法
correct_prediction = tf.equal(tf.argmax(y_predict,1), tf.argmax(y_actual,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #精确度计算
sess=tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0: #训练100次,验证一次
train_acc = accuracy.eval(feed_dict={x:batch[0], y_actual: batch[1], keep_prob: 1.0})
print ‘step %d, training accuracy %g‘%(i,train_acc)
train_step.run(feed_dict={x: batch[0], y_actual: batch[1], keep_prob: 0.5})
test_acc=accuracy.eval(feed_dict={x: mnist.test.images, y_actual: mnist.test.labels, keep_prob: 1.0})
print "test accuracy %g"%test_acc
Tensorflow依赖于一个高效的C++后端来进行计算。与后端的这个连接叫做session。一般而言,使用TensorFlow程序的流程是先创建一个图,然后在session中启动它。
这里,我们使用更加方便的InteractiveSession类。通过它,你可以更加灵活地构建你的代码。它能让你在运行图的时候,插入一些计算图,这些计算图是由某些操作(operations)构成的。这对于工作在交互式环境中的人们来说非常便利,比如使用IPython。
训练20000次后,再进行测试,测试精度可以达到99%。
完整代码:
# -*- coding: utf-8 -*- """ Created on Thu Sep 8 15:29:48 2016 @author: root """ import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #下载并加载mnist数据 x = tf.placeholder(tf.float32, [None, 784]) #输入的数据占位符 y_actual = tf.placeholder(tf.float32, shape=[None, 10]) #输入的标签占位符 #定义一个函数,用于初始化所有的权值 W def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) #定义一个函数,用于初始化所有的偏置项 b def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) #定义一个函数,用于构建卷积层 def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME‘) #定义一个函数,用于构建池化层 def max_pool(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding=‘SAME‘) #构建网络 x_image = tf.reshape(x, [-1,28,28,1]) #转换输入数据shape,以便于用于网络中 W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #第一个卷积层 h_pool1 = max_pool(h_conv1) #第一个池化层 W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) #第二个卷积层 h_pool2 = max_pool(h_conv2) #第二个池化层 W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) #reshape成向量 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) #第一个全连接层 keep_prob = tf.placeholder("float") h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) #dropout层 W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_predict=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #softmax层 cross_entropy = -tf.reduce_sum(y_actual*tf.log(y_predict)) #交叉熵 train_step = tf.train.GradientDescentOptimizer(1e-3).minimize(cross_entropy) #梯度下降法 correct_prediction = tf.equal(tf.argmax(y_predict,1), tf.argmax(y_actual,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #精确度计算 sess=tf.InteractiveSession() sess.run(tf.initialize_all_variables()) for i in range(20000): batch = mnist.train.next_batch(50) if i%100 == 0: #训练100次,验证一次 train_acc = accuracy.eval(feed_dict={x:batch[0], y_actual: batch[1], keep_prob: 1.0}) print(‘step‘,i,‘training accuracy‘,train_acc) train_step.run(feed_dict={x: batch[0], y_actual: batch[1], keep_prob: 0.5}) test_acc=accuracy.eval(feed_dict={x: mnist.test.images, y_actual: mnist.test.labels, keep_prob: 1.0}) print("test accuracy",test_acc)
六、tensorflow 1.0 学习:用CNN进行图像分类
tensorflow升级到1.0之后,增加了一些高级模块: 如tf.layers, tf.metrics, 和tf.losses,使得代码稍微有些简化。
任务:花卉分类
版本:tensorflow 1.0
数据:http://download.tensorflow.org/example_images/flower_photos.tgz
花总共有五类,分别放在5个文件夹下。
闲话不多说,直接上代码,希望大家能看懂:)
# -*- coding: utf-8 -*-
from skimage import io,transform
import glob
import os
import tensorflow as tf
import numpy as np
import time
path=‘e:/flower/‘
#将所有的图片resize成100*100
w=100
h=100
c=3
#读取图片
def read_img(path):
cate=[path+x for x in os.listdir(path) if os.path.isdir(path+x)]
imgs=[]
labels=[]
for idx,folder in enumerate(cate):
for im in glob.glob(folder+‘/*.jpg‘):
print(‘reading the images:%s‘%(im))
img=io.imread(im)
img=transform.resize(img,(w,h))
imgs.append(img)
labels.append(idx)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
data,label=read_img(path)
#打乱顺序
num_example=data.shape[0]
arr=np.arange(num_example)
np.random.shuffle(arr)
data=data[arr]
label=label[arr]
#将所有数据分为训练集和验证集
ratio=0.8
s=np.int(num_example*ratio)
x_train=data[:s]
y_train=label[:s]
x_val=data[s:]
y_val=label[s:]
#-----------------构建网络----------------------
#占位符
x=tf.placeholder(tf.float32,shape=[None,w,h,c],name=‘x‘)
y_=tf.placeholder(tf.int32,shape=[None,],name=‘y_‘)
#第一个卷积层(100——>50)
conv1=tf.layers.conv2d(
inputs=x,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool1=tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
#第二个卷积层(50->25)
conv2=tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool2=tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
#第三个卷积层(25->12)
conv3=tf.layers.conv2d(
inputs=pool2,
filters=128,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool3=tf.layers.max_pooling2d(inputs=conv3, pool_size=[2, 2], strides=2)
#第四个卷积层(12->6)
conv4=tf.layers.conv2d(
inputs=pool3,
filters=128,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool4=tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=2)
re1 = tf.reshape(pool4, [-1, 6 * 6 * 128])
#全连接层
dense1 = tf.layers.dense(inputs=re1,
units=1024,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
dense2= tf.layers.dense(inputs=dense1,
units=512,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
logits= tf.layers.dense(inputs=dense2,
units=5,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
#---------------------------网络结束---------------------------
loss=tf.losses.sparse_softmax_cross_entropy(labels=y_,logits=logits)
train_op=tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(logits,1),tf.int32), y_)
acc= tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#定义一个函数,按批次取数据
def minibatches(inputs=None, targets=None, batch_size=None, shuffle=False):
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt]
#训练和测试数据,可将n_epoch设置更大一些
n_epoch=10
batch_size=64
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
for epoch in range(n_epoch):
start_time = time.time()
#training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True):
_,err,ac=sess.run([train_op,loss,acc], feed_dict={x: x_train_a, y_: y_train_a})
train_loss += err; train_acc += ac; n_batch += 1
print(" train loss: %f" % (train_loss/ n_batch))
print(" train acc: %f" % (train_acc/ n_batch))
#validation
val_loss, val_acc, n_batch = 0, 0, 0
for x_val_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):
err, ac = sess.run([loss,acc], feed_dict={x: x_val_a, y_: y_val_a})
val_loss += err; val_acc += ac; n_batch += 1
print(" validation loss: %f" % (val_loss/ n_batch))
print(" validation acc: %f" % (val_acc/ n_batch))
sess.close()
七、tensorflow 1.0 学习:卷积层
在tf1.0中,对卷积层重新进行了封装,比原来版本的卷积层有了很大的简化。
一、旧版本(1.0以下)的卷积函数:tf.nn.conv2d
conv2d(
input,
filter,
strides,
padding,
use_cudnn_on_gpu=None,
data_format=None,
name=None
)
该函数定义在tensorflow/python/ops/gen_nn_ops.py。
参数:
input:一个4维Tensor(N,H,W,C). 类型必须是以下几种类型之一:half,float32,float64.filter:卷积核. 类型和input必须相同,4维tensor,[filter_height, filter_width, in_channels, out_channels],如[5,5,3,32]strides: 在input上切片采样时,每个方向上的滑窗步长,必须和format指定的维度同阶,如[1, 2, 2, 1]padding: 指定边缘填充类型:"SAME", "VALID". SAME表示卷积后图片保持不变,VALID则会缩小。use_cudnn_on_gpu: 可选项,bool型。表示是否在GPU上用cudnn进行加速,默认为True.data_format: 可选项,指定输入数据的格式:"NHWC"或 "NCHW", 默认为"NHWC"。
NHWC格式指[batch, in_height, in_width, in_channels]
NCHW格式指[batch, in_channels, in_height, in_width]name: 操作名,可选.
示例:
conv1=tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME‘)
二、1.0版本中的卷积函数:tf.layers.conv2d
conv2d(
inputs,
filters,
kernel_size,
strides=(1, 1),
padding=‘valid‘,
data_format=‘channels_last‘,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
trainable=True,
name=None,
reuse=None
)
定义在tensorflow/python/layers/convolutional.py.
参数多了很多,但实际用起来,却更简单。
inputs: 输入数据,4维tensor.filters: 卷积核个数。kernel_size:卷积核大小,如【5,5】。如果长宽相等,也可以直接设置为一个数,如kernel_size=5strides: 卷积过程中的滑动步长,默认为[1,1]. 也可以直接设置为一个数,如strides=2padding: 边缘填充,‘same‘ 和‘valid‘选其一。默认为valid-
data_format: 输入数据格式,默认为channels_last,即(batch, height, width, channels),也可以设置为channels_first对应(batch, channels, height, width). -
dilation_rate: 微步长卷积,这个比较复杂一些,请百度. activation: 激活函数.use_bias: Boolean型,是否使用偏置项.kernel_initializer: 卷积核的初始化器.bias_initializer: 偏置项的初始化器,默认初始化为0.kernel_regularizer: 卷积核化的正则化,可选.bias_regularizer: 偏置项的正则化,可选.activity_regularizer: 输出的正则化函数.trainable: Boolean型,表明该层的参数是否参与训练。如果为真则变量加入到图集合中GraphKeys.TRAINABLE_VARIABLES(seetf.Variable).name: 层的名字.reuse: Boolean型, 是否重复使用参数.
示例:
conv1=tf.layers.conv2d(
inputs=x,
filters=32,
kernel_size=5,
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.TruncatedNormal(stddev=0.01))
更复杂一点的:
conv1 = tf.layers.conv2d(batch_images,
filters=64,
kernel_size=7,
strides=2,
activation=tf.nn.relu,
kernel_initializer=tf.TruncatedNormal(stddev=0.01)
bias_initializer=tf.Constant(0.1),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003),
bias_regularizer=tf.contrib.layers.l2_regularizer(0.003),
name=‘conv1‘)
八、tensorflow 1.0 学习:参数初始化(initializer)
CNN中最重要的就是参数了,包括W,b。 我们训练CNN的最终目的就是得到最好的参数,使得目标函数取得最小值。参数的初始化也同样重要,因此微调受到很多人的重视,那么tf提供了哪些初始化参数的方法呢,我们能不能自己进行初始化呢?
所有的初始化方法都定义在tensorflow/python/ops/init_ops.py
1、tf.constant_initializer()
也可以简写为tf.Constant()
初始化为常数,这个非常有用,通常偏置项就是用它初始化的。
由它衍生出的两个初始化方法:
a、 tf.zeros_initializer(), 也可以简写为tf.Zeros()
b、tf.ones_initializer(), 也可以简写为tf.Ones()
例:在卷积层中,将偏置项b初始化为0,则有多种写法:
conv1 = tf.layers.conv2d(batch_images,
filters=64,
kernel_size=7,
strides=2,
activation=tf.nn.relu,
kernel_initializer=tf.TruncatedNormal(stddev=0.01)
bias_initializer=tf.Constant(0),
)
或者:
bias_initializer=tf.constant_initializer(0)
或者:
bias_initializer=tf.zeros_initializer()
或者:
bias_initializer=tf.Zeros()
例:如何将W初始化成拉普拉斯算子?
value = [1, 1, 1, 1, -8, 1, 1, 1,1] init = tf.constant_initializer(value) W= tf.get_variable(‘W‘, shape=[3, 3], initializer=init)
2、tf.truncated_normal_initializer()
或者简写为tf.TruncatedNormal()
生成截断正态分布的随机数,这个初始化方法好像在tf中用得比较多。
它有四个参数(mean=0.0, stddev=1.0, seed=None, dtype=dtypes.float32),分别用于指定均值、标准差、随机数种子和随机数的数据类型,一般只需要设置stddev这一个参数就可以了。
例:
conv1 = tf.layers.conv2d(batch_images,
filters=64,
kernel_size=7,
strides=2,
activation=tf.nn.relu,
kernel_initializer=tf.TruncatedNormal(stddev=0.01)
bias_initializer=tf.Constant(0),
)
或者:
conv1 = tf.layers.conv2d(batch_images,
filters=64,
kernel_size=7,
strides=2,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01)
bias_initializer=tf.zero_initializer(),
)
3、tf.random_normal_initializer()
可简写为 tf.RandomNormal()
生成标准正态分布的随机数,参数和truncated_normal_initializer一样。
4、random_uniform_initializer = RandomUniform()
可简写为tf.RandomUniform()
生成均匀分布的随机数,参数有四个(minval=0, maxval=None, seed=None, dtype=dtypes.float32),分别用于指定最小值,最大值,随机数种子和类型。
5、tf.uniform_unit_scaling_initializer()
可简写为tf.UniformUnitScaling()
和均匀分布差不多,只是这个初始化方法不需要指定最小最大值,是通过计算出来的。参数为(factor=1.0, seed=None, dtype=dtypes.float32)
max_val = math.sqrt(3 / input_size) * factor
这里的input_size是指输入数据的维数,假设输入为x, 运算为x * W,则input_size= W.shape[0]
它的分布区间为[ -max_val, max_val]
6、tf.variance_scaling_initializer()
可简写为tf.VarianceScaling()
参数为(scale=1.0,mode="fan_in",distribution="normal",seed=None,dtype=dtypes.float32)
scale: 缩放尺度(正浮点数)
mode: "fan_in", "fan_out", "fan_avg"中的一个,用于计算标准差stddev的值。
distribution:分布类型,"normal"或“uniform"中的一个。
当 distribution="normal" 的时候,生成truncated normal distribution(截断正态分布) 的随机数,其中stddev = sqrt(scale / n) ,n的计算与mode参数有关。
如果mode = "fan_in", n为输入单元的结点数;
如果mode = "fan_out",n为输出单元的结点数;
如果mode = "fan_avg",n为输入和输出单元结点数的平均值。
当distribution="uniform”的时候 ,生成均匀分布的随机数,假设分布区间为[-limit, limit],则
limit = sqrt(3 * scale / n)
7、tf.orthogonal_initializer()
简写为tf.Orthogonal()
生成正交矩阵的随机数。
当需要生成的参数是2维时,这个正交矩阵是由均匀分布的随机数矩阵经过SVD分解而来。
8、tf.glorot_uniform_initializer()
也称之为Xavier uniform initializer,由一个均匀分布(uniform distribution)来初始化数据。
假设均匀分布的区间是[-limit, limit],则
limit=sqrt(6 / (fan_in + fan_out))
其中的fan_in和fan_out分别表示输入单元的结点数和输出单元的结点数。
9、glorot_normal_initializer()
也称之为 Xavier normal initializer. 由一个 truncated normal distribution来初始化数据.
stddev = sqrt(2 / (fan_in + fan_out))
其中的fan_in和fan_out分别表示输入单元的结点数和输出单元的结点数。
九、tensorflow 1.0 学习:池化层(pooling)和全连接层(dense)
池化层定义在 tensorflow/python/layers/pooling.py.
有最大值池化和均值池化。
1、tf.layers.max_pooling2d
max_pooling2d(
inputs,
pool_size,
strides,
padding=‘valid‘,
data_format=‘channels_last‘,
name=None
)
inputs: 进行池化的数据。pool_size: 池化的核大小(pool_height, pool_width),如[3,3]. 如果长宽相等,也可以直接设置为一个数,如pool_size=3.strides: 池化的滑动步长。可以设置为[1,1]这样的两个整数. 也可以直接设置为一个数,如strides=2padding: 边缘填充,‘same‘ 和‘valid‘选其一。默认为validdata_format: 输入数据格式,默认为channels_last,即(batch, height, width, channels),也可以设置为channels_first对应(batch, channels, height, width).name: 层的名字。
例:
pool1=tf.layers.max_pooling2d(inputs=x, pool_size=[2, 2], strides=2)
一般是放在卷积层之后,如:
conv=tf.layers.conv2d(
inputs=x,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool=tf.layers.max_pooling2d(inputs=conv, pool_size=[2, 2], strides=2)
2.tf.layers.average_pooling2d
average_pooling2d(
inputs,
pool_size,
strides,
padding=‘valid‘,
data_format=‘channels_last‘,
name=None
)
参数和前面的最大值池化一样。
全连接dense层定义在 tensorflow/python/layers/core.py.
3、tf.layers.dense
dense(
inputs,
units,
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
trainable=True,
name=None,
reuse=None
)
inputs: 输入数据,2维tensor.units: 该层的神经单元结点数。activation: 激活函数.use_bias: Boolean型,是否使用偏置项.kernel_initializer: 卷积核的初始化器.bias_initializer: 偏置项的初始化器,默认初始化为0.kernel_regularizer: 卷积核化的正则化,可选.bias_regularizer: 偏置项的正则化,可选.activity_regularizer: 输出的正则化函数.trainable: Boolean型,表明该层的参数是否参与训练。如果为真则变量加入到图集合中GraphKeys.TRAINABLE_VARIABLES(seetf.Variable).name: 层的名字.reuse: Boolean型, 是否重复使用参数.
全连接层执行操作 outputs = activation(inputs.kernel + bias)
如果执行结果不想进行激活操作,则设置activation=None。
例:
#全连接层 dense1 = tf.layers.dense(inputs=pool3, units=1024, activation=tf.nn.relu) dense2= tf.layers.dense(inputs=dense1, units=512, activation=tf.nn.relu) logits= tf.layers.dense(inputs=dense2, units=10, activation=None)
也可以对全连接层的参数进行正则化约束:
dense1 = tf.layers.dense(inputs=pool3, units=1024, activation=tf.nn.relu,kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
十、tensorflow 1.0 学习:参数和特征的提取
在tf中,参与训练的参数可用 tf.trainable_variables()提取出来,如:
#取出所有参与训练的参数
params=tf.trainable_variables()
print("Trainable variables:------------------------")
#循环列出参数
for idx, v in enumerate(params):
print(" param {:3}: {:15} {}".format(idx, str(v.get_shape()), v.name))
这里只能查看参数的shape和name,并没有具体的值。如果要查看参数具体的值的话,必须先初始化,即:
sess=tf.Session() sess.run(tf.global_variables_initializer())
同理,我们也可以提取图片经过训练后的值。图片经过卷积后变成了特征,要提取这些特征,必须先把图片feed进去。
具体看实例:
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 3 12:07:59 2017
@author: Administrator
"""
import tensorflow as tf
from skimage import io,transform
import numpy as np
#-----------------构建网络----------------------
#占位符
x=tf.placeholder(tf.float32,shape=[None,100,100,3],name=‘x‘)
y_=tf.placeholder(tf.int32,shape=[None,],name=‘y_‘)
#第一个卷积层(100——>50)
conv1=tf.layers.conv2d(
inputs=x,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool1=tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
#第二个卷积层(50->25)
conv2=tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool2=tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
#第三个卷积层(25->12)
conv3=tf.layers.conv2d(
inputs=pool2,
filters=128,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool3=tf.layers.max_pooling2d(inputs=conv3, pool_size=[2, 2], strides=2)
#第四个卷积层(12->6)
conv4=tf.layers.conv2d(
inputs=pool3,
filters=128,
kernel_size=[3, 3],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
pool4=tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=2)
re1 = tf.reshape(pool4, [-1, 6 * 6 * 128])
#全连接层
dense1 = tf.layers.dense(inputs=re1,
units=1024,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
dense2= tf.layers.dense(inputs=dense1,
units=512,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
logits= tf.layers.dense(inputs=dense2,
units=5,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
#---------------------------网络结束---------------------------
#%%
#取出所有参与训练的参数
params=tf.trainable_variables()
print("Trainable variables:------------------------")
#循环列出参数
for idx, v in enumerate(params):
print(" param {:3}: {:15} {}".format(idx, str(v.get_shape()), v.name))
#%%
#读取图片
img=io.imread(‘d:/cat.jpg‘)
#resize成100*100
img=transform.resize(img,(100,100))
#三维变四维(100,100,3)-->(1,100,100,3)
img=img[np.newaxis,:,:,:]
img=np.asarray(img,np.float32)
sess=tf.Session()
sess.run(tf.global_variables_initializer())
#提取最后一个全连接层的参数 W和b
W=sess.run(params[26])
b=sess.run(params[27])
#提取第二个全连接层的输出值作为特征
fea=sess.run(dense2,feed_dict={x:img})
最后一条语句就是提取某层的数据输出作为特征。
注意:这个程序并没有经过训练,因此提取出的参数只是初始化的参数。
十一、tensorflow 1.0 学习:模型的保存与恢复(Saver)
将训练好的模型参数保存起来,以便以后进行验证或测试,这是我们经常要做的事情。tf里面提供模型保存的是tf.train.Saver()模块。
模型保存,先要创建一个Saver对象:如
saver=tf.train.Saver()
在创建这个Saver对象的时候,有一个参数我们经常会用到,就是 max_to_keep 参数,这个是用来设置保存模型的个数,默认为5,即 max_to_keep=5,保存最近的5个模型。如果你想每训练一代(epoch)就想保存一次模型,则可以将 max_to_keep设置为None或者0,如:
saver=tf.train.Saver(max_to_keep=0)
但是这样做除了多占用硬盘,并没有实际多大的用处,因此不推荐。
当然,如果你只想保存最后一代的模型,则只需要将max_to_keep设置为1即可,即
saver=tf.train.Saver(max_to_keep=1)
创建完saver对象后,就可以保存训练好的模型了,如:
saver.save(sess,‘ckpt/mnist.ckpt‘,global_step=step)
第一个参数sess,这个就不用说了。第二个参数设定保存的路径和名字,第三个参数将训练的次数作为后缀加入到模型名字中。
saver.save(sess, ‘my-model‘, global_step=0) ==> filename: ‘my-model-0‘
...
saver.save(sess, ‘my-model‘, global_step=1000) ==> filename: ‘my-model-1000‘
看一个mnist实例:
# -*- coding: utf-8 -*-
"""
Created on Sun Jun 4 10:29:48 2017
@author: Administrator
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
x = tf.placeholder(tf.float32, [None, 784])
y_=tf.placeholder(tf.int32,[None,])
dense1 = tf.layers.dense(inputs=x,
units=1024,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
dense2= tf.layers.dense(inputs=dense1,
units=512,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
logits= tf.layers.dense(inputs=dense2,
units=10,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
loss=tf.losses.sparse_softmax_cross_entropy(labels=y_,logits=logits)
train_op=tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(logits,1),tf.int32), y_)
acc= tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver=tf.train.Saver(max_to_keep=1)
for i in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_op, feed_dict={x: batch_xs, y_: batch_ys})
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print(‘epoch:%d, val_loss:%f, val_acc:%f‘%(i,val_loss,val_acc))
saver.save(sess,‘ckpt/mnist.ckpt‘,global_step=i+1)
sess.close()
代码中红色部分就是保存模型的代码,虽然我在每训练完一代的时候,都进行了保存,但后一次保存的模型会覆盖前一次的,最终只会保存最后一次。因此我们可以节省时间,将保存代码放到循环之外(仅适用max_to_keep=1,否则还是需要放在循环内).
在实验中,最后一代可能并不是验证精度最高的一代,因此我们并不想默认保存最后一代,而是想保存验证精度最高的一代,则加个中间变量和判断语句就可以了。
saver=tf.train.Saver(max_to_keep=1)
max_acc=0
for i in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_op, feed_dict={x: batch_xs, y_: batch_ys})
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print(‘epoch:%d, val_loss:%f, val_acc:%f‘%(i,val_loss,val_acc))
if val_acc>max_acc:
max_acc=val_acc
saver.save(sess,‘ckpt/mnist.ckpt‘,global_step=i+1)
sess.close()
如果我们想保存验证精度最高的三代,且把每次的验证精度也随之保存下来,则我们可以生成一个txt文件用于保存。
saver=tf.train.Saver(max_to_keep=3)
max_acc=0
f=open(‘ckpt/acc.txt‘,‘w‘)
for i in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_op, feed_dict={x: batch_xs, y_: batch_ys})
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print(‘epoch:%d, val_loss:%f, val_acc:%f‘%(i,val_loss,val_acc))
f.write(str(i+1)+‘, val_acc: ‘+str(val_acc)+‘\n‘)
if val_acc>max_acc:
max_acc=val_acc
saver.save(sess,‘ckpt/mnist.ckpt‘,global_step=i+1)
f.close()
sess.close()
模型的恢复用的是restore()函数,它需要两个参数restore(sess, save_path),save_path指的是保存的模型路径。我们可以使用tf.train.latest_checkpoint()来自动获取最后一次保存的模型。如:
model_file=tf.train.latest_checkpoint(‘ckpt/‘) saver.restore(sess,model_file)
则程序后半段代码我们可以改为:
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
is_train=False
saver=tf.train.Saver(max_to_keep=3)
#训练阶段
if is_train:
max_acc=0
f=open(‘ckpt/acc.txt‘,‘w‘)
for i in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_op, feed_dict={x: batch_xs, y_: batch_ys})
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print(‘epoch:%d, val_loss:%f, val_acc:%f‘%(i,val_loss,val_acc))
f.write(str(i+1)+‘, val_acc: ‘+str(val_acc)+‘\n‘)
if val_acc>max_acc:
max_acc=val_acc
saver.save(sess,‘ckpt/mnist.ckpt‘,global_step=i+1)
f.close()
#验证阶段
else:
model_file=tf.train.latest_checkpoint(‘ckpt/‘)
saver.restore(sess,model_file)
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print(‘val_loss:%f, val_acc:%f‘%(val_loss,val_acc))
sess.close()
标红的地方,就是与保存、恢复模型相关的代码。用一个bool型变量is_train来控制训练和验证两个阶段。
整个源程序:
# -*- coding: utf-8 -*- """ Created on Sun Jun 4 10:29:48 2017 @author: Administrator """ import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=False) x = tf.placeholder(tf.float32, [None, 784]) y_=tf.placeholder(tf.int32,[None,]) dense1 = tf.layers.dense(inputs=x, units=1024, activation=tf.nn.relu, kernel_initializer=tf.truncated_normal_initializer(stddev=0.01), kernel_regularizer=tf.nn.l2_loss) dense2= tf.layers.dense(inputs=dense1, units=512, activation=tf.nn.relu, kernel_initializer=tf.truncated_normal_initializer(stddev=0.01), kernel_regularizer=tf.nn.l2_loss) logits= tf.layers.dense(inputs=dense2, units=10, activation=None, kernel_initializer=tf.truncated_normal_initializer(stddev=0.01), kernel_regularizer=tf.nn.l2_loss) loss=tf.losses.sparse_softmax_cross_entropy(labels=y_,logits=logits) train_op=tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) correct_prediction = tf.equal(tf.cast(tf.argmax(logits,1),tf.int32), y_) acc= tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) sess=tf.InteractiveSession() sess.run(tf.global_variables_initializer()) is_train=True saver=tf.train.Saver(max_to_keep=3) #训练阶段 if is_train: max_acc=0 f=open(‘ckpt/acc.txt‘,‘w‘) for i in range(100): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_op, feed_dict={x: batch_xs, y_: batch_ys}) val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels}) print(‘epoch:%d, val_loss:%f, val_acc:%f‘%(i,val_loss,val_acc)) f.write(str(i+1)+‘, val_acc: ‘+str(val_acc)+‘\n‘) if val_acc>max_acc: max_acc=val_acc saver.save(sess,‘ckpt/mnist.ckpt‘,global_step=i+1) f.close() #验证阶段 else: model_file=tf.train.latest_checkpoint(‘ckpt/‘) saver.restore(sess,model_file) val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels}) print(‘val_loss:%f, val_acc:%f‘%(val_loss,val_acc)) sess.close()
参考文章:http://blog.csdn.net/u011500062/article/details/51728830
十二、tensorflow 1.0 学习:用别人训练好的模型来进行图像分类
谷歌在大型图像数据库ImageNet上训练好了一个Inception-v3模型,这个模型我们可以直接用来进来图像分类。
下载地址:https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
下载完解压后,得到几个文件:
其中的classify_image_graph_def.pb 文件就是训练好的Inception-v3模型。
imagenet_synset_to_human_label_map.txt是类别文件。
随机找一张图片:如

对这张图片进行识别,看它属于什么类?
代码如下:先创建一个类NodeLookup来将softmax概率值映射到标签上。
然后创建一个函数create_graph()来读取模型。
最后读取图片进行分类识别:
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import re
import os
model_dir=‘D:/tf/model/‘
image=‘d:/cat.jpg‘
#将类别ID转换为人类易读的标签
class NodeLookup(object):
def __init__(self,
label_lookup_path=None,
uid_lookup_path=None):
if not label_lookup_path:
label_lookup_path = os.path.join(
model_dir, ‘imagenet_2012_challenge_label_map_proto.pbtxt‘)
if not uid_lookup_path:
uid_lookup_path = os.path.join(
model_dir, ‘imagenet_synset_to_human_label_map.txt‘)
self.node_lookup = self.load(label_lookup_path, uid_lookup_path)
def load(self, label_lookup_path, uid_lookup_path):
if not tf.gfile.Exists(uid_lookup_path):
tf.logging.fatal(‘File does not exist %s‘, uid_lookup_path)
if not tf.gfile.Exists(label_lookup_path):
tf.logging.fatal(‘File does not exist %s‘, label_lookup_path)
# Loads mapping from string UID to human-readable string
proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines()
uid_to_human = {}
p = re.compile(r‘[n\d]*[ \S,]*‘)
for line in proto_as_ascii_lines:
parsed_items = p.findall(line)
uid = parsed_items[0]
human_string = parsed_items[2]
uid_to_human[uid] = human_string
# Loads mapping from string UID to integer node ID.
node_id_to_uid = {}
proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines()
for line in proto_as_ascii:
if line.startswith(‘ target_class:‘):
target_class = int(line.split(‘: ‘)[1])
if line.startswith(‘ target_class_string:‘):
target_class_string = line.split(‘: ‘)[1]
node_id_to_uid[target_class] = target_class_string[1:-2]
# Loads the final mapping of integer node ID to human-readable string
node_id_to_name = {}
for key, val in node_id_to_uid.items():
if val not in uid_to_human:
tf.logging.fatal(‘Failed to locate: %s‘, val)
name = uid_to_human[val]
node_id_to_name[key] = name
return node_id_to_name
def id_to_string(self, node_id):
if node_id not in self.node_lookup:
return ‘‘
return self.node_lookup[node_id]
#读取训练好的Inception-v3模型来创建graph
def create_graph():
with tf.gfile.FastGFile(os.path.join(
model_dir, ‘classify_image_graph_def.pb‘), ‘rb‘) as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name=‘‘)
#读取图片
image_data = tf.gfile.FastGFile(image, ‘rb‘).read()
#创建graph
create_graph()
sess=tf.Session()
#Inception-v3模型的最后一层softmax的输出
softmax_tensor= sess.graph.get_tensor_by_name(‘softmax:0‘)
#输入图像数据,得到softmax概率值(一个shape=(1,1008)的向量)
predictions = sess.run(softmax_tensor,{‘DecodeJpeg/contents:0‘: image_data})
#(1,1008)->(1008,)
predictions = np.squeeze(predictions)
# ID --> English string label.
node_lookup = NodeLookup()
#取出前5个概率最大的值(top-5)
top_5 = predictions.argsort()[-5:][::-1]
for node_id in top_5:
human_string = node_lookup.id_to_string(node_id)
score = predictions[node_id]
print(‘%s (score = %.5f)‘ % (human_string, score))
sess.close()
最后输出:
tiger cat (score = 0.40316)
Egyptian cat (score = 0.21686)
tabby, tabby cat (score = 0.21348)
lynx, catamount (score = 0.01403)
Persian cat (score = 0.00394)
十三、tensorflow 1.0 学习:十图详解tensorflow数据读取机制
本文转自:https://zhuanlan.zhihu.com/p/27238630
在学习tensorflow的过程中,有很多小伙伴反映读取数据这一块很难理解。确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料。今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下tensorflow的数据读取机制,文章的最后还会给出实战代码以供参考。
一、tensorflow读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
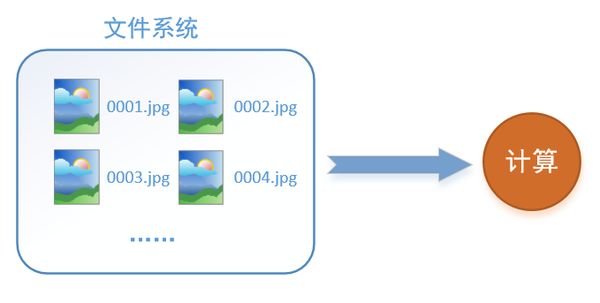
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
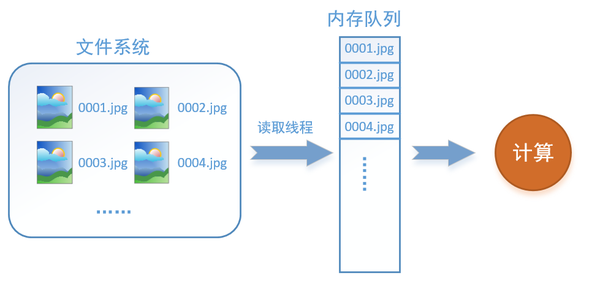
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
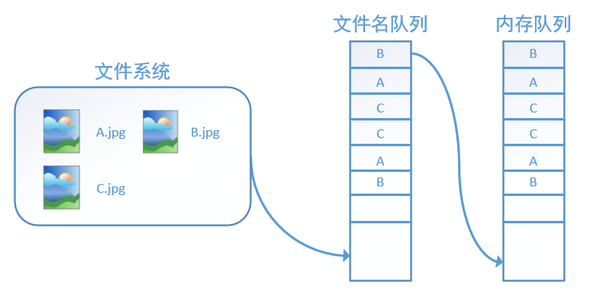
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。
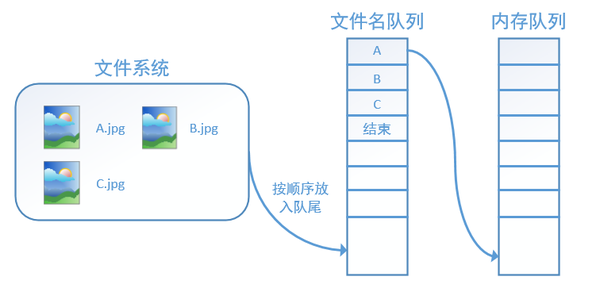
程序运行后,内存队列首先读入A(此时A从文件名队列中出队):
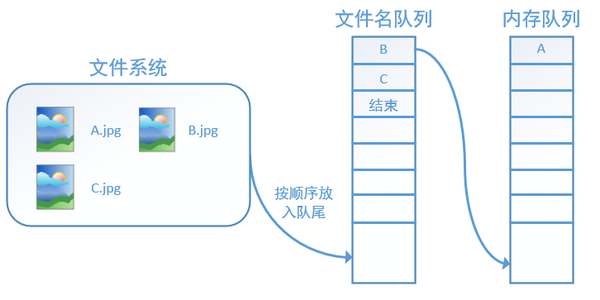
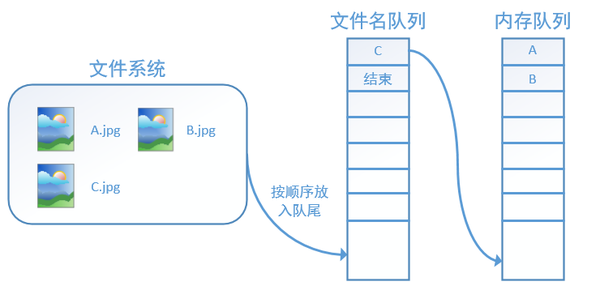
再依次读入B和C:
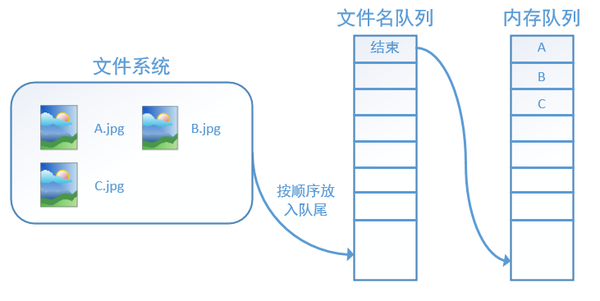
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
二、tensorflow读取数据机制的对应函数
如何在tensorflow中创建上述的两个队列呢?
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
此外tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变:
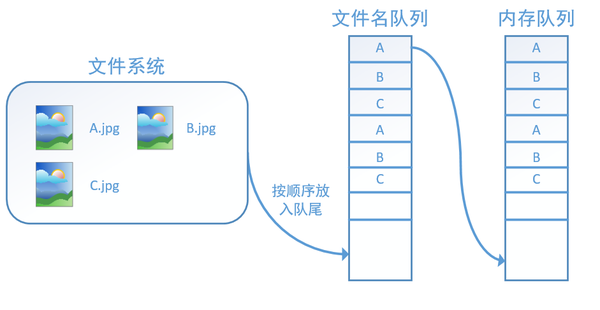
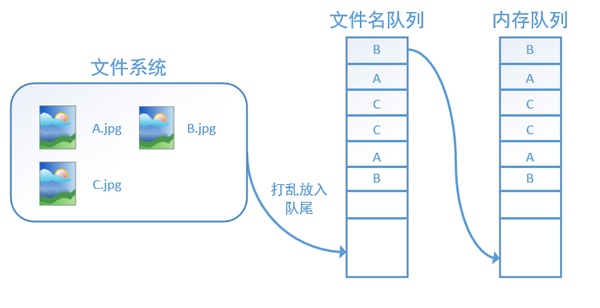
如果设置shuffle=True,那么在一个epoch内,数据的前后顺序就会被打乱,如下图所示:
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了,具体实现可以参考下面的实战代码。
除了tf.train.string_input_producer外,我们还要额外介绍一个函数:tf.train.start_queue_runners。初学者会经常在代码中看到这个函数,但往往很难理解它的用处,在这里,有了上面的铺垫后,我们就可以解释这个函数的作用了。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。
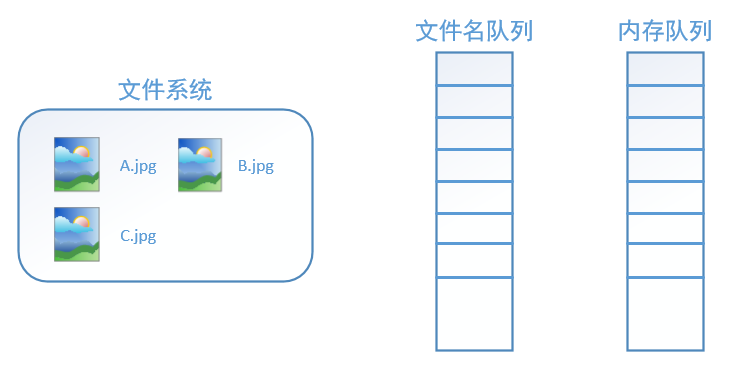
而使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了,这就是函数tf.train.start_queue_runners的用处。
三、实战代码
我们用一个具体的例子感受tensorflow中的数据读取。如图,假设我们在当前文件夹中已经有A.jpg、B.jpg、C.jpg三张图片,我们希望读取这三张图片5个epoch并且把读取的结果重新存到read文件夹中。

对应的代码如下:
# 导入tensorflow
import tensorflow as tf
# 新建一个Session
with tf.Session() as sess:
# 我们要读三幅图片A.jpg, B.jpg, C.jpg
filename = [‘A.jpg‘, ‘B.jpg‘, ‘C.jpg‘]
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader从文件名队列中读数据。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之后,才会开始填充队列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 获取图片数据并保存
image_data = sess.run(value)
with open(‘read/test_%d.jpg‘ % i, ‘wb‘) as f:
f.write(image_data)
我们这里使用filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)建立了一个会跑5个epoch的文件名队列。并使用reader读取,reader每次读取一张图片并保存。
运行代码后,我们得到就可以看到read文件夹中的图片,正好是按顺序的5个epoch:

如果我们设置filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的shuffle=True,那么在每个epoch内图像就会被打乱,如图所示:

我们这里只是用三张图片举例,实际应用中一个数据集肯定不止3张图片,不过涉及到的原理都是共通的。